






前言
根据系列上篇文章,我们已经了解了知识图谱的基本概念,以及现在知识图谱发展状况,与前沿AI结合方向。现在就差真正实践构建知识图谱这临门一脚,基本上就会对知识图谱这一产品有更加清晰的认识。
那么工欲善其事必先利其器,就像我们对编程语言的掌握程度,更高级的用法和熟练度能更进一步提高我们做出项目产品的质量,在本篇文章将从开发环境部署写到初级知识图谱搭建实践,完成从无到有的知识图谱构建过程。
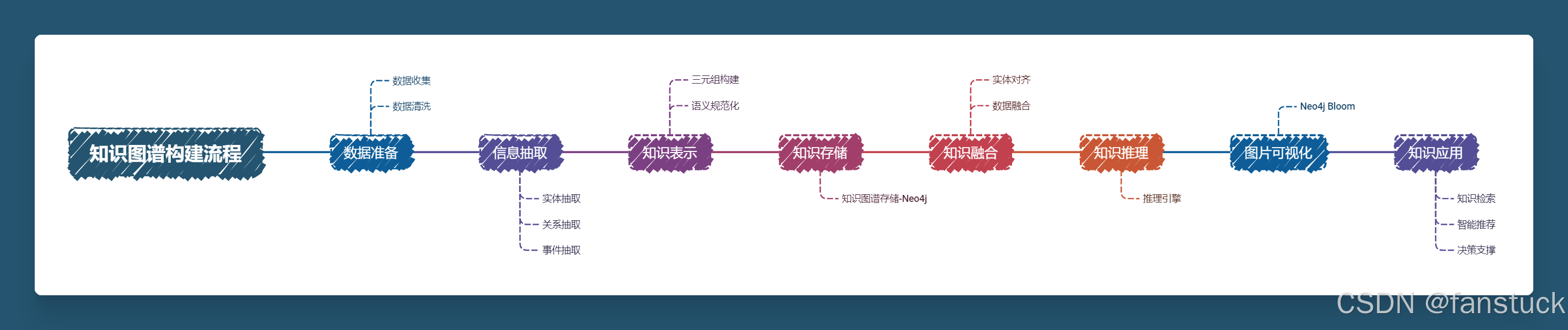
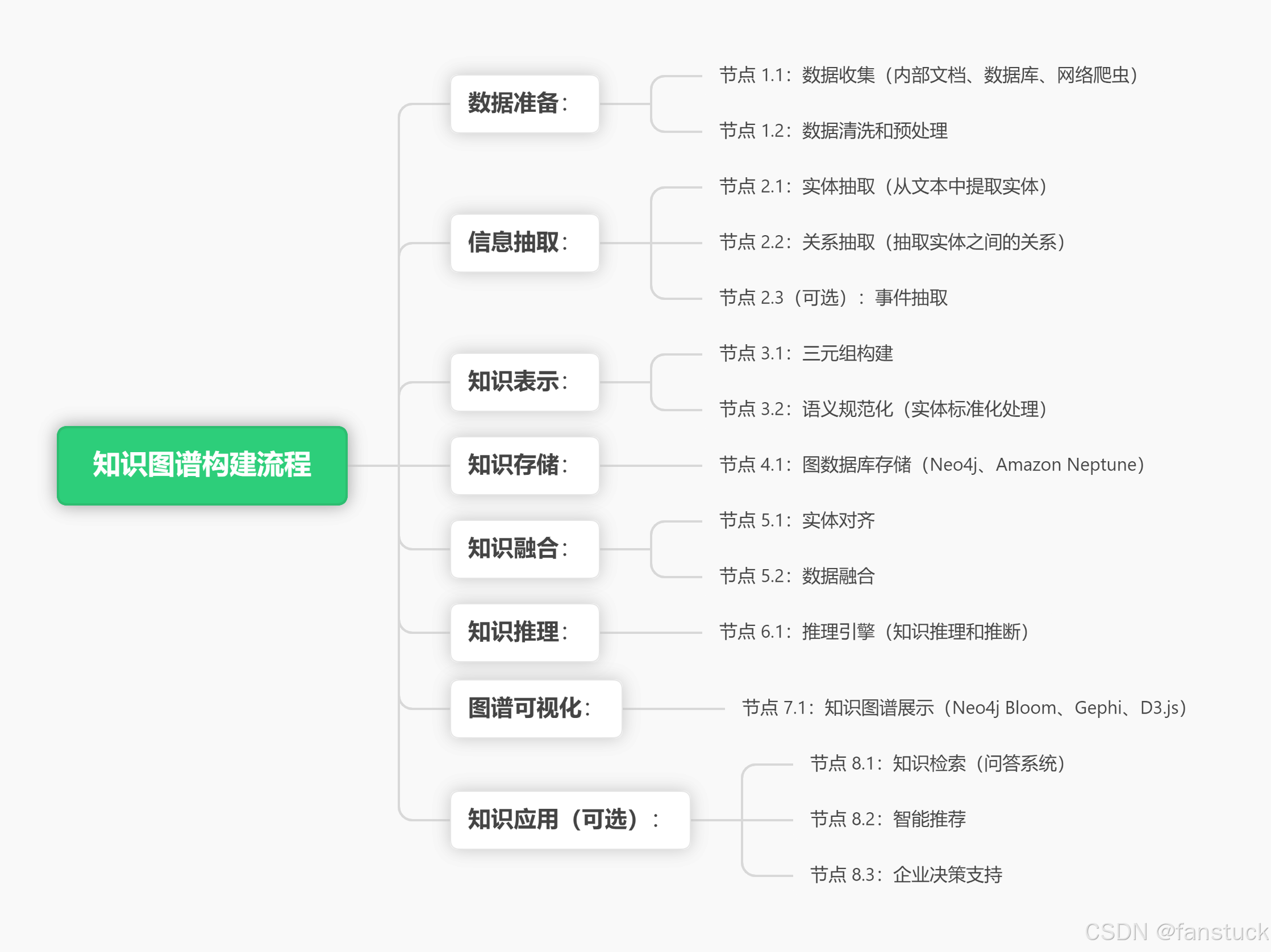
那么第一步我们应该完成数据准备到信息抽取,数据准备默认已经完成,我这里使用招标采购基本知识的文本word作为演示数据,来进行信息抽取。
二、知识图谱实践
1.信息抽取
信息抽取(Information Extraction,简称 IE)是构建知识图谱中最核心的步骤之一,其目标是从非结构化的文本数据中自动提取出有意义的结构化信息,包括实体、关系、和事件等。信息抽取主要分为以下几个步骤:实体抽取、关系抽取、属性抽取和事件抽取,每一步都涉及不同的方法和工具。
关于信息抽取工具我这里使用的是PaddleNLP的UIE模型,Yaojie Lu等人在ACL-2022中提出了通用信息抽取统一框架UIE。该框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力。
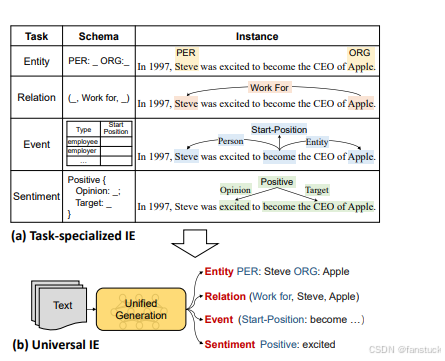
感兴趣的朋友可以阅读论文更深入的了解,这里作实践演示不开展论述:
! pip install --upgrade paddlenlp
! pip show paddlenlp
基于PaddleNLP-UIE模型实现知识图谱信息抽取模块。
1.1 实体抽取(Entity Extraction)
实体抽取,也称为命名实体识别(NER,Named Entity Recognition),是从文本中识别出特定类型的名词短语,通常是有实际意义的词汇,例如人名、地名、组织、日期、产品、技术名词等。实体抽取的目标是将文本中的重要信息点结构化,以便后续分析和存储。
- 实体类型:
- 人物(Person):如“马云”
- 地点(Location):如“杭州”
- 组织(Organization):如“阿里巴巴”
- 时间(Time):如“2024年8月”
- 其他(Product, Event, Money等)
例如我们以文本数据为例来操作:
schema = ['时间', '城市'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema, model='uie-base')
ie_en = Taskflow('information_extraction', schema=schema, model='uie-base-en')
pprint(ie("凡我市(含县(区)、开发区(新区))国有资金投资的房屋建筑和市政基础设施工程自2017年6月3日起发布招标文件的施工招标项目,应当执行《南昌市人民政府办公厅关于印发南昌市国有资金投资建设工程项目招标实施年度投标保证金制度(试行)的通知》(洪府厅发〔2016〕74号)的规定。")) # Better print results using pprint
[{'城市': [{'end': 71,
'probability': 0.9465240012183784,
'start': 68,
'text': '南昌市'},
{'end': 85,
'probability': 0.9736215907851147,
'start': 82,
'text': '南昌市'}],
'时间': [{'end': 48,
'probability': 0.5193512646392762,
'start': 39,
'text': '2017年6月3日'}]}]
1.2 关系抽取(Relation Extraction)
关系抽取(Relation Extraction,简称RE),是指从文本中识别实体并抽取实体之间的语义关系,进而获取三元组信息,即<主体,谓语,客体>。关系抽取旨在识别文本中两个或多个实体之间的关系。比如,识别“阿里巴巴由马云创立”中的“创立”关系,将“马云”与“阿里巴巴”链接起来。
- 关系类型:
- 例如 “创立”、“所属”、“合作”等。
schema = {'部门':['指导','活动名称']}
ie.set_schema(schema)
txt_file='国务院发展改革部门指导和协调全国招标投标工作,对国家重大建设项目的工程招标投标活动实施监督检查。'
pprint(ie(txt_file))
[{'部门': [{'end': 9,
'probability': 0.9600018973785609,
'relations': {'指导': [{'end': 22,
'probability': 0.9368320465242093,
'start': 14,
'text': '全国招标投标工作'}]},
'start': 0,
'text': '国务院发展改革部门'}]}]
1.3 属性抽取(Attribute Extraction)
属性抽取是识别和抽取出实体的相关属性值。例如,识别公司成立的日期、产品的规格、事件的参与人员等。
schema = {'公司':['创始人','成立时间','地点']}
ie.set_schema(schema)
txt_file='阿里巴巴集团控股有限公司(简称:阿里巴巴集团)是马云带领下的18位创始人于1999年在浙江省杭州市创立的公司。'
pprint(ie(txt_file))
[{'公司': [{'end': 12,
'probability': 0.8997031190817637,
'relations': {'创始人': [{'end': 26,
'probability': 0.7737946618519764,
'start': 24,
'text': '马云'}],
'地点': [{'end': 49,
'probability': 0.3552619337063625,
'start': 43,
'text': '浙江省杭州市'}],
'成立时间': [{'end': 42,
'probability': 0.8343506849196594,
'start': 37,
'text': '1999年'}]},
'start': 0,
'text': '阿里巴巴集团控股有限公司'}]}]
1.4 事件抽取(Event Extraction)
事件抽取是从文本中识别和抽取出复杂的事件结构。例如,从“2020年,阿里巴巴宣布启动新零售计划”中识别出“阿里巴巴”作为主体,事件是“启动”,时间是“2020年”,对象是“新零售计划”。
schema = {'启动':['时间','对象']}
ie.set_schema(schema)
txt_file='2020年,阿里巴巴宣布启动新零售计划'
pprint(ie(txt_file))
[{'启动': [{'end': 19,
'probability': 0.975417622363075,
'relations': {'时间': [{'end': 5,
'probability': 0.9598323070613546,
'start': 0,
'text': '2020年'}]},
'start': 14,
'text': '新零售计划'}]}]
那么我们了解了抽取方法,接着我们要对我们的数据做一个整体包装:
import paddlehub as hub
import json
from collections import defaultdict
from docx import Document
import jieba.posseg as pseg
from paddlenlp import Taskflow
def extract_text_from_docx(docx_path):
document = Document(docx_path)
return [paragraph.text.strip() for paragraph in document.paragraphs if paragraph.text.strip()]
def split_paragraphs_into_sections(paragraphs):
sections = defaultdict(list)
current_section = "其他"
for paragraph in paragraphs:
if "招标类型" in paragraph:
current_section = "招标类型"
elif "招标组织方式" in paragraph:
current_section = "招标组织方式"
elif "项目要求" in paragraph:
current_section = "项目要求"
sections[current_section].append(paragraph)
return sections
def generate_schema_from_sections(sections):
section_schemas = {}
for section, paragraphs in sections.items():
entity_candidates = defaultdict(int)
relation_candidates = defaultdict(int)
for paragraph in paragraphs:
words = pseg.cut(paragraph)
for word, flag in words:
if flag in ['n', 'nr', 'ns', 'nt', 'nz']:
entity_candidates[word] += 1
elif flag in ['v']:
relation_candidates[word] += 1
top_relations = sorted(relation_candidates, key=relation_candidates.get, reverse=True)[:10]
schema = {}
for entity in entity_candidates:
schema[entity] = top_relations
section_schemas[section] = schema
return section_schemas
def process_text_with_uie_by_sections(sections, ie_model, section_schemas):
extracted_info = {}
for section, paragraphs in sections.items():
schema = section_schemas.get(section, {})
ie_model.set_schema(schema)
section_info = []
for paragraph in paragraphs:
extraction_result = ie_model(paragraph)
section_info.append(extraction_result)
extracted_info[section] = section_info
return extracted_info
def save_extracted_info_to_json(extracted_info, output_path):
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(extracted_info, f, ensure_ascii=False, indent=4)
def main():
docx_path = 'data/招标采购基本知识.docx' # Replace with your actual file path
output_json_path = 'data/extracted_info.json' # Replace with your output path
paragraphs = extract_text_from_docx(docx_path)
sections = split_paragraphs_into_sections(paragraphs)
section_schemas = generate_schema_from_sections(sections)
print(f"Generated Schemas: {section_schemas}")
ie_model = Taskflow('information_extraction', model='uie-base') # Load PaddleHub UIE model
extracted_info = process_text_with_uie_by_sections(sections, ie_model, section_schemas)
save_extracted_info_to_json(extracted_info, output_json_path)
print(f"Extracted information and saved to {output_json_path}")
if __name__ == "__main__":
main()
得到对应json文件:

那么下一步我们就可以进行Neo4j存储,在此之前要开始部署环境,等下一章我们再详细准备。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











