







由于Spark并没有相应的文件系统,因此需要先安装HDFS。本文简单的实现了Hadoop2.6.0的环境搭建。
安装操作系统及其注意事项
本文使用的操作系统是ubuntu15.04,是安装在VMware vSphere上的,其中会遇到一些奇怪的问题。
1.在安装系统的时候,需要先将网络Disable,否则有可能不能安装系统。
2.系统安装完成后,调整IP以及DNS地址,界面操作即可完成。
3.为了免去以后的麻烦,可以设置root用户登录,具体操作如下:
打开终端/etc/lightdm文件夹,新建Lightdm.conf,写入如下内容。
[SeatDefault]
autolgoin-guest=false
autologin-user=root
autologin-user-timeout=0
autologin-session=lightdm-autologin
greeter-show-manual-login=true
allow-guest=false
这样做之后重启,会出现stdin is not a tty这个问题,鼠标变成了X的样子,这个时候需要使用gedit进入/root/.profile中,将“mesg n”修改为“tty -s && mesg n”即可。
4.使用gedit进入/etc/hostname,修改主机名。
5.使用gedit进入/etc/hosts,修改IP和主机名映射。
上传文件以及部分环境安装
1.由于vSphere中安装的Linux较难安装VMware Tools,因此需要使用FileZilla上传下载文件,这需要系统中安装OpenSSH。打开控制台,输入apt-get install openssh-server即可。
2.将下载好的文件(Java,Hadoop,Scala,Spark等)上传到系统中(或直接在ubuntu系统中下载),使用的协议是sftp,注意这个时候连接使用的用户名密码是管理员用户的(安装系统时候设置的用户),使用root用户是无法建立连接的。
3.解压Java和Hadoop,并将环境变量写入~/.bashrc和/etc/profile中,内容如下:
~/.bashrc
export JAVA_HOME=/usr/lib/java/jdk1.8.0_73
export JRE_HOME=${JAVA_HOME}/jre
export SCALA_HOME=/usr/lib/scala/scala-2.10.4
export CLASS_PASS=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0
export PATH=${JAVA_HOME}/bin:/usr/local/hadoop/hadoop-2.6.0/bin:/usr/local/hadoop/hadoop-2.6.0/sbin:${SCALA_HOME}/bin:$PATH
/etc/profile
export JAVA_HOME=/usr/lib/java/jdk1.8.0_73
export JRE_HOME=${JAVA_HOME}/jre
export SCALA_HOME=/usr/lib/scala/scala-2.10.4
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=${JAVA_HOME}/bin:/usr/local/hadoop/hadoop-2.6.0/bin:/usr/local/hadoop/hadoop-2.6.0/sbin:${SCALA_HOME}/bin:$PATH
export CLASSPATH=$CLASSPATH:.:JAVA_HOME/lib:$JAVA_HOME/jre/lib
4.使用source命令更新~/.bashrc和/etc/profile,使其不用重启即可生效。
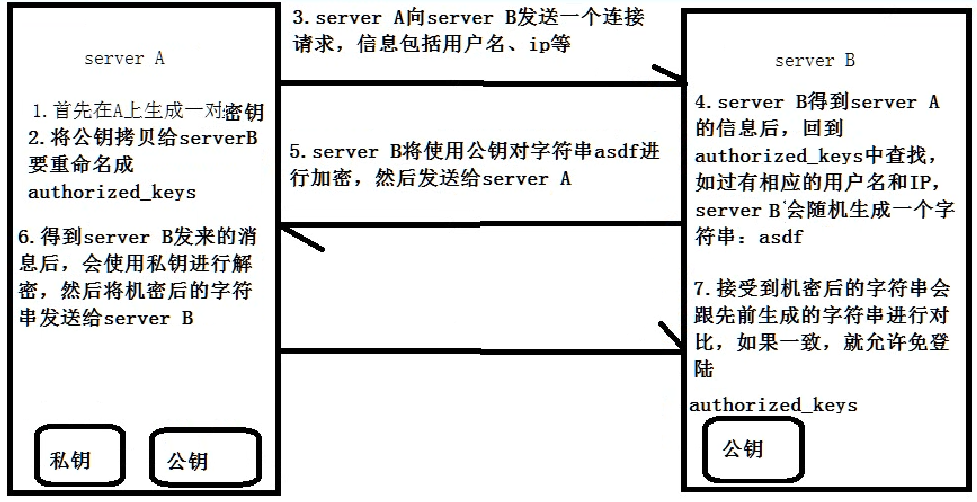
5.配置ssh免密码登录,需要执行的命令如下:
ssh-keygen –t rsa –P
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh的原理图如下
Hadoop的设置
1.首先在修改hadoop-env.sh声明jdk路径,位置在。。。
修改内容如下
export JAVA_HOME=/usr/lib/java/jdk1.8.0_73
2.修改core-site.xml,主要指定HDFS中namenode的通信地址
<configuration>
<property>
<!--namenode的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://172.18.128.192:9000</value>
</property>
<property>
<!--临时文件地址-->
<name>hadoop.tmp.dir</name>
<value>/opt/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>3.修改hdfs-site.xml,主要设置HDFS中文件的副本数
<configuration>
<property>
<!--hdfs副本数-->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>4.将mapred-site.xml.template 重命名为mapred-site.xml,主要设置框架MapReduce使用YARN
<configuration>
<property>
<!--MR使用YARN进行调度-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5.修改yarn-site.xml,主要设置Reducer取数据的方式是mapreduce_shuffle
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!--reducer取数据的方式是mapreduce_shuffle-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!--yarn resourcemanager host-->
<name>yarn.resourcemanager.hostname</name>
<value>172.18.128.192</value>
</property>
</configuration>6.第一次使用的时候需要格式化HDFS,即在终端中输入“hadoop namenode -format”
这个时候Hadoop的设置应该完成了,可以使用start-all.sh命令启动Hadoop,完成后输入jps,如果出现如下内容即可验证是否成功设置
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









