






 本文介绍了一种名为G-HOP的生成模型,它通过去噪扩散技术学习手与物体的交互,能生成合理的配置。G-HOP在手物互动的表示、合成和重建任务中表现出色,尤其在理解和生成复杂手-物体互动方面有重大突破。
本文介绍了一种名为G-HOP的生成模型,它通过去噪扩散技术学习手与物体的交互,能生成合理的配置。G-HOP在手物互动的表示、合成和重建任务中表现出色,尤其在理解和生成复杂手-物体互动方面有重大突破。
DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
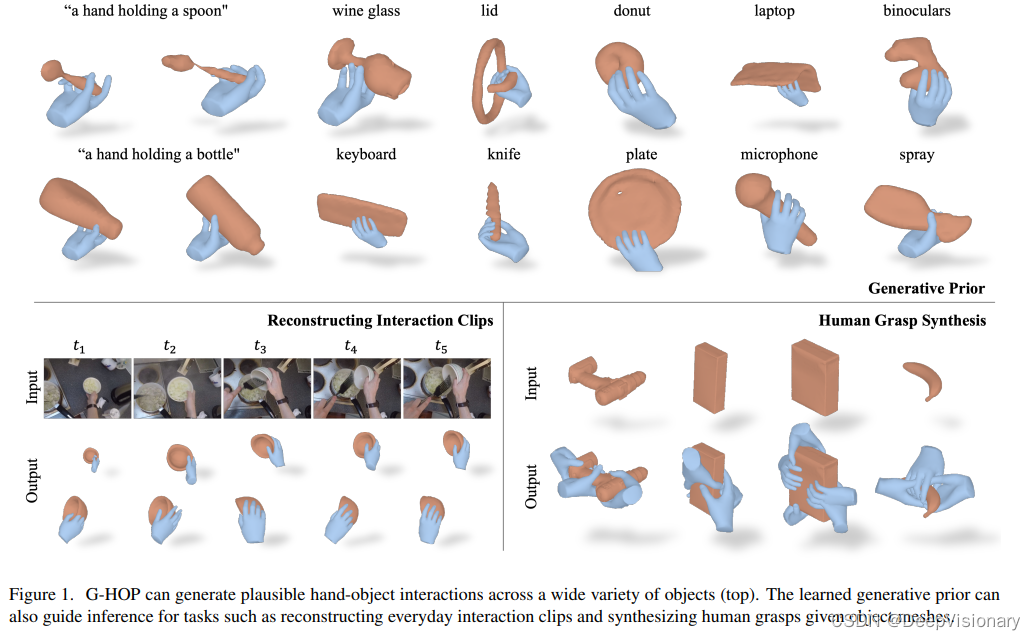
引言:日常生活中的手与物体交互
在我们日常生活中,手与物体的交互无处不在且多样化。想象一下,当你拿起一瓶水、一把刀或一副剪刀时,你不仅能够感受到这些物体不同的形状,例如瓶子的圆柱形、刀的平面形,还能够自然而然地预见到你的手会如何与它们相互作用。这种交互的形式可能因物体的几何形状(例如,我们握笔和握锅的方式截然不同)或操作意图(例如,传递一把刀与用它切东西)而有很大的不同。
在这项工作中,我们的目标是构建一个计算系统,能够类似地生成合理的手与物体的配置。具体而言,我们学习了一个基于去噪扩散的生成模型,能够捕捉交互过程中手和物体的联合分布。例如,给定一个类别条件的描述,如“一只手持盘子”,我们的生成模型可以合成出合理的物体形状以及相对应的人手配置和关节活动。我们所解决的关键问题是,如何为模型提供良好的手与物体交互(HOI)表示。与通常通过空间(符号)距离场描述物体形状不同,人手常常通过参数化网格模型来控制,这些由关节活动变量控制。
论文标题、机构、论文链接和项目地址
- 论文标题:G-HOP: Generative Hand-Object Prior for Interaction Reconstruction and Grasp Synthesis
- 机构:Carnegie Mellon University
- 论文链接:G-HOP on arXiv
- 项目地址:G-HOP Project
研究背景与动机
在现代交互技术与机器人学中,理解并合成人与物体的互动(Hand-Object Interactions,简称 HOI)是一个核心问题。人们在日常生活中与各种物体进行互动,如抓握瓶子、操作剪刀等,这些互动在形态和功能上都有着极大的多样性。然而,尽管这些互动看似简单,要让计算机系统理解并合成这些互动却是极具挑战性的。
传统的方法往往依赖于简化的物体模板或是专门为某一任务训练的模型,这些方法在处理未见过的物体或新的互动类型时通常效果不佳。此外,这些方法也往往无法准确捕捉手和物体间复杂的空间关系,如遮挡与接触,这限制了它们在实际应用中的效果。因此,开发一种能够广泛理解并合成多种手物互动的通用计算模型,对推动相关技术的应用,如增强现实、机器人自动学习等,具有重要意义。
针对上述问题,本研究提出了一种基于去噪扩散模型的生成式先验(Generative Prior),称为 G-HOP,旨在模拟和生成3D中的手-物体互动。G-HOP 不仅可以合成真实感的手和物体的形状,还可以通过优化过程在多个任务中作为一种通用先验被应用,如从视频中重建互动形态和合成人类抓握动作。
G-HOP模型介绍
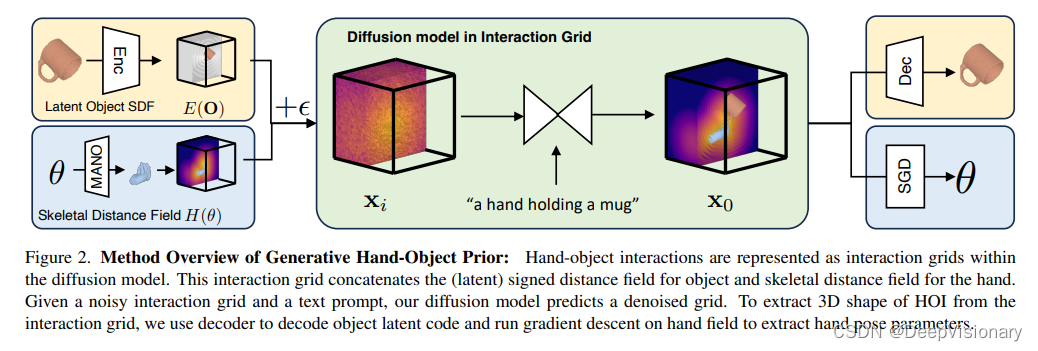
G-HOP模型是一种基于去噪扩散(Denoising Diffusion)的生成模型,用于学习和生成手和物体在3D空间中的联合分布。模型的核心在于采用了一种统一的手-物体互动(HOI)表示方式——交互格网(Interaction Grids)。该表示将手的骨架距离场和物体的隐式距离场(latent signed distance field)结合在一起,以便模型能够有效地处理和生成复杂的手物互动形态。
交互格网的构建
交互格网是一个融合了手的骨架距离场和物体的隐式距离场的3D网格。具体来说,物体的距离场被编码为一个低维的潜在代码,通过 VQ-VAE 技术实现压缩,而手的表示则通过一个参数化的骨架距离场来描述,该场景由手的姿态参数控制。这样的设置不仅有利于捕捉手和物体间的空间关系,而且通过统一的网格表示,大大简化了模型学习的复杂性。
生成与推理
在生成阶段,模型通过输入类别条件的描述(例如“一个手持盘子的手”)来合成可能的手和物体形状。而在推理阶段,G-HOP可以利用学到的生成先验来辅助完成从交互视频剪辑重建3D手物形状和合成可能的人类抓握动作等任务。具体来说,通过计算交互格网的对数似然梯度,模型能够在优化框架中引导形状和姿态的调整,以达到更加真实和准确的重建效果
主要技术细节
1. 统一的交互网格表示
在我们的研究中,我们引入了一个统一的表示方法——交互网格(Interaction Grid),用以整合手和物体的3D模型。这种表示包括两部分:物体的潜在符号距离场(Latent Signed Distance Field)和手的骨骼距离场(Skeletal Distance Field)。这一表示形式的统一化设计,允许扩散模型有效地推理出手和物体之间的3D交互。
2. 基于扩散模型的生成先验
我们利用扩散模型(Diffusion Model)作为核心的生成技术,通过训练学习手和物体的联合分布。这个生成模型不仅可以合成多样化的手和物体形状,而且还可以作为其他任务的通用先验,如视频中的手物交互重建和合成人类抓握。
3. 优化框架与实时测试
在实际应用中,我们通过测试时优化(Test-time Optimization)来应用学到的生成先验。这包括利用扩散模型的得分蒸馏采样(Score Distillation Sampling)来近似交互网格的对数概率梯度,进而指导优化过程以生成更合理的交互形态。
应用场景与优势
1. 交互式视频重建
利用我们的生成先验,可以从包含手物交互的视频片段中重建出手和物体的3D形状。与传统的依赖于特定对象模板的方法相比,我们的模型能够处理更广泛的物体类别,并且在重建质量上有显著提升,尤其是在细节的再现上。
2. 人类抓握合成
在抓握合成应用场景中,我们的模型可以根据任意给定的物体网格生成自然的人类手势。这对于增强现实(AR)和机器人学等领域尤为重要,可以大大提高用户交互的自然性和机器人的操作能力。

3. 优势总结
总的来说,我们的方法提供了一种新颖的手物交互建模方式,不仅能够生成多样且合理的交互形式,还可以提升相关任务的性能,如视频重建和抓握合成。此外,通过集成多个真实世界数据集进行训练,我们的模型能够泛化到广泛的物体类别,显示出较强的应用潜力和实用价值。
实验验证与结果分析
1. 概述
在本节中,我们详细分析了基于去噪扩散模型的生成先验G-HOP(Generative Hand-Object Prior)的实验验证过程及其结果。这一模型主要针对三维手-物体交互(HOI)场景的合成和重建,通过整合七个不同的实际交互数据集,覆盖了155个物品类别。
2. 实验设置
实验目的是验证G-HOP模型在视频基础的重建任务及人类手部抓取合成中的表现。我们使用的主要评估指标包括物体重建误差、手部重建误差(MPJPE, AUC),以及手-物体对齐误差(CDh)。我们将G-HOP与其他几种基线模型进行了比较,包括iHOI、HHOR以及DiffHOI。不同于这些模型,G-HOP能够在三维空间中同时考虑手和物体的建模,而不是单独对手部或物体建模。
3. 结果分析
G-HOP在多个评估指标上均显示出优越性。具体来说,它在HOI4D数据集上的表现超过了其他所有基线方法。我们的模型不仅提高了物体的重建质量,还能更准确地重建手部姿态,特别是在复杂的交互场景中。此外,G-HOP的优势还体现在其泛化能力上,即使在从未训练过的物体类别上也能保持较高的性能。实验结果证明了G-HOP在处理真实世界数据集时的鲁棒性和有效性。
挑战与未来展望
1. 技术挑战
尽管G-HOP在多项任务中表现优异,但在实际应用中仍存在一些技术挑战。首先,目前的模型依赖于精确的类别信息作为输入,这限制了模型的灵活性和扩展性。其次,虽然模型能够合成逼真的手-物体交互形态,但在确保物理接触方面还没有一个明确的机制,这在某些应用场景下可能会导致不真实的交互表现。
2. 未来方向
未来的研究可以在以下几个方向进行探索和扩展:
- 模型泛化能力的提升:开发不依赖于具体类别信息的手-物体交互生成模型,提高模型的适应性和应用范围。
- 交互质量的优化:引入新的机制来保证生成的手部和物体之间在物理上的正确接触,以增强模型的实用性。
- 多模态学习的应用:整合视觉、触觉等多种感知信息,以实现更为复杂和精确的手-物体交互模拟。
总体而言,G-HOP模型的开发标志着在复杂交互场景下三维手-物体建模领域的一个重要进步。我们期待未来的研究能够解决现有限制,并推动该技术向实际应用更大范围的扩展。
总结
本文提出了一个基于去噪扩散的生成模型G-HOP,用于模拟手与物体的交互。这种模型能够同时生成手部和物体的三维形态,是首个能够处理这种复杂交互的方法。通过融合多个真实世界数据集,G-HOP能够覆盖155种不同类别的物体,显示出优异的泛化能力。
1. 研究意义和创新点
- G-HOP模型的创新之处在于提供了一种统一的手物交互(HOI)表示,使得模型能够有效学习和生成手和物体的三维形态。
- 该模型不仅支持从交互片段重建手和物体的形状,还能合成符合逻辑的人类抓握动作,显著超过现有的特定任务模型。
2. 应用前景
- G-HOP的成功应用展示了其在辅助机器人学习和虚拟助手技术中的潜力,尤其是在交互式学习和操作任务中的应用。
- 此外,该模型的推理功能通过优化框架实现,结合了先验概率和特定任务的目标,为未来的机器人视觉和操作研究提供了新的工具。
3. 潜在限制与未来方向
- 尽管G-HOP在多任务生成和重建方面表现出色,但其依赖于特定类别信息的输入,可能限制了模型的进一步扩展。
- 未来的研究可以探索更少依赖类别信息的模型设计,以及进一步提升模型在未见类别物体上的表现和适应能力。
总体而言,G-HOP模型通过其创新的生成手物交互表示,为理解和生成复杂的人物交互提供了新的视角和可能性。
关注DeepVisionary 了解更多深度学习前沿科技信息&顶会论文分享!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









