







上篇:elasticsearch6实战教程学习笔记(十) — idea + Java实战 3 — 简单查询
本篇讲简单的聚合查询。
1 聚合查询
聚合查询年龄最大值,代码如下:
// 聚合查询
@Test
public void esAggregation() throws UnknownHostException {
// 指定es集群;查看 elasticsearch.yml -- put("cluster.name",集群名称)
Settings settings = Settings.builder().put("cluster.name","elastricsearch").build();
// 创建访问es服务器的客户端
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddresses(new TransportAddress(InetAddress.getByName("192.168.180.235"),9300));
// Aggregation:聚合查询最大值 - max。最小值:min。 均值:avg。 总和:sum。 基数:cardinality
AggregationBuilder builder = AggregationBuilders.max("ageMax").field("age");
SearchResponse response = client.prepareSearch("mauanx").addAggregation(builder).get();
// Min、Avg、Sum、Cardinality
Max max = response.getAggregations().get("ageMax");
// 输出结果
System.out.println("查询结果:");
System.out.println(max.getValue());
// 关闭客户端
client.close();
}
结果:
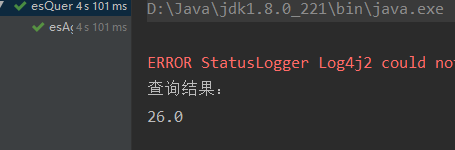
2 桶聚合
按年龄进行聚合,并统计结果。代码如下:
@Test
public void esAgg1() throws UnknownHostException {
// 指定es集群;查看 elasticsearch.yml -- put("cluster.name",集群名称)
Settings settings = Settings.builder().put("cluster.name","elastricsearch").build();
// 创建访问es服务器的客户端
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddresses(new TransportAddress(InetAddress.getByName("192.168.180.235"),9300));
// 按年龄聚合分组
AggregationBuilder builder = AggregationBuilders.terms("ageAgg").field("age");
SearchResponse response = client.prepareSearch("mauanx").addAggregation(builder).execute().actionGet();
// 聚合结果
Terms terms = response.getAggregations().get("ageAgg");
// 按分组进行统计
System.out.println("查询结果:");
for (Terms.Bucket t:terms.getBuckets()){
System.out.println(t.getKey() + ":" + t.getDocCount());
}
// 关闭客户端
client.close();
}
结果如下:
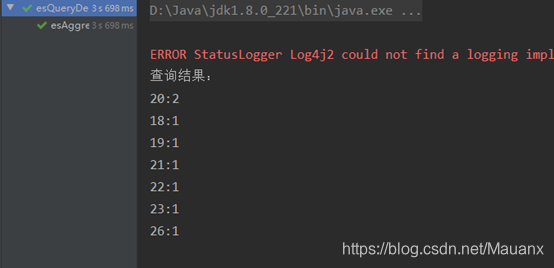
3 单条件过滤聚合
过滤条件为:age为20。
// 单条件过滤聚合
@Test
public void esAgg2() throws UnknownHostException {
// 指定es集群;查看 elasticsearch.yml -- put("cluster.name",集群名称)
Settings settings = Settings.builder().put("cluster.name","elastricsearch").build();
// 创建访问es服务器的客户端
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddresses(new TransportAddress(InetAddress.getByName("192.168.180.235"),9300));
// 过滤
AggregationBuilder builder = AggregationBuilders.filter("aggFilter",
QueryBuilders.termQuery("age",20));
SearchResponse response = client.prepareSearch("mauanx").addAggregation(builder).execute().actionGet();
// 过滤结果
Filter filter = response.getAggregations().get("aggFilter");
// 可以按过滤进行统计
System.out.println("查询结果:");
System.out.println(filter.getDocCount());
// 关闭客户端
client.close();
}
结果截图:
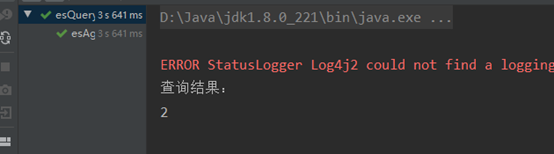
4 多条件过滤聚合
一共2个条件聚合:(1)“interests"为"sing”;(2)“interests"为"draw”。
// 多条件过滤聚合
@Test
public void esAgg3() throws UnknownHostException {
// 指定es集群;查看 elasticsearch.yml -- put("cluster.name",集群名称)
Settings settings = Settings.builder().put("cluster.name","elastricsearch").build();
// 创建访问es服务器的客户端
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddresses(new TransportAddress(InetAddress.getByName("192.168.180.235"),9300));
// 过滤
AggregationBuilder builder = AggregationBuilders.filters("aggFilters",
new FiltersAggregator.KeyedFilter("sing",QueryBuilders.termQuery("interests","sing")),
new FiltersAggregator.KeyedFilter("draw",QueryBuilders.termQuery("interests","draw")));
SearchResponse response = client.prepareSearch("mauanx").addAggregation(builder).execute().actionGet();
// 过滤结果
Filters filters = response.getAggregations().get("aggFilters");
// 可以按过滤进行统计
System.out.println("查询结果:");
for (Filters.Bucket f:filters.getBuckets()){
System.out.println(f.getKey() + ":" + f.getDocCount());
}
// 关闭客户端
client.close();
}
结果截图:
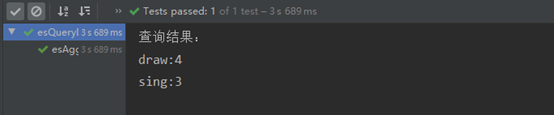
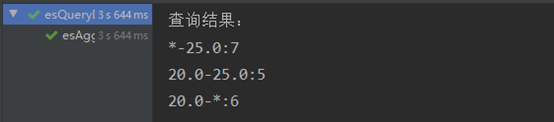
5 range范围聚合
查询age在25以下、20-25、20以上三个范围,并统计doc数量。
// range范围聚合
@Test
public void esAgg4() throws UnknownHostException {
// 指定es集群;查看 elasticsearch.yml -- put("cluster.name",集群名称)
Settings settings = Settings.builder().put("cluster.name","elastricsearch").build();
// 创建访问es服务器的客户端
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddresses(new TransportAddress(InetAddress.getByName("192.168.180.235"),9300));
// 过滤
AggregationBuilder builder = AggregationBuilders.range("aggRange").field("age")
.addUnboundedTo(25) // 下限-25
.addRange(20,25) // 20-25
.addUnboundedFrom(20); // 25-上限
SearchResponse response = client.prepareSearch("mauanx").addAggregation(builder).execute().actionGet();
// 过滤结果
Range ranges = response.getAggregations().get("aggRange");
// 可以按过滤进行统计
System.out.println("查询结果:");
for (Range.Bucket r:ranges.getBuckets()){
System.out.println(r.getKey() + ":" + r.getDocCount());
}
// 关闭客户端
client.close();
}
结果截图:
6 missing聚合
查询字段缺失的doc,并统计个数。
@Test
public void esAgg5() throws UnknownHostException {
// 指定es集群;查看 elasticsearch.yml -- put("cluster.name",集群名称)
Settings settings = Settings.builder().put("cluster.name","elastricsearch").build();
// 创建访问es服务器的客户端
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddresses(new TransportAddress(InetAddress.getByName("192.168.180.235"),9300));
// 过滤
AggregationBuilder builder = AggregationBuilders.missing("aggMissing").field("age");
SearchResponse response = client.prepareSearch("mauanx").addAggregation(builder).execute().actionGet();
// 过滤结果
Aggregation aggMissing = response.getAggregations().get("aggMissing");
// 可以按过滤进行统计
System.out.println("查询结果:");
System.out.println(aggMissing.toString());
// 关闭客户端
client.close();
}
结果截图:















 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









