







霉粉们的福利来啦!!!
面向对象+爬虫+队列+多线程+生产者消费者模式一键爬取全网霉霉图片
先介绍一波霉霉:
泰勒·斯威夫特(Taylor Swift),1989年12月13日出生于美国宾夕法尼亚州,美国女歌手、词曲作者、音乐制作人、演员。2006年,发行个人首张音乐专辑《Taylor Swift》,该专辑获得美国唱片业协会认证5倍白金唱片销量。2008年,发行音乐专辑《Fearless》,该专辑在美国公告牌专辑榜上获11周冠军,认证7倍白金唱片销量,并获得第52届格莱美奖年度专辑奖…

总之,霉霉就是很优秀,唱歌很好听,是我的最喜欢的歌手哈哈哈
100行代码教你爬取全网的霉霉图片
使用到的技术(下面我会逐一讲解):
- 爬虫
- 面向对象
- 消费者生产者模式
- 多线程
- 队列
如果你是一个霉霉的忠实粉丝,那么你的福利来了!!!
先上图:

看到旁边的滚轮没有,没错,你现在看到的霉霉的图片只是冰山一角!!!多的话不说,就问你想不想要,哈哈哈,想要的话就接着向下看吧~(不想要也可以看看嘻嘻)

整体的代码采用的是面向对象的编程风范,以生产者-消费者模式对数据的生产和消费,其中,生产者指的是–获取的图片url的某一个具体对象(生产图片的url),
消费者指的是获取url下载图片(消费图片的url),在本文中,生产者只有一个(因为它的生产水平有点高哈~),消费者的时时刻刻都在产生,直至完成它的特定任务才会被销毁,咱们上代码细聊吧!
首先来看一个整个类的结构
类名:SpiderTS
类属性:
count :用于记录对象的个数
urlQueue :url的队列,存储的是图片的url
urlDic :url的字典(记录已获取的url,主要就是为了去重,避免重复爬取)

至于为什么会把这些变量设置为类属性,大家都应该知道,目的是为了让每一个对象都有权限访问.
对象的初始化:

在对象初始化设置中没有设置什么特别的参数,就只有一个自身编号的变量num(保存霉霉的图片的路径用到了这个属性的)


重点来了!
生产者–获取图片的url
首先我先声明,不管是生产者还是消费者,其实说白了都是一个爬虫,只是爬取的东西不一样而已,在这里,我用到的是selenium库,为什么用这个库呢?原因很简单,因为我难
首先来看一下网页结构:

通过百度搜索霉霉的图片,然后点击到图片,就会显示霉霉的图片,当你向下滑动鼠标滚轮的时候,它会加载更多的图片,可想而知它是异步加载的,估计又是通过传递不同的参数获取不同的图片,具体是哪些参数我不想去想,具体有哪些参数我也不想去想,具体的参数是怎么变化的我也不想去想,总之,我就是不想花额外的脑子去判断这些参数的变化,有现成的selenium它不香吗?

所以加载数据这部就直接走捷径了
再来看看要获取的url具体在哪:
第一层结构(div[@class=“imgpage”]看到重复的类名,不用想,图片的url肯定保存在里面):

第二层结构(ul)

第三层结构(可想而知一定是li)
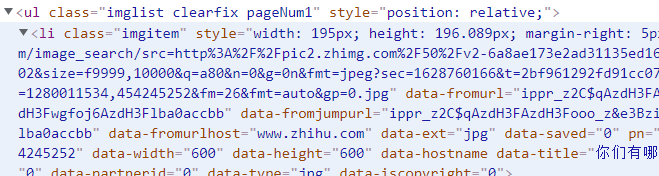
第四层结构(div[@class=“imgbox”])

最后一层层结构(a,这老东西可藏的真是深啊,包的严严实实的)

终于掏到它老家了

所以xpath按理来说应该这样写:
//div[@class="imgpage"]/ul/li/div/a/img/@data-imgurl
但是还是被打脸了,看是没有一丝错误的存在,但是实际上语法真的没有错,理解也是正确的,但是呢

用selenium里面自带的xpath的话,只能获取节点,而不能获取节点的属性值,所以这也是被打脸的原因
如果要获取节点的某一个属性值可以通过get_attribute(属性名)方法进行获取
如下图,我是这样获取url的值的:

再来看看消费者的整体代码:
# 生产者 不断获取图片的url,添加到urlQueue中
def crawlUrl(self):
chrome = webdriver.Chrome()
chrome.get(baseurl)
js = 'setInterval(function(){document.documentElement.scrollTop=10000000000000000},2000)' # 将页面拉到底部
while True:
chrome.execute_script(js)
imgUlrList = chrome.find_elements_by_xpath('//div[@class="imgpage"]/ul/li/div/a/img') # 节点列表
for img in imgUlrList:
imgurl = img.get_attribute('data-imgurl') # 节点的属性值
if not self.check(imgurl): # 如果是第一次获取的该url就加入到队列中
SpiderTS.urlQueue.put(imgurl)
SpiderTS.urlDic[imgurl] = 1 # 同时记录该url已被爬取
sleep(1)
整体结构就是:
打开图片的网页—>注入js(模拟人进行向下滚动滚轮以达到加载图片的目的)—>每隔一秒钟获取网页上图片的url,并且将新增的url插入到urlQueue队列的尾部
在添加url到队列中时用到了一个判断是否已经存在该url的check函数:

在这里类属性:urlDic就派上了用场,它是一个字典(至于为什么用字典,原因大家也应该都知道,因为它的搜索复杂度低,效率高!),具体原理是这样的,每当获取一个新的url时,通过SpiderTS.urlDic[url]进行检索,如果有就返回该值(值为1),否则就会保存,这也是为什么用try语句的,所以实质性没有我的话会返回0,

所以check函数的返回值的具体意义就是:
1:这个url不是第一次被抓取的,所以不会被再次添加到urlQueue队列中
0:这个url是第一次被抓取的,添加到urlQueue队列中
最后:

小睡一回儿~
压压惊~

消费者–下载图片
消费者的原理很简单—你给我一个url,我就还你一张霉霉的美照~,还是挺大方的哈哈哈
# 消费者 不断从urlQueue中获取url 进行图片的下载 下载完成之后 将该url添加到doneList中
def downloadImg(self):
url = SpiderTS.urlQueue.get()
response = get(url, headers=self.headers)
imgData = response.content
with open(f'全网霉霉图片/TS{self.num}.jpg', 'wb+') as f:
f.write(imgData)
实质上也是从队列中获取图片的url,然后进行爬取,保存到本地,是不是很简单呀~
有了生产者和消费者,咱们就来开始进行生产和消费吧!
创建生产者:
# 创造生产者 并让其进行生产
def createProducer():
# 生产者爬虫
producer = SpiderTS()
producer.crawlUrl()
没方法,咋就是效率高,一个生产者够一群消费者进行消费了!
创建消费者:
# 创建消费者 并让其进行消费
def createCustomer():
# 消费者爬虫
while True:
while SpiderTS.urlQueue.qsize() > 0:
consumer = SpiderTS()
consumer.downloadImg()
print('剩余:', SpiderTS.urlQueue.qsize())
可以看到外层循环是一个死循环,只要你供给(图片的url)还有,我就不断产生消费者进行消费.
最后,多线程让生产者和消费者分别展开各自的工作
# 使用多线程 让生产者和消费者同时进行各自的工作
productThread = Thread(target=createProducer)
consumeThread = Thread(target=createCustomer)
productThread.start()
consumeThread.start()
productThread.join()
consumeThread.join()
来看看具体的效果:


整体代码如下:
from queue import Queue
from time import sleep
from requests import get
from selenium import webdriver
from threading import Thread
baseurl = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&fm=detail&lm=-1&hd=undefined&latest=undefined©right=undefined&st=-1&sf=2&fmq=&fm=detail&pv=&ic=undefined&nc=1&z=0&se=&showtab=0&fb=0&width=undefined&height=undefined&face=0&istype=2&ie=utf-8&word=%E9%9C%89%E9%9C%89%E5%A3%81%E7%BA%B8'
class SpiderTS:
count = 1 # 记录爬虫的数量
urlQueue = Queue() # 存放为爬取的url
# 保存所有的url 不管有没有被爬取(功能是去重) 在将新获取的url添加到队列之前,检测集合中是否已经有该url,如果有就不添加到队列中
urlDic = dict()
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4503.5 Safari/537.36'} # 请求头
self.num = SpiderTS.count # 每一个对象各自的编号
if self.num == 1:
print(f'编号{self.num}的爬虫正在获取图片的url中...')
SpiderTS.count += 1 # 每新建一个对象-->爬虫数量加一
def __str__(self): # 爬取完成后的反馈
if self.num == 1:
return f'编号{self.num}的爬虫获取图片的url中完成!'
else:
return f'编号{self.num}的爬虫图片爬取完成!'
# 生产者 不断获取图片的url,添加到urlQueue中
def crawlUrl(self):
chrome = webdriver.Chrome()
chrome.get(baseurl)
js = 'setInterval(function(){document.documentElement.scrollTop=10000000000000000},2000)' # 将页面拉到底部
while True:
chrome.execute_script(js)
imgUlrList = chrome.find_elements_by_xpath('//div[@class="imgpage"]/ul/li/div/a/img') # 节点列表
for img in imgUlrList:
imgurl = img.get_attribute('data-imgurl') # 节点的属性值
if not self.check(imgurl): # 如果是第一次获取的该url就加入到队列中
SpiderTS.urlQueue.put(imgurl)
SpiderTS.urlDic[imgurl] = 1 # 同时记录该url已被爬取
sleep(1)
# 检测某一条url 返回0就代表该url是第一次获取的
def check(self, url):
try:
return SpiderTS.urlDic[url]
except:
return 0
# 消费者 不断从urlQueue中获取url 进行图片的下载 下载完成之后 将该url添加到doneList中
def downloadImg(self):
url = SpiderTS.urlQueue.get()
response = get(url, headers=self.headers)
imgData = response.content
with open(f'全网霉霉图片/TS{self.num}.jpg', 'wb+') as f:
f.write(imgData)
# 创造生产者 并让其进行生产
def createProducer():
# 生产者爬虫
producer = SpiderTS()
producer.crawlUrl()
# 创建消费者 并让其进行消费
def createCustomer():
# 消费者爬虫
while True:
while SpiderTS.urlQueue.qsize() > 0:
consumer = SpiderTS()
consumer.downloadImg()
print('剩余:', SpiderTS.urlQueue.qsize())
if __name__ == '__main__':
# 使用多线程 让生产者和消费者同时进行各自的工作
productThread = Thread(target=createProducer)
consumeThread = Thread(target=createCustomer)
productThread.start()
consumeThread.start()
productThread.join()
consumeThread.join()
想亲自操刀的小伙伴可以亲自动手试试呀~
同时我也会在我个人的博客上发布更多博客,供大家进行学习参考,有兴趣的小伙伴可以来踩踩我的个人博客,博客链接:LLL的blog,欢迎大家的光临呀!
















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









