






题一:医院设置 1364
题目描述
设有一棵二叉树,如图:
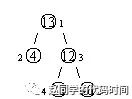
其中,圈中的数字表示结点中居民的人口。圈边上数字表示结点编号,现在要求在某个结点上建立一个医院,使所有居民所走的路程之和为最小,同时约定,相邻接点之间的距离为 11。如上图中,若医院建在1 处,则距离和为136;若医院建在 33 处,则距离和 81。
输入格式
第一行一个整数 n,表示树的结点数。
接下来的 n行每行描述了一个结点的状况,包含三个整数w,u,v,其中 w为居民人口数,u 为左链接(为 0 表示无链接),v为右链接(为 0 表示无链接)。
输出格式
一个整数,表示最小距离和。
输入输出样例
输入 #1
5
13 2 3
4 0 0
12 4 5
20 0 0
40 0 0输出 #1
81说明/提示
数据规模与约定
对于全部数据,1<=n<=100,结果不超int型
解决方案
问题拆分:① 计算各个结点到起点距离(makelist)并求出总和(caculate)
② 更换起点(main)
③ 求起点最小值(main)
子函数分析:
makelist:为了得到到起点距离,采用递归思想,具体见代码
存储结构:
该题要求我们能访问parent结点,故应设置parent域。采用邻接表方式存储二叉树。
#include <iostream>
#include <malloc.h>
using namespace std;
typedef struct places
{
int peoplenumber;
int lchild = 0;
int rchild = 0;
int valueparent = 0;
int tmplength;
} places;//所采用的数据结构,采用该种数据结构的目的是,能够实现对任意结点距离的计算
places country[105];//采用邻接表形式
//子函数Makelist的功能是修改tmplength的值,将所有tmplength更改为到当前结点的距离
void Makelist(int st, int count, int flag)
{
/*makelist函数采用递归写,flag控制递归形式
flag为1:表示上次调用是由左孩子调用,本次递归不访问左孩子
flag为2:表示上次调用是由右孩子调用,本次递归不访问右孩子
flag为3:表示上次调用是由parent调用,本次递归不访问parent
flag为0:所有均可访问,仅限st结点
递归出口:st为0直接返回
count每一层调用加1*/
if (!st)
return;
country[st].tmplength = count;
if (flag != 1)
Makelist(country[st].lchild, count + 1, 3);
if (flag != 2)
Makelist(country[st].rchild, count + 1, 3);
if (flag != 3 && st == country[country[st].valueparent].lchild)
Makelist(country[st].valueparent, count + 1, 1);
if (flag != 3 && st == country[country[st].valueparent].rchild)
Makelist(country[st].valueparent, count + 1, 2);
}
//子函数caculate先调用makelist得到各结点距离,计算总距离后返回值
int caculate(int st, int n)
{
Makelist(st, 0, 0);
int re = 0;
for (int i = 1; i <= n; i++)
re += country[i].tmplength * country[i].peoplenumber;
return re;
}
int main()
{
int n;
cin >> n;
int tmp = n;
int i = 1;
while (tmp--)
{
int w, lc, rc;
cin >> w >> lc >> rc;
country[i].peoplenumber = w;
country[lc].valueparent = i;
country[i].lchild = lc;
country[rc].valueparent = i;
country[i].rchild = rc;
i++;
}//录入数据
int min = 99999999;
for (int i = 1; i <= n; i++)
{
tmp = caculate(i, n);
min = tmp < min ? tmp : min;
}
cout << min;
}//主函数对caculate进行n次调用并判断输出最小值题二:部分背包问题 2240
题目描述
阿里巴巴走进了装满宝藏的藏宝洞。藏宝洞里面有N(N<=100)堆金币,第 ii 堆金币的总重量和总价值分别是Mi,Vi。阿里巴巴有一个承重量为T(T<=100)的背包,但并不一定有办法将全部的金币都装进去。他想装走尽可能多价值的金币。所有金币都可以随意分割,分割完的金币重量价值比(也就是单位价格)不变。请问阿里巴巴最多可以拿走多少价值的金币?
输入格式
第一行两个整数N,T。
接下来 NN行,每行两个整数Mi,Vi。
输出格式
一个实数表示答案,输出两位小数
输入输出样例
输入 #1
4 50
10 60
20 100
30 120
15 45输出 #1
240.00
解决方案
这一题非常简单,录入后对平均价值进行排序,按平均价值装入即可
存储结构:结构体动态数组
结构体:每座矿山大小、价值、均价值
排序方法:可采用冒泡排序
#include <iostream>
#include <malloc.h>
#include <vector>
#include <algorithm>
using namespace std;
typedef struct Node
{
int mass;
int value;
double aver;
} Node;
vector<Node *> aver;
int main()
{
int N, bagspace;
cin >> N >> bagspace;
int tmp = N;
while (tmp--)
{
int m, v;
cin >> m >> v;
Node *N;
N = (Node *)malloc(sizeof(Node));
N->mass = m;
N->value = v;
N->aver = (double)v / m;
aver.push_back(N);
}
int size = aver.size();
Node *tmpp;
for (int i = 0; i < size; i++)
for (int j = 0; j < size - i - 1; j++)
if (aver[j]->aver < aver[j + 1]->aver)
{
tmpp = aver[j];
aver[j] = aver[j + 1];
aver[j + 1] = tmpp;
}//完成排序
double result = 0;
for (int i = 0; i < size; i++)
{
if (bagspace >= aver[i]->mass)
{
bagspace -= aver[i]->mass;
result += aver[i]->value;
}
else if (bagspace <= 0)
break;
else
{
result += aver[i]->aver * bagspace;
break;
}
}
printf("%.2f", result);//注意输出格式
}题三:国王游戏 1080
题目描述
恰逢 HH国国庆,国王邀请nn 位大臣来玩一个有奖游戏。首先,他让每个大臣在左、右手上面分别写下一个整数,国王自己也在左、右手上各写一个整数。然后,让这 nn 位大臣排成一排,国王站在队伍的最前面。排好队后,所有的大臣都会获得国王奖赏的若干金币,每位大臣获得的金币数分别是:排在该大臣前面的所有人的左手上的数的乘积除以他自己右手上的数,然后向下取整得到的结果。
国王不希望某一个大臣获得特别多的奖赏,所以他想请你帮他重新安排一下队伍的顺序,使得获得奖赏最多的大臣,所获奖赏尽可能的少。注意,国王的位置始终在队伍的最前面。
输入格式
第一行包含一个整数nn,表示大臣的人数。
第二行包含两个整数 aa和 bb,之间用一个空格隔开,分别表示国王左手和右手上的整数。
接下来 nn行,每行包含两个整数aa 和 bb,之间用一个空格隔开,分别表示每个大臣左手和右手上的整数。
输出格式
一个整数,表示重新排列后的队伍中获奖赏最多的大臣所获得的金币数。
输入输出样例
输入 #1复制
3
1 1
2 3
7 4
4 6输出 #1复制
2说明/提示
【输入输出样例说明】
按11、22、33 这样排列队伍,获得奖赏最多的大臣所获得金币数为 22;
按 11、33、22 这样排列队伍,获得奖赏最多的大臣所获得金币数为22;
按 22、11、33 这样排列队伍,获得奖赏最多的大臣所获得金币数为 22;
按22、33、11这样排列队伍,获得奖赏最多的大臣所获得金币数为99;
按 33、11、22这样排列队伍,获得奖赏最多的大臣所获得金币数为 22;
按33、22、11 这样排列队伍,获得奖赏最多的大臣所获得金币数为 99。
因此,奖赏最多的大臣最少获得 22个金币,答案输出 22。
自己想的解决方案:模拟
对于小规模、无特殊元素时可以使用
特殊元素是指:进行交换后会导致唯一第二大值发生变化从而找不到的情况
但无论如何,好歹是自己想的,应该要有露脸的机会
思路:
进行模拟,由题目我们可以知道,假如存在一个当前最大的,我们将它不断向前移动,假如它在变小时后面出现了更大的或者相等的。则证明该序列已经不可能再小。
这其实已经体现了贪心算法。
这里贴一个题解对于贪心的证明:
证明方法:邻项交换法
这是一种重要的贪心证明方法,即只要计算假如相邻的两项交换位置,会对答案产生的影响,分析是交换更优还是不交换更优。
我这里的证明并不是交换邻项,而是选择任意两个大臣进行交换。
首先,交换第i个大臣和第j个大臣(i<j),不会影响1~i-1中的大臣的结果和第j+1~n中的大臣的结果
设1到i-1所有大臣的左手的乘积为x1(包括国王),i+1到j-1中所有大臣的左手乘积为x2,第i个大臣右手的数为ri左手为li,第j个大臣右手的数为rj左手为lj。

可见,优秀的算法写出必须要依靠较好的数学敏感度。
我的算法其实是在模拟了上述的交换过程。对于低精度的测试数据已经可以通过(高精度打不动),使用贪心算法得到仅需进行对lhand和rhand的乘积排序,就在逻辑上严谨了许多同时也更加便于设计算法。
自己写的模拟算法:
#include <iostream>
#include <vector>
#include <malloc.h>
#include <stack>
#include <set>
using namespace std;
typedef struct minister
{
int lhand, rhand;
int reward;
int before;
} minister;
vector<minister *> list;
stack<int> maxes;
set<int> maxss;
void swap(int i, int j)
{
minister *A;
A = list[i];
list[i] = list[j];
list[j] = A;
}
int Find(int i)
{
if (list.size() > 1)
for (int k = list.size() - 1; k >= 0; k--)
if (list[k]->reward == i)
return k;
}
int main()
{
freopen("P1080_5.in", "r", stdin);
int N;
cin >> N;
N++;
minister *tmp;
int product = 1; //乘积
int max = 0, maxp = 0, second, secondp;
for (int i = 0; i < N; i++)
{
tmp = (minister *)malloc(sizeof(minister));
cin >> tmp->lhand >> tmp->rhand;
tmp->reward = product / tmp->rhand;
if (i == 0)
tmp->reward = 0;
list.push_back(tmp);
tmp->before = product;
product *= tmp->lhand;
maxss.insert(tmp->reward);
} //完成录入并记录最后一个maxp
//交换操作不会改变后面和前面的奖励
for (set<int>::iterator it = maxss.begin(); it != maxss.end(); it++)
maxes.push(*it);
int result, chbf;
result = maxes.top();
maxp = Find(result);
maxes.pop();
while (maxp != 1)
{
if(maxp==166)
maxp=166;
max = list[maxp]->reward;
chbf = list[maxp - 1]->reward;
list[maxp]->before = list[maxp - 1]->before;
list[maxp]->reward = list[maxp]->before / list[maxp]->rhand;
list[maxp - 1]->before = list[maxp - 1]->before * list[maxp]->lhand;
list[maxp - 1]->reward = list[maxp - 1]->before / list[maxp - 1]->rhand; //交换了maxp和maxp-1的reward
if (list[maxp - 1]->reward >= result)
break; //如果大于了,序列失效,应该输出
if (list[maxp]->reward < result && list[maxp]->reward > maxes.top())
result = list[maxp]->reward; //如果小得不多,但小了,应该更新
if (list[maxp - 1]->reward!=maxes.top()&&chbf == maxes.top())
{
maxes.push(list[maxp - 1]->reward);
}
if (list[maxp - 1]->reward > maxes.top())
maxes.push(list[maxp - 1]->reward);
swap(maxp, maxp - 1);
maxp--;
if (list[maxp]->reward < maxes.top())
{
maxp = Find(maxes.top());
result = maxes.top();
maxes.pop();
}
if (list[maxp]->reward == maxes.top())
{
maxp = Find(maxes.top());
result = maxes.top();
}
//cout<<maxp<< ' '<<list[maxp]->reward<<endl;
}
cout << result;
}题解算法:贪心公式排序加高精度
#include <bits/stdc++.h>
using namespace std;
int now[20010],sum[20010],ans[20010],add[20010];
struct Node {
int a;
int b;
long long a_b;
}node[1010];
int read() {
int ans=0,flag=1;
char ch=getchar();
while( (ch>'9' || ch<'0') && ch!='-' ) ch=getchar();
if(ch=='-') flag=-1,ch=getchar();
while(ch>='0' && ch<='9') ans=ans*10+ch-'0',ch=getchar();
return ans*flag;
}
void times(int x) {
memset(add,0,sizeof(add));
for(int i=1;i<=ans[0];i++) {
ans[i]=ans[i]*x;
add[i+1]+=ans[i]/10;
ans[i]%=10;
}
for(int i=1;i<=ans[0]+4;i++) {
ans[i]+=add[i];
if(ans[i]>=10) {
ans[i+1]+=ans[i]/10;
ans[i]%=10;
}
if(ans[i]!=0) {
ans[0]=max(ans[0],i);
}
}
return ;
}
int divition(int x) {
memset(add,0,sizeof(add));
int q=0;
for(int i=ans[0];i>=1;i--) {
q*=10;
q+=ans[i];
add[i]=q/x;
if(add[0]==0 && add[i]!=0) {
add[0]=i;
}
q%=x;
}
return 0;
}
bool compare() {
if(sum[0]==add[0]) {
for(int i=add[0];i>=1;i--) {
if(add[i]>sum[i]) return 1;
if(add[i]<sum[i]) return 0;
}
}
if(add[0]>sum[0]) return 1;
if(add[0]<sum[0]) return 0;
}
void cp () {
memset(sum,0,sizeof(sum));
for(int i=add[0];i>=0;i--) {
sum[i]=add[i];
}
return ;
}
bool cmp(Node a,Node b) {
return a.a_b<b.a_b;
}
int main() {
int n=read();
for(int i=0;i<=n;i++) {
node[i].a=read(),node[i].b=read();
node[i].a_b=node[i].a*node[i].b;
}
sort(node+1,node+n+1,cmp);//学习sort函数自定比较方法的书写!
ans[0]=1,ans[1]=1;
for(int i=1;i<=n;i++) {
times(node[i-1].a);
divition(node[i].b);
if(compare()) {
cp();
}
}
for(int i=sum[0];i>=1;i--)
printf("%d",sum[i]);
return 0;
}python写法,python自带高精度ilil:
N=int(input())
s=input().split()
S=int(s[0])
T=int(s[1])
a=[]
for i in range(1,N+1):
k=input().split()
a.append((int(k[0]),int(k[1])))
a.sort(key=lambda x:x[0]*x[1])
ans=0
for i in range(0,N):
if(S//(a[i])[1]>ans):
ans=S//(a[i])[1]
S*=(a[i])[0]
print(ans)知识点:lamba 函数作为参数传递的用法 lamba函数具有”过滤“与“选择”功能 4. 将lambda函数作为参数传递给其他函数。 部分Python内置函数接收函数作为参数。典型的此类内置函数有这些。
|















 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









