







spring加载过程
spring主要是用来管理bean的,spring的加载过程,也就是bean的加载过程,ApplicationContext和BeanFacotry都是用于加载bean的,ApplicationContext提供了更多的扩展功能,BeanFacotry是ApplicationContext的其中一个环节,具体过程如下:
读取配置文件、解析配置文件、注册bean、获取bean(单例bean会先从缓存加载,没有就实例化一个)
spring循环依赖
获取bean的过程是最复杂的,其中就会涉及到循环依赖的问题,构造器循环依赖无法解决;setter循环依赖通过提前暴露刚完成构造器注入但未完成其他步骤的bean来解决,但只能解决单例作用域的,通过提前暴露一个单例工厂方法,从而使其他bean能引用到该bean。
Spring的循环依赖的理论依据基于Java的引用传递,当获得对象的引用时,对象的属性是可以延后设置。
Spring的单例对象的初始化主要分为三步:
- createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象
- populateBean:填充属性,这一步主要是对bean的依赖属性进行填充
- initializeBean:调用spring xml中的init 方法。
从上面单例bean的初始化可以知道:循环依赖主要发生在第一、二步,也就是构造器循环依赖和setter循环依赖。对于单例来说,在Spring容器整个生命周期内,有且只有一个对象,并且这个对象存在Cache中,Spring为了解决单例的循环依赖问题,使用了三级缓存:
- singletonFactories : 三级缓存,单例对象工厂的cache ,执行了第一步的对象
- earlySingletonObjects :二级缓存,提前暴光的单例对象的Cache
- singletonObjects:一级缓存,单例对象的cache,完全的对象(初始化三步全部完成的)
在创建bean的时候,首先从singletonObjects中获取这个单例的bean。如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects中获取。如果还是获取不到且允许singletonFactories通过getObject()获取,就从三级缓存singletonFactory.getObject()获取,如果获取到了则从singletonFactories中移除,并放入二级缓存earlySingletonObjects中。其实也就是从三级缓存移动到了二级缓存。
Spring解决循环依赖的诀窍就在于singletonFactories这个三级cache。这个cache的类型是ObjectFactory。这里就是解决循环依赖的关键,发生在createBeanInstance之后,也就是说单例对象此时已经被创建出来(调用了构造器)。这个对象已经被生产出来了,虽然还不完美(还没有进行初始化的第二步和第三步),但是已经可以根据对象引用能定位到堆中的对象,所以Spring此时将这个对象提前曝光出来使用。
例如以下场景,“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。A首先完成了初始化的第一步,并且将自己提前曝光到三级缓存singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进入了一级缓存singletonObjects中。
其中,构造器和prototype范围的循环依赖无法解决。
因为加入singletonFactories三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决,会抛出BeanCurrentlyInCreationException异常
对于prototype作用域bean,因为Spring容器不进行缓存prototype作用域的bean,因此无法提前暴露一个创建中的bean,所以prototype范围的循环依赖无法解决。
数据库的隔离级别,怎么解决幻读
未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
数据库一般都不会用,而且任何操作都不会加锁
提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)数据的读取都是不加锁的,但是数据的写入、修改和删除是需要加锁的
可重复读(Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读
这是MySQL中InnoDB默认的隔离级别,可重读这个概念是一事务的多个实例在并发读取数据时,会看到同样的数据行,使用了MVCC来实现的
在可重复读中,该sql第一次读取到数据后,就将这些数据加锁,其它事务无法修改这些数据,就可以实现可重复读了。但这种方法却无法锁住insert的数据,所以当事务A先前读取了数据,或者修改了全部数据,事务B还是可以insert数据提交,这时事务A就会发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免。
MySQL、ORACLE、PostgreSQL等成熟的数据库,出于性能考虑,都是使用了以乐观锁为理论基础的MVCC(多版本并发控制)来避免幻读问题。
串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
select * from table where acName = 'test' for update 是否用了索引,是否用了锁
在 MySQL 中,如果查询条件带有主键索引,会锁行数据;如果条件不是索引键,会锁表。未查到数据则无锁,属于排他锁,其他请求只能查询
对象逃逸
在方法中创建对象之后,如果这个对象除了在方法体中还在其它地方被引用了,此时如果方法执行完毕,由于该对象有被引用,所以 GC 有可能是无法立即回收的,此时便成为 内存逃逸现象。
逃逸 是一个动词,比如 A 从 B 中逃逸,那么此时这个 A 指的就是方法中创建的对象,B 指的就是这个方法体,即可以简单理解成这个对象逃逸出这个方法体。
逃逸分析
逃逸分析(Escape Analysis)简单来讲就是,Java Hotspot 虚拟机可以分析新创建对象的使用范围,并决定是否在 Java 堆上分配内存的一项技术。
jdk1.8默认开启
开启逃逸分析,对象没有分配在堆上,没有进行GC,而是把对象分配在栈上。
关闭逃逸分析,对象全部分配在堆上,当堆中对象存满后,进行多次GC,导致执行时间大大延长。堆上分配比栈上分配慢上百倍。
CMS垃圾回收
1.CMS-initial-mark 初始标记(CMS的第一个STW阶段),标记GC Root直接引用的对象,GC Root直接引用的对象不多,所以很快。
2.CMS-concurrent-mark 并发标记阶段,由第一阶段标记过的对象出发,所有可达的对象都在本阶段标记。
3.CMS-concurrent-preclean/Rescan (parallel) 并发预清理阶段,也是一个并发执行的阶段。在本阶段,会查找前一阶段执行过程中,从新生代晋升或新分配或被更新的对象。通过并发地重新扫描这些对象,预清理阶段可以减少下一个stop-the-world 重新标记阶段的工作量。
4.CMS-concurrent-abortable-preclean 并发可中止的预清理阶段。这个阶段其实跟上一个阶段做的东西一样,也是为了减少下一个STW重新标记阶段的工作量。增加这一阶段是为了让我们可以控制这个阶段的结束时机,比如扫描多长时间(默认5秒)或者Eden区使用占比达到期望比例(默认50%)就结束本阶段。
5.CMS-remark 重标记阶段(CMS的第二个STW阶段),暂停所有用户线程,从GC Root开始重新扫描整堆,标记存活的对象。需要注意的是,虽然CMS只回收老年代的垃圾对象,但是这个阶段依然需要扫描新生代,因为很多GC Root都在新生代,而这些GC Root指向的对象又在老年代,这称为“跨代引用”。
6.CMS-concurrent-sweep ,并发清理。
7.CMS-concurrent-reset,重置。
2020-03-08T01:09:46.390+0800: 6253.734: [GC [1 CMS-initial-mark: 1945758K(2097152K)] 2079340K(11084992K), 0.1071190 secs] [Times: user=0.11 sys=0.00, real=0.11 secs]
2020-03-08T01:09:46.499+0800: 6253.842: [CMS-concurrent-mark-start]
2020-03-08T01:09:47.188+0800: 6254.531: [CMS-concurrent-mark: 0.689/0.689 secs] [Times: user=4.31 sys=0.52, real=0.69 secs]
2020-03-08T01:09:47.189+0800: 6254.532: [CMS-concurrent-preclean-start]
2020-03-08T01:09:47.212+0800: 6254.555: [CMS-concurrent-preclean: 0.021/0.023 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
2020-03-08T01:09:47.212+0800: 6254.555: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 2020-03-08T01:09:52.995+0800: 6260.338: [CMS-concurrent-abortable-preclean: 5.762/5.782 secs] [Times: user=24.38 sys=2.73, real=5.79 secs]
2020-03-08T01:09:53.092+0800: 6260.435: [Rescan (parallel) , 0.0388170 secs]2020-03-08T01:09:53.131+0800: 6260.474: [weak refs processing, 0.0000360 secs]2020-03-08T01:09:53.131+0800: 6260.474: [scrub string table, 0.0219010 secs] [1 CMS-remark: 1949195K(2097152K)] 2116443K(11084992K), 0.1540610 secs] [Times: user=0.93 sys=0.01, real=0.15 secs]
2020-03-08T01:09:53.154+0800: 6260.497: [CMS-concurrent-sweep-start]
2020-03-08T01:09:55.067+0800: 6262.410: [CMS-concurrent-sweep: 1.913/1.913 secs] [Times: user=9.52 sys=1.15, real=1.91 secs]
2020-03-08T01:09:55.068+0800: 6262.411: [CMS-concurrent-reset-start]
2020-03-08T01:09:55.080+0800: 6262.423: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.08 sys=0.01, real=0.01 secs] G-1回收过程、回收算法
G1也有类似CMS的收集动作:初始标记、并发标记、重新标记、清除、转移回收,并且也以一个串行收集器做担保机制。
G1的设计原则是"首先收集尽可能多的垃圾(Garbage First)"。因此,G1并不会等内存耗尽(串行、并行)或者快耗尽(CMS)的时候开始垃圾收集,而是在内部采用了启发式算法,在老年代找出具有高收集收益的分区进行收集。同时G1可以根据用户设置的暂停时间目标自动调整年轻代和总堆大小,暂停目标越短年轻代空间越小、总空间就越大;
G1采用内存分区(Region)的思路,将内存划分为一个个相等大小的内存分区,回收时则以分区为单位进行回收,存活的对象复制到另一个空闲分区中。由于都是以相等大小的分区为单位进行操作,因此G1天然就是一种压缩方案(局部压缩);
G1虽然也是分代收集器,但整个内存分区不存在物理上的年轻代与老年代的区别,也不需要完全独立的survivor(to space)堆做复制准备。G1只有逻辑上的分代概念,或者说每个分区都可能随G1的运行在不同代之间前后切换
G1的收集都是STW的,但年轻代和老年代的收集界限比较模糊,采用了混合(mixed)收集的方式。即每次收集既可能只收集年轻代分区(年轻代收集),也可能在收集年轻代的同时,包含部分老年代分区(混合收集),这样即使堆内存很大时,也可以限制收集范围,从而降低停顿
在每个分区内部又被分成了若干个大小为512 Byte卡片(Card),标识堆内存最小可用粒度,所有分区的卡片将会记录在全局卡片表(Global Card Table)中,分配的对象会占用物理上连续的若干个卡片,当查找对分区内对象的引用时,便可通过记录卡片来查找该引用对象(见RSet)。每次对内存的回收,都是对指定分区的卡片进行处理
当空间不足,如对象空间分配或转移失败时,G1会首先尝试增加堆空间,如果扩容失败,则发起担保的Full GC。Full GC后,堆尺寸计算结果也会调整堆空间
在串行和并行收集器中,GC通过整堆扫描,来确定对象是否处于可达路径中。然而G1为了避免STW式的整堆扫描,在每个分区记录了一个已记忆集合(RSet),内部类似一个反向指针,记录引用分区内对象的卡片索引。当要回收该分区时,通过扫描分区的RSet,来确定引用本分区内的对象是否存活,进而确定本分区内的对象存活情况
事实上,并非所有的引用都需要记录在RSet中,如果一个分区确定需要扫描,那么无需RSet也可以无遗漏的得到引用关系。那么引用源自本分区的对象,当然不用落入RSet中;同时,G1 GC每次都会对年轻代进行整体收集,因此引用源自年轻代的对象,也不需要在RSet中记录。最后只有老年代的分区可能会有RSet记录,这些分区称为拥有RSet分区(an RSet’s owning region)
年轻代,复制算法回收,stw,Young GC主要是对Eden区进行GC,它在Eden空间耗尽时会被触发。在这种情况下,Eden空间的数据移动到Survivor空间中,如果Survivor空间不够,Eden空间的部分数据会直接晋升到年老代空间。Survivor区的数据移动到新的Survivor区中,也有部分数据晋升到老年代空间中。最终Eden空间的数据为空,GC停止工作,应用线程继续执行
可参考:https://blog.csdn.net/qqqqq1993qqqqq/article/details/71882733?spm=1001.2101.3001.6650.11&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ELandingCtr%7Edefault-11.queryctr&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ELandingCtr%7Edefault-11.queryctr&utm_relevant_index=17
年轻代GC,老年代并发标记过程,混合回收
应用程序分配内存,当年轻代的Eden区用尽时开始年轻代回收过程; G1的年轻代收集阶段是一个并行的独占式收集器。在年轻代回收期,G1 GC暂停所有应用程序线程,启动多线程执行年轻代回收。然后从年轻代区间移动存活对象到Survivor区间或者老年区间,也有可能是两个区间都会涉及。
当堆内存使用达到一定值(默认45%)时,开始老年代并发标记过程。
标记完成马上开始混合回收过程。对于一个混合回收期,G1 GC从老年区间移动存活对象到空闲区间,这些空闲区间也就成为了老年代的一部分。和年轻代不同,老年代的G1回收器和其他Gc不同,G1的老年代回收器不需要整个老年代被回收,一次只需要扫描/回收一小部分老年代的Region就可以了。同时,这个老年代Region是和年轻代一起 被回收的。
G1回收过程一:年轻代GC
JVM启动时,G1先准备好Eden区,程序在运行过程中不断创建对象到Eden区,当Eden空间耗尽时,G1会启动- -次年轻代垃圾回收过程。
YGC时,首先G1停止应用程序的执行(Stop-The-World) ,G1创建回收集(Collection Set) ,回收集是指需要被回收的内存分段的集合,年轻代回收过程的回收集包含年轻代Eden区和Survivor区所有的内存分段。
第一阶段,扫描根。
根是指static变量指向的对象,正在执行的方法调用链条上的局部变量等。根引用连同RSet记录的外部引用作为扫描存活对象的入口。
第二阶段,更新RSet.
处理dirty card queue( 见备注)中的card,更新RSet。此阶段完成后,RSet可以准确的反映老年代对所在的内存分段中对象的引用。
第三阶段,处理RSet.
识别被老年代对象指向的Eden中的对象,这些被指向的Eden中的对象被认为是存活的对象。
第四阶段,复制对象。
此阶段,对象树被遍历,Eden区内存段中存活的对象会被复制到Survivor区中空的内存分段Survivor区内存段中存活的对象如果年龄未达阈值,年龄会加1,达到阀值会被会被复制到01d区中空的内存分段。如果Survivor空间不够,Eden空 间的部分数据会直接晋升到老年代空间。
第五阶段,处理引用。
处理Soft,Weak,Phantom, Final, JNI Weak 等引用。最终Eden空间的数据为空,GC停止工作,而目标内存中的对象都是连续存储的,没有碎片,所以复制过程可以达到内存整理的效果,减少碎片。
G1回收过程二:并发标记过程
初始标记阶段:标记从根节点直接可达的对象。这个阶段是STW的并且会触发一次年轻代GC。
根区域扫描(Root Region Scanning) : G1 GC扫描Survivor区直接可达的老年代区域对象,并标记被引用的对象。这一过程必须在young GC之前完成。
并发标记(Concurrent Marking): 在整个堆中进行并发标记(和应用程序并发执行),此过程可能被young GC中断。在并发标记阶段,若发现区域对象中的所有对象都是垃圾,那这个区域会被立即回收。同时,并发标记过程中,会计算每个区域的对象活性(域中存活对象的比例)。
再次标记(Remark):由 于应用程序持续进行,需要修正上一次的标记结果。是STW的。G1中采用了比CMS更快的初始快照算法: snapshot-at-the-beginning (SATB)。
独占清理(cleanup ,STW):计算各个区域的存活对象和GC回收比例,并进行排序,识别可以混合回收的区域。为下阶段做铺垫。是STW的。这个阶段并不会实际上去做垃圾的收集
并发清理阶段:识别并清理完全空闲的区域。
G1回收过程三:混合回收
当越来越多的对象晋升到老年代oldregion时,为了避免堆内存被耗尽,虚拟机会触发一个混合的垃圾收集器即Mixed GC, 该算法并不是一个oldGC,除了回收整个Young Region,还会回收一部分的0ld Region。 这里需要注意:是一部分老年代,而不是全部老年代。可以选择哪些0ldRegion进行收集,从而可以对垃圾回收的耗时时间进行控制。也要注意的是Mixed GC并不是Full GC。
并发标记结束以后,老年代中百分百为垃圾的内存分段被回收了,部分为垃圾的内存分段被计算了出来。默认情况下,这些老年代的内存分段会分8次(可以通过-XX:G1MixedGCCountTarget设置)被回收。
混合回收的回收集( Collection Set)包括八分之一的老年代内存分段,Eden区内存分段,Survivor区内存分段。混合回收的算法和年轻代回收的算法完全-一样,只回集多了老年代的内存分段。具体过程请参考上面的年轻代回收过程。
由于老年代中的内存分段默认分8次回收,G1会优先回收垃圾多的内存分段。垃圾占内存分段比例越高的,越会被先回收。并且有一个阈值会决定内存分段是否被回收,-Xx: G1Mi xedGCLiveThresholdPercent,默认为65%,意思是垃圾占内存分段比例要达到65%才会被回收。如果垃圾占比太低,意味着存活的对象占比高,在复制的时候会花费更多的时间。
混合回收并不一定要进行8次。有一个阈值-XX: G1HeapWastePercent,默认值为10%,意思是允许整个堆内存中有10%的空间被浪费,意味着如果发现可以回收的垃圾占堆内存的比例低于10%,则不再进行混合回收。因为GC会花费很多的时间但是回收到的内存却很少。
jdk1.8对内存做了哪些优化
JDK1.8时,移除了方法区的概念,用一个元数据区代替。元数据区存放的东西和方法区相同,不过元数据区移动到本地内存中。本地内存(直接内存)就是指机器内存中不是JVM管理的那部分内存,由操作系统管理。元数据区移动到本地内存以后,可以避免虚拟机加载类过多而引发的内存溢出:java.lang.OutOfMemoryError: PermGen,但是同样不能无限扩展
线程上下文类加载器
JDBC 相关的这些接口,在启动的时候,是由启动类加载器(boost classLoader)去加载的。
而通常,我们会将数据库厂商提供的 jar 包放置在 classPath 下,由此可知,数据库厂商所提供的实现类不会由启动类加载器来去加载,它们通常是由系统类加载器来去加载的。
这样一来,接口是有启动类加载器加载的,而具体的实现是由应用类加载器加载的。根据类的双亲委托原则,父加载器所加载的类/接口是看不到子加载器所加载的类/接口的,而然,子加载器所加载的类/接口是能够看到父加载器的类/接口的。这样的话,会导致这样一个局面:JDBC 相关的代码可能还需要去调用具体实现类中的代码,但是它是无法看到具体的实现类的(因为是由其子加载器加载的)。
而这个问题,不仅是在 JDBC 中出现,在 JNDI、xml解析,等场景下都会出现。
总结来说,在 SPI 这种场合下都会出现的问题。
每个类都会使用自己的类加载器(即,加载自身的类加载器)来去加载其他的类(指的是所依赖的类),如果 ClassX 引用了 ClassY,那么 ClassX 的类加载器就会去加载 ClassY(前提是 ClassY 尚未被加载)
当高层提供了统一的接口让低层去实现,同时又要在高层加载(或实例化)低层的类时,就必须要通过线程上下文类加载器来帮助高层的 ClassLoader 找到并加载该类。
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现
Mybatis二级缓存
一级缓存
Mybatis的一级缓存是指Session缓存。一级缓存的作用域默认是一个SqlSession。Mybatis默认开启一级缓存。
也就是在同一个SqlSession中,执行相同的查询SQL,第一次会去数据库进行查询,并写到缓存中;
第二次以后是直接去缓存中取。
当执行SQL查询中间发生了增删改的操作,MyBatis会把SqlSession的缓存清空。
一级缓存的范围有SESSION和STATEMENT两种,默认是SESSION,如果不想使用一级缓存,可以把一级缓存的范围指定为STATEMENT,这样每次执行完一个Mapper中的语句后都会将一级缓存清除。
二级缓存
Mybatis的二级缓存是指mapper映射文件。二级缓存的作用域是同一个namespace下的mapper映射文件内容,多个SqlSession共享。Mybatis需要手动设置启动二级缓存。
二级缓存是默认启用的(要生效需要对每个Mapper进行配置),如想取消,则可以通过Mybatis配置文件中的元素下的子元素来指定cacheEnabled为false。
mysql索引为什么用B+树,而不是B树
-
索引是帮助MySQL高效获取数据的排好序的数据结构
-
索引数据结构
- 二叉树
- 红黑树
- Hash表
- B-Tree
-
索引的建立就是数据排序的过程
为什么二叉树不适合做索引
- 因为当数据在插入的数据,如果是排好序的,二叉树则会退化成链表,这样就失去了索引的意义。特别是自增主键,默认就是会建索引的。
为什么红黑树不适合做索引
- 因为红黑树是弱平衡树,如果插入的数据是排好序的,则只会单边增长,查询效率依然不高效。特别是自增数据量大的时候,高度非常大。

为什么Hash表不适合做索引
- 哈希表对于范围查找和排序效率低,但对于单个数据的查询效率很高。
B-Tree结构
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
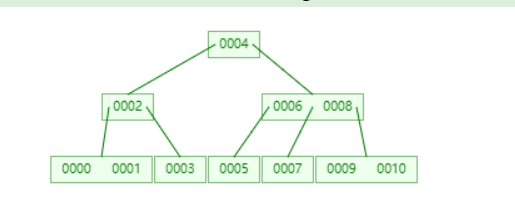
B+Tree结构
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针链接,提高区间访问性能

MySQL 为什么使用 B+ 树来作索引
-
由于mysql通常将数据存放在磁盘中,读取数据就会产生磁盘IO消耗。而B+树的非叶子节点中不保存数据,B树中非叶子节点会保存数据,通常一个节点大小会设置为磁盘页大小,这样B+树每个节点可放更多的key,B树则更少。这样就造成了,B树的高度会比B+树更高,从而会产生更多的磁盘IO消耗。
-
B+树叶子节点构成链表,更利用范围查找和排序。而B树进行范围查找和排序则要对树进行递归遍历
B树与B+树比较
- B+树层级更少,查找更快
- B+树查询速度稳定:由于B+树所有数据都存储在叶子节点,所以查询任意数据的次数都是树的高度h
- B+树有利于范围查找
- B+树全节点遍历更快:所有叶子节点构成链表,全节点扫描,只需遍历这个链表即可
- B树优点:如果在B树中查找的数据离根节点近,由于B树节点中保存有数据,那么这时查询速度比B+树快
分布式锁
redis单分片锁
SET resource_name my_random_value NX 30000
最后通过Lua脚本来释放锁
单分片锁有个缺点:
假如Redis节点宕机了,那么所有客户端就都无法获得锁了,服务变得不可用。为了提高可用性,我们可以给这个Redis节点挂一个Slave,当Master节点不可用的时候,系统自动切到Slave上(failover)。但由于Redis的主从复制(replication)是异步的,这可能导致在failover过程中丧失锁的安全性。
1、客户端1从Master获取了锁。
2、Master宕机了,存储锁的key还没有来得及同步到Slave上。
3、Slave升级为Master。
4、客户端2从新的Master获取到了对应同一个资源的锁。
多分片锁Redlock
运行Redlock算法的客户端依次执行下面各个步骤,来完成获取锁的操作:
1、获取当前时间(毫秒数)。
2、按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。
计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
3、如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
4、如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
当然,上面描述的只是获取锁的过程,而释放锁的过程比较简单:客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。
但也并不完美:
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
1、客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
2、节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
3、节点C重启后,客户端2锁住了C, D, E,获取锁成功。
这样,客户端1和客户端2同时获得了锁
redlock的官方实现,java版本是Redisson,官方地址:REDIS distlock -- Redis中国用户组(CRUG)![]() http://redis.cn/topics/distlock.html
http://redis.cn/topics/distlock.html
总之没有完美的锁,就算是使用ZooKeeper分布式锁,可靠性提高了,但是性能就没有那么客观了,只要能满足业务的需求,就是好锁。
Java内存模型
模型定义

Java内存模型规定了所有的变量都存储在主内存中。每个线程还有自己的工作内存,线程的工作内存中保存了被该线程使用的变量的主内存副本,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存的数据。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
这里的主内存、工作内存与Java内存区域中的Java堆、栈、方法区等并不是同一个层次的对内存的划分,这两者基本是没有任何关系的,如果一定要对应起来,主内存主要对应于Java堆中的对象实例部分,而工作内存则对应于虚拟机栈中的部分区域。从更基础的层次上来说,主内存直接对应物理硬件的内存,为了获取更好的运行速度,虚拟机(或者是硬件、操作系统本身的优化措施)可能会让工作内存优先存储于寄存器和高速缓存中,程序运行时主要访问的时工作内存。
内存间的交互
主内存与工作内存之间的具体交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步到主内存之间的实现细节,Java内存模型定义了以下八种操作来完成:
- lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占状态。
- unlock(解锁):作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
- use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
- write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
Java内存模型还规定了在执行上述八种基本操作时,必须满足如下规则:
- 如果要把一个变量从主内存中复制到工作内存,就需要按顺寻地执行read和load操作, 如果把变量从工作内存中同步回主内存中,就要按顺序地执行store和write操作。但Java内存模型只要求上述操作必须按顺序执行,而没有保证必须是连续执行。
- 不允许read和load、store和write操作之一单独出现
- 不允许一个线程丢弃它的最近assign的操作,即变量在工作内存中改变了之后必须同步到主内存中。
- 不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内存中。
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量。即就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作。
- 一个变量在同一时刻只允许一条线程对其进行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。lock和unlock必须成对出现
- 如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值
- 如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去unlock一个被其他线程锁定的变量。
- 对一个变量执行unlock操作之前,必须先把此变量同步到主内存中(执行store和write操作)。
volatile变量
关键字volatile是Java虚拟机提供的最轻量级的同步机制,Java内存模型专门为volatile定义了一些特殊的访问规则。
当一个变量被定义成volatile之后,它将具备两项特性:
第一项是保证此变量对所有线程的可见性
当一个线程改变了这个变量的值,新值对其他线程来说是立即可知的。普通变量不能做到这一点,普通变量的值在线程间传递时,均需通过主内存来完成。比如,线程A修改一个普通变量的值,然后向主内存进行回写,另外一个线程B在线程A回写完成之后,再对主内存进行读操作,新变量值才会对线程B可见。
volatile变量在各个线程的工作内存中是不存在一致性问题的,但是volatile变量在并发下的运算仍然是不安全的,因为Java里面的运算操作符并非原子操作。
public class VolatileTest {
public static volatile int race = 0;
public static void increase() {
race++;
}
private static final int THREADS_COUNT = 20;
public static void main(String[] args) {
Thread[] threads = new Thread[THREADS_COUNT];
for (int i = 0; i < THREADS_COUNT; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
increase();
}
}
});
threads[i].start();
}
// 等待所有累加线程都结束
while (Thread.activeCount() > 1)
Thread.yield();
System.out.println(race);
}
}这段代码发起了20个线程,每个线程对race进行10000次自增操作,如果这段代码能够正确并发的话,最后输出的结果应该是200000,但是实际上每次运行的结果都不一样,都是一个小于200000的数字。问题就出在race++自增运算中,自增运算包含了三个操作,先获取最新的值,在加一,再赋值,当进行后两个操作的时候,可能值已经被其他线程改变了,volatile只能保证获取这一步操作得到的是最新的值。
第二个语义是禁止指令重排序优化
下面这段话摘自《深入理解Java虚拟机》:
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
Java内存模型对volatile变量定义的特殊规则
1、每次使用volatile变量前,都必须先从主存刷新最新的值,用于保证能看见其他线程对volatile变量做的修改。
2、每次修改volatile变量后都必须立刻同步回主内存中,以保证其他线程可以看到自己对volatile变量的修改。
3、volatile修饰的变量不会被指令重排序优化,从而保证代码的执行顺序与程序的顺序相同。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









