






美团运维开发复盘
面试官很nice,感谢两位大佬的insight,耐心回答了很多。整理时有被大佬的条理性惊艳到。
考察主要分为三大块:
- 操作系统:Linux命令,原理
- 开发:Python
- 组件原理:组里主要是HDFS/YARN/k8s
待弄懂的面试题
面试时没答好和没弄懂的部分。补了现在的答案,欢迎留言指正🤗
环境配置
Q:如何配置Python环境且重启仍生效
A:(犹豫了下说通过conda指定,还是直接~/.bashrc配路径。不过conda的调用也是配在.bashrc里的)~/.bashrc,一般都写在这里。
Q:.bashrc和/etc/profile如果配了不同的Python环境,哪个会生效?
A:(这里正解应该是.bashrc。写下来~/.bashrc在用户路径下,/etc/profile在系统路径下,一般而言,作用域小的配置会覆盖作用域大的配置)
搜索还发现很多种配置文件,如:// 有best practice吗 TODO
/etc/environment/etc/profile/etc/profile.d/test.sh,新建文件/etc/bashrc,或者/etc/bash.bashrc(Git Bash用过)~/.bash_profile,或者~/.profile(Mac见过)~/.bashrc(Ubuntu, Mac用过)
看评论的争议部分,调用顺序可能与操作系统发行版也有一定关系
- https://zhuanlan.zhihu.com/p/317282094 评论区称
/etc/bash.bashrc最后生效 // 可它不算系统级配置吗 TODO
验证方法:每个配置里加一行export TEST_ORDER="$TEST_ORDER:<current_profile>"
如何判断操作系统CPU,内存,IO,网络资源耗尽了?
提了htop后,面试官是打算对着htop界面问的,具体看哪个参数etc。
好问题,又是一个自己之前模糊带过的点。
挖一挖还挺多,单独写一篇。结合这一问的引导,
整理中TODO:https://blog.csdn.net/mathemagics/article/details/137754436
TODO:sar几项参数意义,阈值在大约多少等,结合用过的top,htop,free -m比较看看
TODO:平时用Prometheus + Grafana的时候显示就只有用量/百分比,也想知道这个数值是怎么来的?
日志查看访问量top100
cat server.log \
| sed -E 's/???/???/g' \ # 弄出ip。正则还要再复习下,太依赖Copilot+在线regex调试工具了
| sort | uniq -c \ # -c for `count`,输出是类似 9 10.23.23.1 的结果
| sort -nk1,1 -r | head -100 \
| awk '{print $2}' | paste -sd,
(组件方面在Hadoop/YARN/k8s中选测)
一面发现大数据组件忘干净了,去复习了以前用Spark standalone环境配置和Spark开发+Scala的笔记,以及粗看了Spark on k8s的三种方式。二面知道了由于Spark运维复杂度较小,需要考察的主要还是Hadoop/YARN/k8s(白通宵了x,但面试考察点选取思路收获哈哈√)
k8s如何起一个容器?从客户端申请开始
用户的申请请求是从谁发给k8s的哪个模块或者哪个角色,然后谁又请求谁,怎么一层一层把这个请求传递到哪个角色上面,去把这个东西建起来。然后把信息回传给谁谁,按照这个链条介绍。
好问题,学习时忽视了。熟悉流程应该会对排查问题很有帮助,之后学习时都关注下。
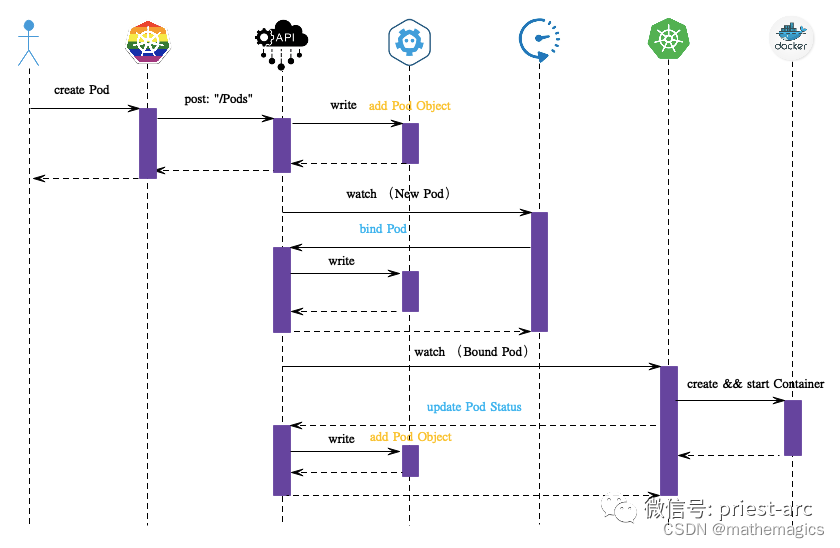
图源:https://mp.weixin.qq.com/s/5gPxyl30nwVk8kuBBmk3Bg
我的解释 根据印象写的草稿,TODO & TOCHECK:
图标分别为:
| 用户 | kubectl | API-server | etcd | scheduler | kubelet | container runtime |
|---|
-
用户敲了
kubectl create ... -
kubectl 向 k8s API-server 发起一个create pod 请求(RESTful),
API-server 接收到pod创建请求后,不会去直接创建pod;而是生成一个包含创建信息的yaml。
-
API-server 将yaml写入etcd数据库。
-
// scheduler如何知道Node上还有多少资源的? TODO - 下一个问题 论文里找一下时序图
scheduler将Pod和Node绑定
// scheduler将资源写到哪里?
-
kubelet 通过监测etcd,发现 k8s api server 中有了个新的Node,比照这条记录中的Node与自己的编号是否相同;
-
如果相同,则Node上的kubelet 让容器运行时(如containerd)创建容器;同时向API server更新Pod状态
-
API server将收到的Pod状态写入etcd
默认调度器如何知道哪个Node上还有多少资源的?
面试官灵魂发问:为什么看源码时只看了调度器,没有把整体看一遍?
TODO:源码里那个变量从哪传进来的(因为CPU用的是request值,必然非metric server)?是和etcd通信还是API server通信?
TODO:论文中的调度器用的metrics是否要做个持久化存储?只cache而不留历史数据,感觉确实有问题
TODO - 看到提及论文时序图再补上。印象有见过,但翻了几篇的调度器调用服务的时序图都略过了这一点。
如果容器创建过程中就挂了(比如网络问题,比如创建到一半Node挂了),会发生什么?
不是已经创建好再挂。
// 网络问题我当时理解是,比如容器仓库无法访问。但现在想来应该是controlplane与Node间的网络问题
k8s集群内部的认证?
RBAC相关的看一下 TODO
本科你都学了哪些大数据的东西?
TODO:有条理地捋一遍知识点,从分布式原理层(PAC、网络/节点/时延不同假设下模型),到时钟同步etc,到大数据组件,到毕设项目
HDFS架构
谷歌三大论文?
分布式文件系统(GFS):(Hadoop的HDFS的参考)
概念:作用于底层,是实现云计算服务的基础
- 连续监测、错误探测、容错和自动恢复
- 针对吉字节、太字节的文件设计,I/O操作、块大小等参数需针对性设置
- 文件的更新通常是附加新的数据,而不是覆盖现有的数据。文件内的随机写操作几乎不会发生
- 对应用程序和文件系统API协同设计,增加系统灵活性
体系结构:一个GFS集群含有单个主控服务器(master),多个快服务器(chunk server),被多个客户(client)访问 图TODO
读写操作:图TODO
NoSQL数据库BigTable:(HBase的参考)
…
Chubby(锁管理器)是Google设计的提供粗粒度锁服务的一个文件系统,它基于松耦合分布式系统,解决了分布的一致性问题
paxos算法
分布式并行计算模型 MapReduce:(MapReduce的参考)
图TODO
为什么从后端开发转运维开发?公司间选择看重什么?
- 推力方面,职业认可感和未来预期,工作内容,想尽早入行。
- 阻力方面,目前听说过的缺点与推力相比都能接受:夜班值班/随时待命,薪资低,线上事故的压力,工作琐碎。
看重的地方,答了工作内容。其实还有技术氛围。
有关大数据运维
挑一部分内容上传
工作的主要内容,需要的基础?大数据组件怎么跑的?
对应前面考察内容,日常工作:
- Linux基础:分析系统上的问题
- Python开发:运维工具开发
- Hadoop、k8s组件原理:与遇到问题有关的技术点,为了去部署它或扩容它,或是分析追查问题。追查原因,集群的管理,机器的报修,机器的上下线,服务的发布等
做组建集群的维护管理,比如说上万台机器,一套Hadoop或一套k8s(将Hadoop部署在k8s上是可以的,但是我们这边选择不这么做)
工作内容:
- 故障处理、事前发现
- 资源监控
- 运维效率提升
- 标准化治理
(后一问不上传了)
五年运维vs新手运维,提升的方向?年龄对运维的影响?
- 工作范围变大:比如机房迁移的方案(复杂模糊任务拆出具体清晰方案,考虑各种问题)
- 技术难度:在三个领域持续积累
- (很详细又有些个性化的举例,不上传了,都来面!)
在公司/部门的位置,对接的角色?组内?
(不上传了)
夜班频率?on-call?白天工作时长和任务量?
(具体不上传了,24h on-call 5-6次/月)
如何学/看哪里学?
开源社区会议
二面忘问这个问题,有点可惜
运维的笔记库?
再次遇到同样BUG时能快速找到就行。灾备(如果电脑坏了)。
计划 Actions to Take
目前宽度上应该够用了,提到的内容多少都摸过;这次面完知道哪些方面是大数据运维需要的,以及关注点该放如何放;现在可以较安全地选择复习内容,以及向深度去走。下面主要走两方面,根据这次问到的运维知识需求:
- 把过往笔记分类、挑选对未来有价值的复习,挑选有技术深度的遇到的问题记录上传博客
- 梳理模糊不清、和为了省时间跳过的地方,挑选k8s docs相关内容结合实操去理解
Check List 按大致先后顺序:
-
以k8s发布、扩缩容的主要工作流程为线索梳理(k8s docs 未找到整体流程图,但各个组件有细节描述,自己理解下实验下),留意架构、故障时预期表现
- 认证。RBAC,也许再加NetworkPolicy,secret等?
-
结合RedHat 442性能调优课程,复习OS知识 -> 开始投递简历
-
论文实验待修改
-
有条理地把本科所学分布式/大数据知识点捋一遍。复习YARN论文,谷歌三大论文,毕设涉及的大数据相关组件的原理
(不知道分布式理论、模型会不会对运维有帮助… 不需要设计算法应该用不太上
-
每周1题Python算法找回手感
-
留意单点容灾、机房容灾的架构设计,各种预案


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









