







背景
在一次性能调优中,本来使用的是默认的GC,这里是jdk1.8,年轻代使用的是Parallel Scavenge收集器,老年代使用的是Parallel Old 收集器,后面申请的机器配置降低了一半:2C4G,这时候会发现堆内存会一直增长。

直至触发full gc,再开始下一轮,如此往复,看下tp999。

基本和GC保持一致,看下Parallel Scavenge收集器的回收策略:
当整个新生代剩余的空间无法存放某个对象时,Parallel Scavenge/Parallel Old中该对象会直接进入老年代。而如果整个新生代剩余的空间可以存放但只是Eden区空间不足,则会尝试一次Minor GC。
通过jmap下载堆内存快照,可以看到老年代使用率越来越高,说明有很多对象直接进入了老年代。其实对于大内存的话,这种情况基本不会出现。
CMS收集器模式
使用-XX:+UseConcMarkSweepGC打开CMS收集器模式,这时候,新生代是ParNew收集器,老年是CMS收集器。这里没有显式的指定新生代的大小,看下切换后效果。
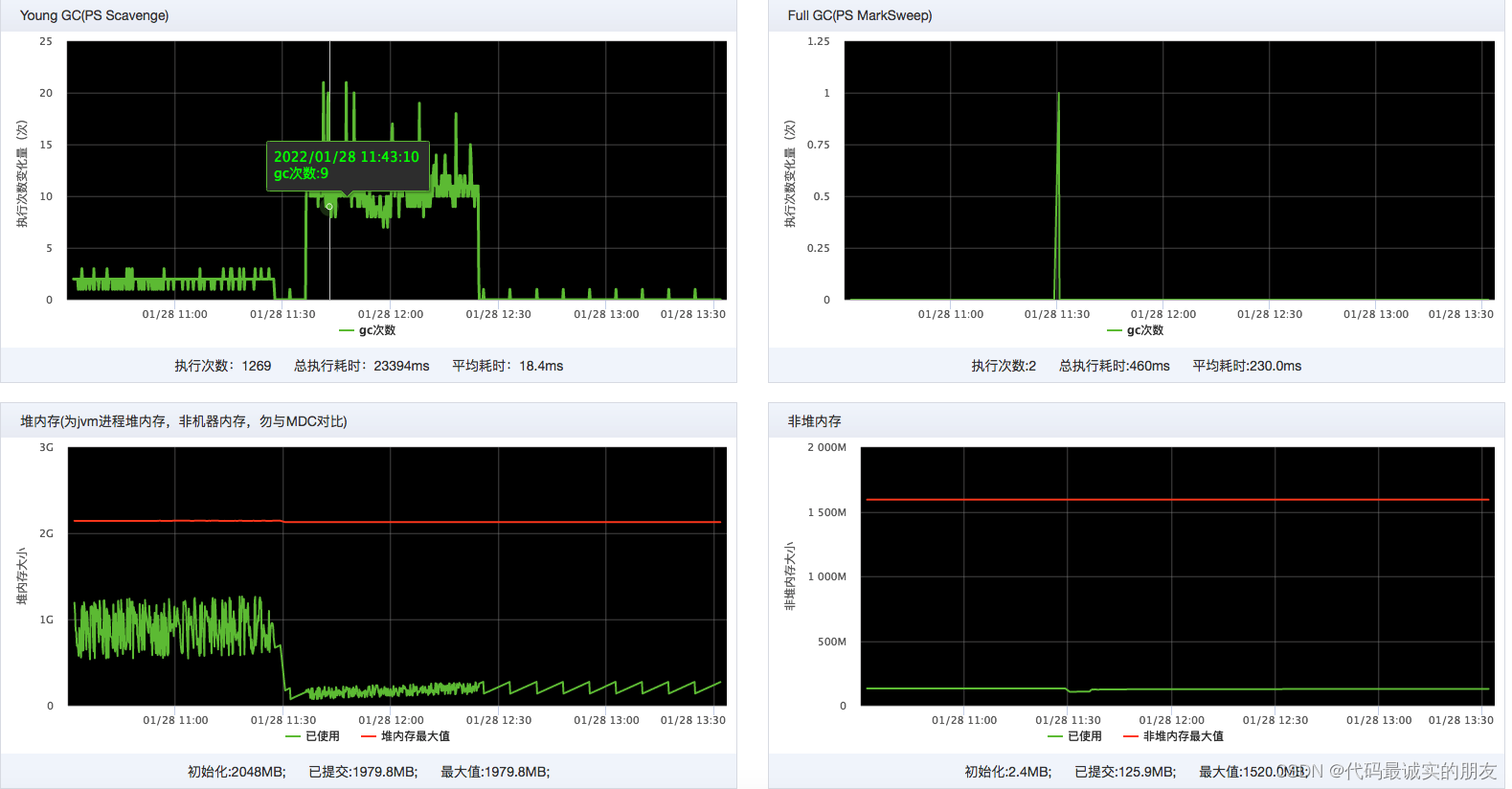
可以看到,中间这段,年轻代gc变的很频繁,并且堆内存使用率也很小,jmap下载堆内存快照,可以看到。
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GCHeap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 2147483648 (2048.0MB)
NewSize = 174456832 (166.375MB)
MaxNewSize = 174456832 (166.375MB)
OldSize = 1973026816 (1881.625MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 268435456 (256.0MB)
G1HeapRegionSize = 0 (0.0MB)
新生代大小只有166M,那么默认值不是说是NewRatio=2,那应该是堆内存的1/3啊,可事实并不是这样的,默认的情况下:
机器硬件决定(x86位64M)*并行线程数(-XX:ParallelGCThreads指定的值)*13 / 10
具体可参考源码,这里有篇文章介绍:CMS GC 默认新生代是多大? - 简书CMS GC 默认新生代是多大? 简书 涤生[https://www.jianshu.com/users/150f36a73910/]。转载请注明原创出处,谢谢!如果读完觉得...https://www.jianshu.com/p/832fc4d4cb53
按照这个公式,64M*2*13/10=166.4M,哪确实和事实相符,所以我们在使用CMS收集器模式时,一定要指定新生代的大小,完整参数如下:
-XX:+UseConcMarkSweepGC -XX:NewRatio=2 -XX:ParallelGCThreads=2 -XX:CICompilerCount=2
这几个参数是必须的。
jdk1.8默认收集器模式
看下jdk1.8默认收集器模式下的新生代大小,也就是年轻代使用的是Parallel Scavenge收集器,老年代使用的是Parallel Old收集器的情况。
using thread-local object allocation.
Parallel GC with 43 thread(s)Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 1431306240 (1365.0MB)
MaxNewSize = 1431306240 (1365.0MB)
OldSize = 2863661056 (2731.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 268435456 (256.0MB)
G1HeapRegionSize = 0 (0.0MB)
我这里是看的4C8G的docker的。
CMS收集模式下的效果
在调整为CMS后,tp999性能确实好了,基本上运行一天左右,会触发一次full gc,由于是cms,所以stw对tp999基本没啥影响。

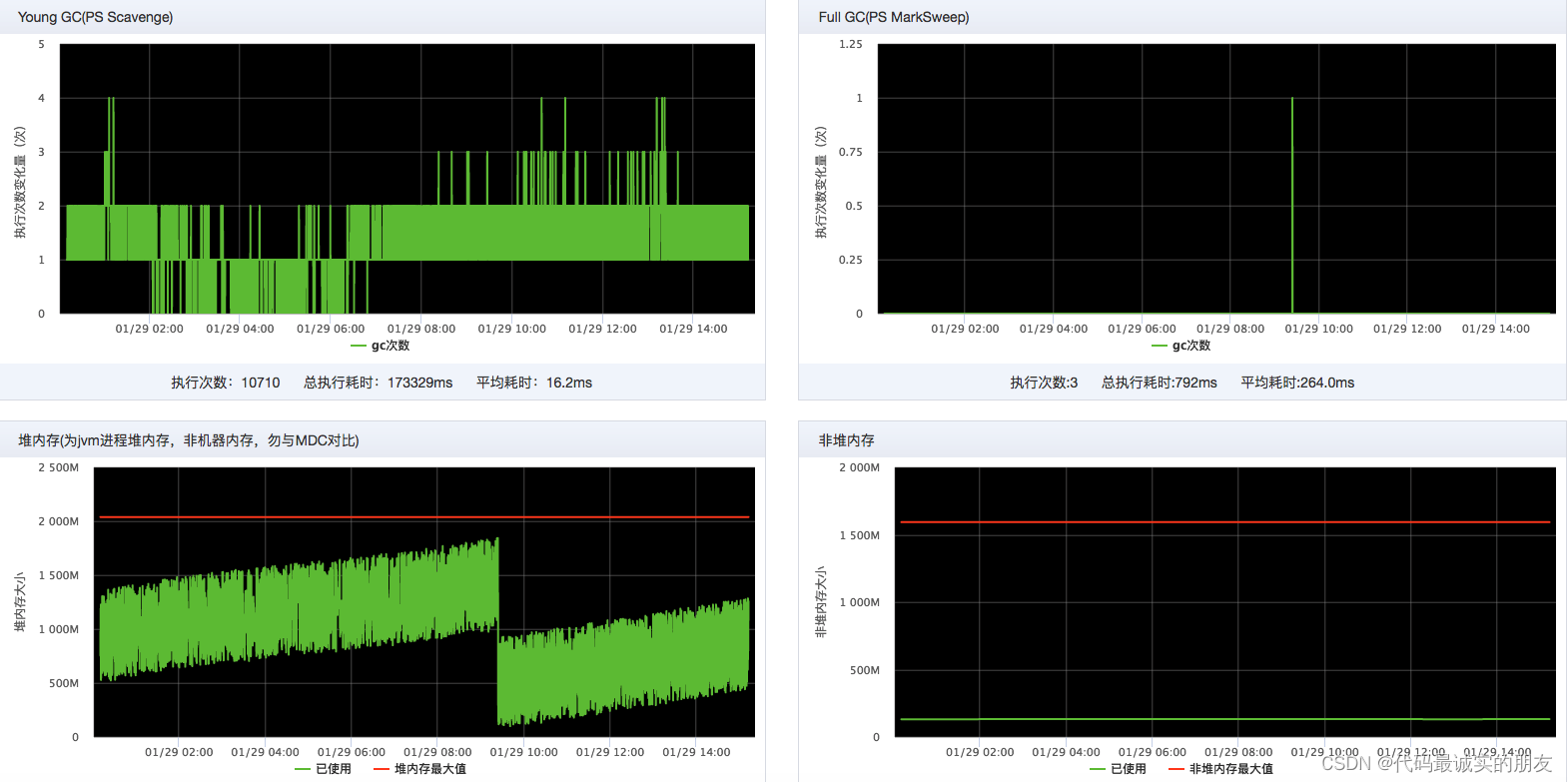
可以看到堆内存还是一直增长的,机器是2C4G,整个堆为2G,新生代给了1G,和之前的Parallel Scavenge + Parallel Old相比,性能是提升了,堆内存倒是没啥变化,通过jmap查看堆信息。
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 966393856 (921.625MB)
used = 689844152 (657.8866500854492MB)
free = 276549704 (263.7383499145508MB)
71.38333379470492% used
Eden Space:
capacity = 859045888 (819.25MB)
used = 688363664 (656.4747467041016MB)
free = 170682224 (162.77525329589844MB)
80.1311866590298% used
From Space:
capacity = 107347968 (102.375MB)
used = 1480488 (1.4119033813476562MB)
free = 105867480 (100.96309661865234MB)
1.3791486020489927% used
To Space:
capacity = 107347968 (102.375MB)
used = 0 (0.0MB)
free = 107347968 (102.375MB)
0.0% used
concurrent mark-sweep generation:
capacity = 1073741824 (1024.0MB)
used = 420112176 (400.6501922607422MB)
free = 653629648 (623.3498077392578MB)
39.125995337963104% used
堆内存一直增长,是因为老年代一直在增长,说明ygc后都有对象进入老年代,逐渐的老年代就越来越大了,哪这些对象是不是都是活跃对象呢,在每次full gc后,堆内存立马降了下来,说明大部分不是活跃对象,从目前看,最可能是过早晋升导致,ygc进行的很快,基本5-10s一次,这种情况下,需要调大新生代。再次调整,参数如下:
-Xms2048m -Xmx2048m -Xmn1500m -XX:+UseConcMarkSweepGC -XX:ParallelGCThreads=2 -XX:CICompilerCount=2 -XX:MaxMetaspaceSize=256m
关于gc调优推荐一篇文章:
后记
2G堆内存下,将新生代增加到1.5G,过早晋升现象有所缓解,但未能彻底解决,也就是还需要再次加大新生代,目前的这个比例,已经是常见的比例了,老年代太小,如果真有大量活跃对象,会导致频繁full gc,总是要留出一些buffer的,和4G堆内存相比,同样的比例,基本没有过早晋升的现象,并且tp999性能更好,这个时候,最好就是加资源了,如果能满足目前的业务,目前的配置也是合适的,毕竟合适的架构,才是好的架构,既满足了需求,也没有浪费资源,还是要考虑成本的。














 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









