







什么是条带化(striping)
当多个进程同时访问一个磁盘时,可能会出现磁盘冲突。大多数磁盘系统都对访问次数(每秒的I/O操作,IOPS)和数据传输率(每秒传输的数据量,TPS)有限制。当达到这些限制时,后面需要访问磁盘的进程就需要等待,这时就是所谓的磁盘冲突。
避免磁盘冲突是优化I/O 性能的一个重要目标,而 I/O 性能的优化与其他资源(如CPU和内存)的优化有着很大的区别 ,I/O 优化最有效的手段是将I/O 最大限度的进行平衡。
条带化技术就是一种自动的将I/O 的负载均衡到多个物理磁盘上的技术,条带化技术就是将一块连续的数据分成很多小部分并把他们分别存储到不同磁盘上去。这就能使多个进程同时访问数据的多个不同部分而不会造成磁盘冲突,而且在需要对这种数据进行顺序访问的时候可以获得最大程度上的I/O 并行能力,从而获得非常好的性能。很多操作系统、磁盘设备供应商、各种第三方软件都能做到条带化。
图1 描述的是一个未经条带化处理的连续数据的分布,图 2 描述的是一个已经被条带化处理的连续数据的分布,从中比较,我们可以发现图 2中对连续数据的读写都有最大的并发能力。

图 1. 未经条带化处理的连续数据

图 2. 已经被条带化处理的连续数据
由于条带化在I/O 性能问题上的优越表现,以致于在应用系统所在的计算环境中的多个层次或平台都涉及到了条带化的技术,如操作系统和存储系统这两个层次中都可能使用条带化技术。
影响条带化效果的两个因素
当对数据做条带化时,数据被切成一块块的小数据块,各小数据块分布存储在不同的硬盘上。从这个描述中我们可以看出,影响条带化效果的因素有两个,一是条带大小(stripesize),即数据被切成的小数据块的大小,另一个条带宽度(stripe width),即数据被存储到多少块硬盘上。
条带宽度(stripewidth)是指同时可以并发读或写的条带数量。这个数量等于RAID中的物理硬盘数量。例如一个经过条带化的,具有4块物理硬盘的阵列的条带宽度就是4。增加条带宽度,可以增加阵列的读写性能。道理很明显,增加更多的硬盘,也就增加了可以同时并发读或写的条带数量。在其他条件一样的前提下,一个由8块18G硬盘组成的阵列相比一个由4块36G硬盘组成的阵列具有更高的传输性能。
条带大小(stripesize),有时也被叫做block size, chunk size, stripelength 或者granularity。这个参数指的是写在每块磁盘上的条带数据块的大小。RAID的数据块大小一般在2KB到512KB之间(或者更大),其数值是2的次方,即2KB,4KB,8KB,16KB这样。
条带大小对性能的影响比条带宽度难以量化的多。
·减小条带大小:由于条带大小减小了,则文件被分成了更多个,更小的数据块。这些数据块会被分散到更多的硬盘上存储,因此提高了传输的性能,但是由于要多次寻找不同的数据块,磁盘定位的性能就下降了。
·增加条带大小:与减小条带大小相反,会降低传输性能,提高定位性能。
根据上边的论述,我们会发现根据不同的应用类型,不同的性能需求,不同驱动器的不同特点(如SSD硬盘),不存在一个普遍适用的"最佳条带大小"。所以这也是存储厂家,文件系统编写者允许我们自己定义条带大小的原因。不同条带大小,对于文件如何存储有很大的影响,请看下边这两幅图的对比:

这是一个由4块硬盘组成的RAID0阵列,左边的条带大小为4KB,右边的条带大小为64KB。
左边的图中的每一条细格表示4KB大小。
图中红色文件大小是4KB,蓝色文件大小20KB,绿色文件大小为100KB,紫色文件大小为500KB。
从图中我们可以看到,不同条带大小对"中型大小"文件的影响是很大的。对于红色的4KB文件来说,不论条带是4KB还64KB,它都分布在一块硬盘的一个数据块上。而对于紫色的500KB文件来说,无论条带是4KB还是64KB,它都会被分布在四块硬盘上。
但是对于蓝色20KB的文件来说,如果采用64KB的条带大小,则它就会被分布在一块硬盘上,而不是像4KB条带时那样分布在四块硬盘上。同样绿色的100KB文件在64KB条带时,会被分布到2块硬盘,而4KB条带时则分布到4块硬盘上。可以看到,增加条带大小可以明显地增加定位性能。在上边的例子中,条带宽度理所当然是4。
RAID5中stripe_head与stripe的区别
RAID5的基本架构
RAID5的读写操作采用的是stripe的基本结构,即以stripe为读写的基本单位,假设一个3+1的RAID5,即3个数据盘+1个校验盘,那么一个stripe就包含3个数据块和一个校验块。我们结合图示来仔细看下RAID5的架构。
如图所示,这是一个3+1的RAID5,图中的每一个方块表示一个stripe的一个基本单元,又称为chunk;相同颜色的方块组成一个stripe,即每个stripe由3个数据chunk(A,B,C)+1个校验chunk(P)组成。关于校验块的生成方法以及数据恢复原理如下:
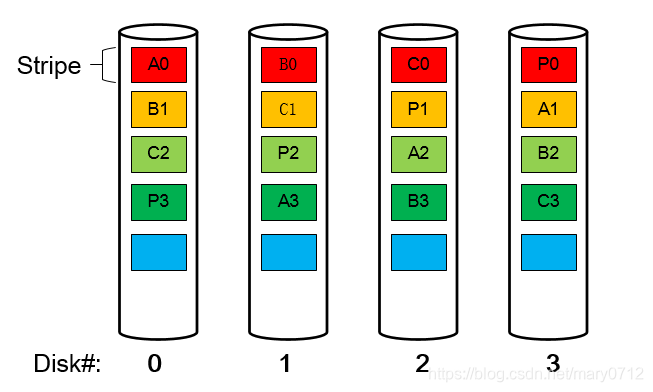
校验块P的生成方法为P=A⊕B⊕C 。(⊕表示异或运算)
加入1号盘坏了,此时有读请求读B0块的数据,那么可以通过B0=A0⊕C0⊕P0 的方法 来进行恢复。
可以观察到上图中的校验块不是单独的全部存在一个盘上,这是为了实现RAID中磁盘的磨损平衡,防止某个盘寿命太短而先损坏。 内核中有很多这种平衡校验块的算法,上图中用到的是ALGORITHM_LEFT_SYMMETRIC。
内核中默认的stripe大小
基本上所有的OS都认可的page大小是4KB,由于内核中是按sector为基本大小单位,1 sector = 512B,所以有如下公式:
1 page = 8*sector = 4KB
1 chunk = 128*page = 512KB
1 stripe = 4*chunk = 2048KB
1 stripe的data size =3*chunk =1536KB
---------------------
RAID5在内核中的处理单元stripe_head
虽然说直观上看RAID5的基本处理单元是stripe,但是一个chunk的大小是512KB,这与OS一次处理的page大小相差太多,所以为了处理的一致性,内核将一个chunk分成128个page,由一个stripe的每个chunk出一个对应的page组成内核中的RAID5处理的基本单元:stripe_head。stripe_head的定义在raid5.h中。
我们用图来详细了解下stripe_head与stripe的区别。
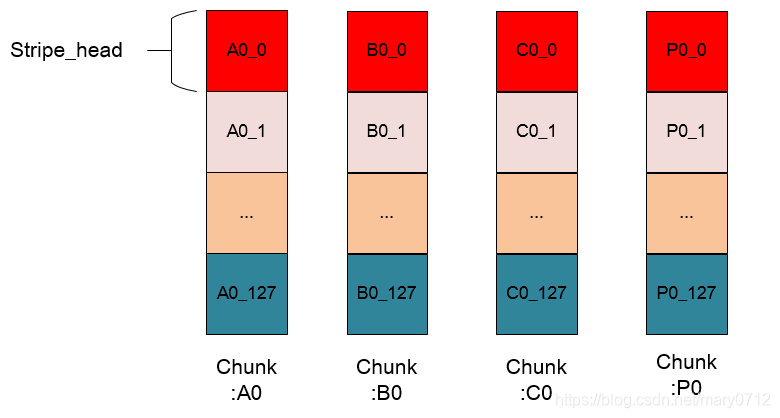
这是第一幅图中的stripe 0 的细化,stripe 0 由A0、B0、C0和P0组成,这幅图中,将每个chunk细化,由于一个chunk的大小是128个page的大小,所以一个chunk中含有128个page,每个page的大小是4KB,所以在每一个chunk中具有相同偏移量的page组成一个stripe_head,即图中每个颜色相同的方块组成一个stripe_head。
1 stripe_head = 4*page = 16KB
1 stripe = 128 * stripe_head =2048KB
所以说:我们经常说的RAID5的处理单元stripe,实际上是内核中的处理单元stripe_head的结合体,不要搞混淆了哦~
另外我还要再强调一点,每个请求bio都会有一个起始地址,这个地址对应的位置(根据上述的算法ALGORITHM_LEFT_SYMMETRIC来确定到哪块盘上,以及在这块盘上的偏移量),一旦这个位置确定,它就会和在其他盘上具有相同偏移量的page构成一个stripe_head结构,这是确定了的,无法更改的!!!stripe_head中的sector域就是来记录这个偏移量的。
整条写、重构写与读改写
整条写(Full-Stripee Write):整条写需要修改奇偶校验群组中所有的条带单元,因此新的奇偶校验值可以根据所有新的条带数据计算得到,不需要额外的读、写操作。因此,整条写是最有效的写类型。整条写的例子,如 RAID 2、RAID 3。它们每次IO总是几乎能保证占用所有盘,因此每个条带上的每个Segment都被写更新,所以控制器可以直接利用这些更新的数据计算出校验数据之后,在数据被写入数据盘的同时,将计算好的校验信息写入校验盘。
重构写(Reconstruct Write,rcw):如果要写入的磁盘数目超过阵列磁盘数目的一半,可采取重构写方式。在重构写中,从这个条带中不需要修改的 Segment 中读取原来的数据,再和本条带中所有需要修改的 Segment 上的新数据计算奇偶校验值,并将新的 Segment 数据和没有更改过的 Segment 数据以及新的奇偶校验值一并写入。显然,重构写要牵涉更多的I/O操作,因此效率比整条写低。重构写的例子,比如在RAID 4中,如果数据盘为8块,某时刻一个IO只更新了一个条带的6个Segment,剩余两个没有更新。在重构写模式下,会将没有被更新的两个Segment的数据读出,和需要更新的前6个Segment的数据计算出校验数据,然后将这8个 Segment 连同校验数据一并写入磁盘。可以看出,这个操作只是多出了读两个Segment 中数据的操作和写两个 segment 的操作,但是写的时候几乎不产生延迟开销,因为是宏观同时写入。
读改写(Read-Modify Write,rmw):如果要写入的磁盘数目不足阵列磁盘数目的一半,可采取读改写方式。读改写过程是:先从需要修改的 Segment 上读取旧的数据,再从条带上读取旧的奇偶校验值;根据旧数据、旧校验值和需要修改的 Segment上的新数据计算出这个条带上的新的校验值;最后写入新的数据和新的奇偶校验值。这个过程中包含读取、修改和写入的一个循环周期,因此称为读改写。读改写计算新校验值的公式为:新数据的校验数据=(老数据EOR新数据)EOR老校验数据。如果待更新的Segment已经超过了条带中总Segment数量的一半,则此时不适合用读改写,因为读改写需要读出这些 Segment 中的数据和校验数据。而如果采用重构写,只需要读取剩余不准备更新数据的 Segment 中的数据即可,而后者数量比前者要少。所以超过一半用重构写,不到一半用读改写。整条更新就用整条写。
写效率排列为整条写>重构写>读改写。
raid5的写入情况分成3种:
1.要写入的数据布满整个条带。这种情况可以把要写入的数据的校验信息算好,直接把整个条带写入磁盘。
2.要写入的数据大于半个条带。这种情况可把这个条带上不需要修改的数据读出来,和要写入的数据一起计算校验,并写入磁盘。rcw:read-construct-write,这个是重构一个stripe_head
3.要写入的数据小于半个条带。这种情况需要把要修改的旧数据和原始的校验数据读出来,并连同新数据一起计算校验值。rmw:read-modified-write,这个是覆盖写的方式
4.同样开支采用rcw方式
5.EC纠删码仅使用rcw方式进行,在"小写"的时候所有速度慢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









