







1.简述
关于huggingface介绍,请参考其他文章,这里简单说明。
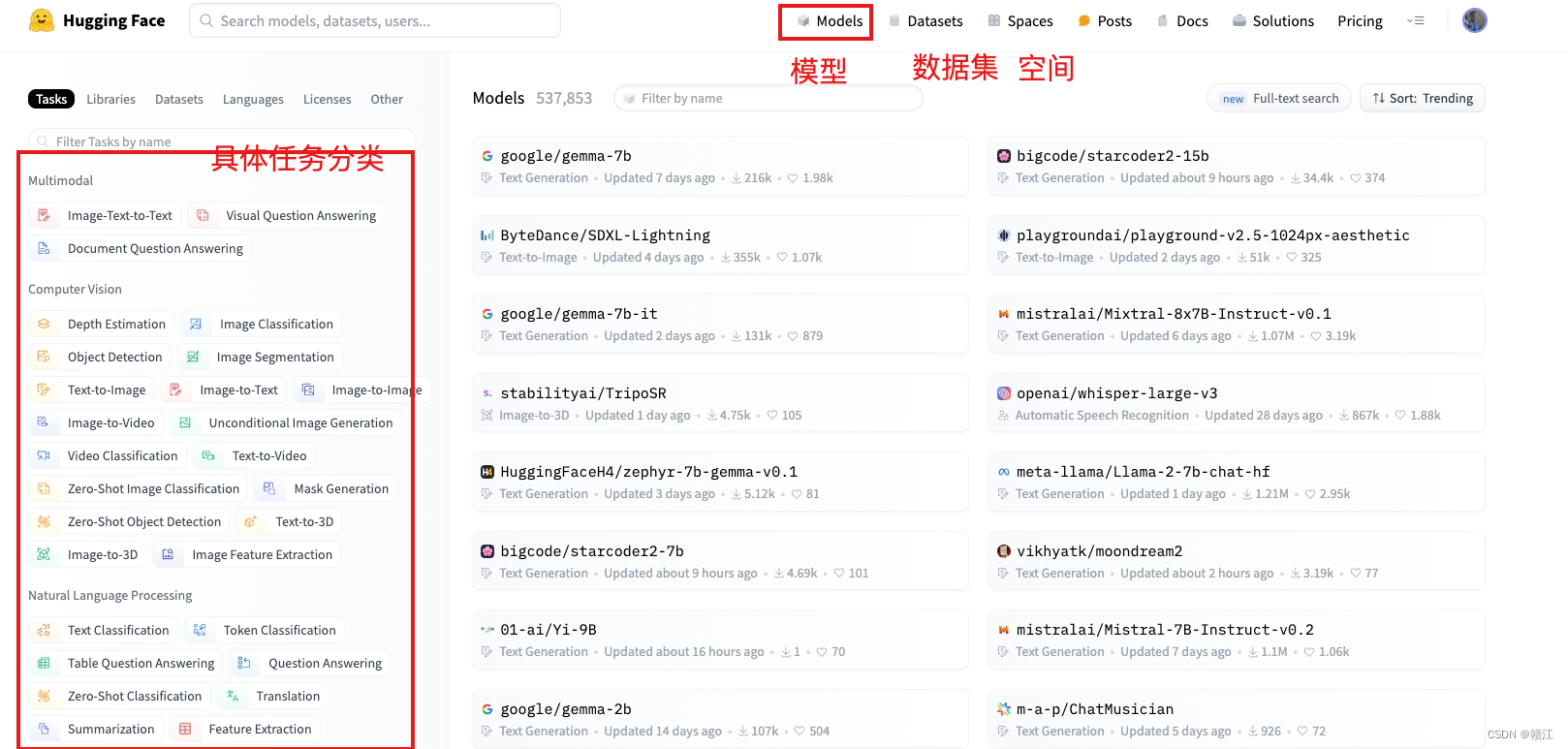
Tasks:主要包括计算机视觉、自然语言处理、语音处理、多模态、表格处理、强化学习、图机器学习。
- Multimodal多模态:Visual Question Answering(视觉问答,VQA),document-question-answering(文档问答),image-text-to-text(图像文本)
- Computer Vision(计算机视觉任务):包括lmage Classification(图像分类),lmage Segmentation(图像分割)、zero-Shot lmage Classification(零样本图像分类)、lmage-to-Image(图像到图像的任务)、Unconditional lmage Generation(无条件图像生成)、Object Detection(目标检测)、Video Classification(视频分类)、Depth Estimation(深度估计,估计拍摄者距离图像各处的距离)
- Natural Language Processing(自然语言处理):包括Translation(机器翻译)、Fill-Mask(填充掩码,预测句子中被遮掩的词)、Token Classification(词分类)、Sentence Similarity(句子相似度)、Question Answering(问答系统),Summarization(总结,缩句)、Zero-Shot Classification (零样本分类)、Text Classification(文本分类)、Text2Text(文本到文本的生成)、Text Generation(文本生成)、Conversational(聊天)、Table Question Answer(表问答,1.预测表格中被遮掩单词2.数字推理,判断句子是否被表格数据支持)
- Audio(语音):Automatic Speech Recognition(语音识别)、Audio Classification(语音分类)、Text-to-Speech(文本到语音的生成)、Audio-to-Audio(语音到语音的生成)、Voice Activity Detection(声音检测、检测识别出需要的声音部分)
- Multimodal(多模态):Feature Extraction(特征提取)、Text-to-Image(文本到图像)、Visual Question Answering(视觉问答)、Image2Text(图像到文本)、Document Question Answering(文档问答)
- Tabular(表格):Tabular Classification(表分类)、Tabular Regression(表回归)
- Reinforcement Learning(强化学习):Reinforcement Learning(强化学习)、Robotics(机器人)
- 其他:graph machine learning图机器学习
2.模型名称说明
- 任务-架构: 可以使用任务名称和架构名称的组合来命名模型。例如,"Sentiment-BERT"表示用于情感分析任务的BERT模型。
- 数据集-架构: 使用数据集名称和架构名称的组合来命名模型。例如,"IMDB-BERT"表示在IMDB电影评论数据集上使用的BERT模型。
- 架构-规模: 使用架构名称和规模描述来命名模型,表明模型的大小或参数量级。例如,"DistilBERT-large"表示较大规模的DistilBERT模型。
- 领域-任务-架构: 在特定领域下,使用领域名称、任务名称和架构名称的组合来命名模型。例如,"Medical-NER-BERT"表示在医学领域进行实体识别任务的BERT模型。
- 架构-日期版本: 使用架构名称和日期版本来命名模型,以指示模型的特定版本。例如,"BERT-base-v2"表示BERT模型的第二个版本。
很多模型使用的名称后缀如:Chinese-LLaMA-7B 其中"7B" 表示模型的规模或大小。通常,这种命名约定是基于模型所具有的参数量级。
3.NLP常见指标
以下是一些常见的NLP(自然语言处理)评估指标及其含义:
- ARC(AI2 Reasoning Challenge):由Allen Institute for AI提供的挑战,旨在测试模型对推理和常识推断的理解能力。
- HellaSwag:这是一个用于衡量模型理解复杂、反直觉句子的数据集和评估指标。
- MMLU(Mean Message Length Unit):用于对话系统评估的指标,表示生成的回复平均包含的单词数量。
- Truthful QA:评估模型是否能够正确回答问题,不论其是否具有故意误导性。
- Winogrande:这是一个依赖上下文的问答数据集,用于评估模型在推理、常识和共指方面的能力。
- GSM8K(Google Semantic Textual Similarity 8K):用于衡量文本相似性的任务和数据集。
- C-Eval:用于对话系统评估的指标之一,通过比较生成回复与人类参考回复之间的相似性来衡量生成回复的质量。
4.实践
安装:
pip install torch torchvision
pip install transformers执行代码:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
output = classifier("Today is a nice day")5.报错及解决
1.OMP: Error #15: Initializing libomp.dylib, but found libiomp5.dylib already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see Support for the OpenMP language
解决办法:网上很多人推荐
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'确实能解决部分人的问题,但是依旧有部分人出现在mac下可能没有任何打印,其实这个大概率是numpy版本问题导致,解决办法:先删除conda uninstall numpy,然后再安装一遍。
2.No model was supplied, defaulted to distilbert/distilbert-base-uncased-finetuned-sst-2-english and revision af0f99b (https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english).
Using a pipeline without specifying a model name and revision in production is not recommended.
但是没有打印结果,大部分原因都是numpy版本引起,卸载重新安装。
3.huggingface连接失败,添加代理(提前是本地自己有梯子):
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:1087'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:1087'注意os相关的代码要再pipeline代码之前。
6.成功
成功最后打印:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









