







1.k-近邻算法概念
k-近邻算法主要原理:假设有一个样本集,并且知道数据的类别,对于一个新来的数据,通过计算新数据与已知样本集数据的距离,距离越近越相似。选出k个最相似的数据,在这k个数据中,出现最多的类别作为新数据的类别。
2.code
代码实现:
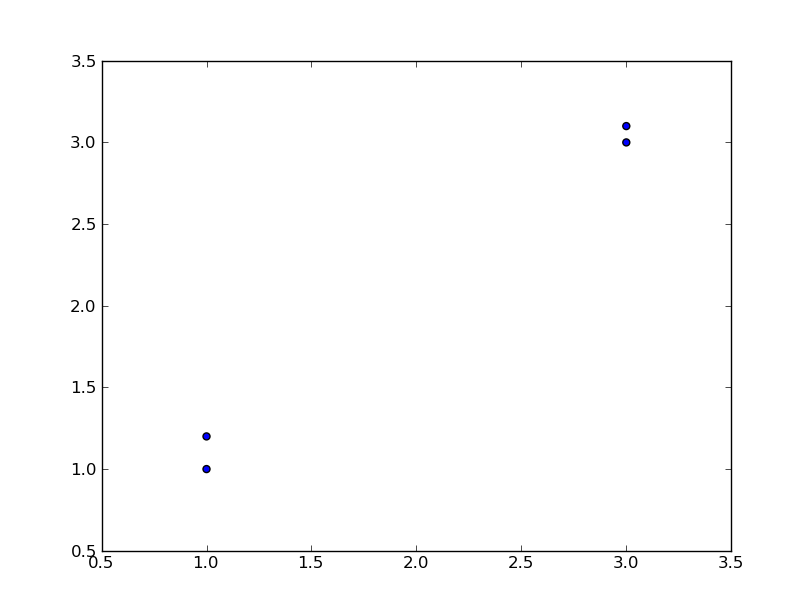
- 现有a,b类别的数据点
a1=(1,1),a2=(1,1.2),b1=(3,3),b2=(3,3.1)- 对于新的数据点 (1,1.3) 计算其与各个点的距离。
- 距离计算公式 l=(1−1)2+(1−1.3)2−−−−−−−−−−−−−−−−√2
- 计算与所有点的距离,得到最近的k个点。
- k个点中类别出现最多的,即为新数据点的类别
def createDataSet():
arr=array([[1.0,1.0],[1.0,1.2],[3,3],[3,3.1]])
labels=['A','A','B','B']
return arr,labels
def classify0(inx,dataSet,labels,k):
datanum=dataSet.shape[0]
inxtemp=tile(inx,(datanum,1))-dataSet #矩阵相减
sqinxtemp=inxtemp**2
sqdistance=sqinxtemp.sum(axis=1)
distance=sqdistance**0.5
sortdist=distance.argsort()
classset={}
for i in range(k):
labeltemp = labels[sortdist[i]]
classset[labeltemp]=classset.get(labeltemp,0)+1
sortedclassset=sorted(classset.iteritems(),key=lambda d:d[1],reverse=True)#对不同类别出现的次数排序
return sortedclassset[0][0]
3.end
参考:《机器学习实战》















 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









