







前言
因为刚刚学习到了协程,然后之前也对爬虫有一定的了解,所以打算结合之前学的线程和进程,和协程进行对比,看看它的性能到底有多高,在测试完成后,结果还是不错的!下面就直接上代码了,因为代码逻辑都比较简单,我就不一一解释了,重点是看测试结果,真的很让人兴奋!!!
案例
我这里以爬取一个网站上的所有国家的旗帜为例。(下图为爬取结果,共192张)分别利用了单线程,协程,多线程,多进程进行爬取测试。线程的效率真的已经很高了,但是协程居然比它还高!!!

定位旗帜的url
我这里使用的xpath对元素进行定位。
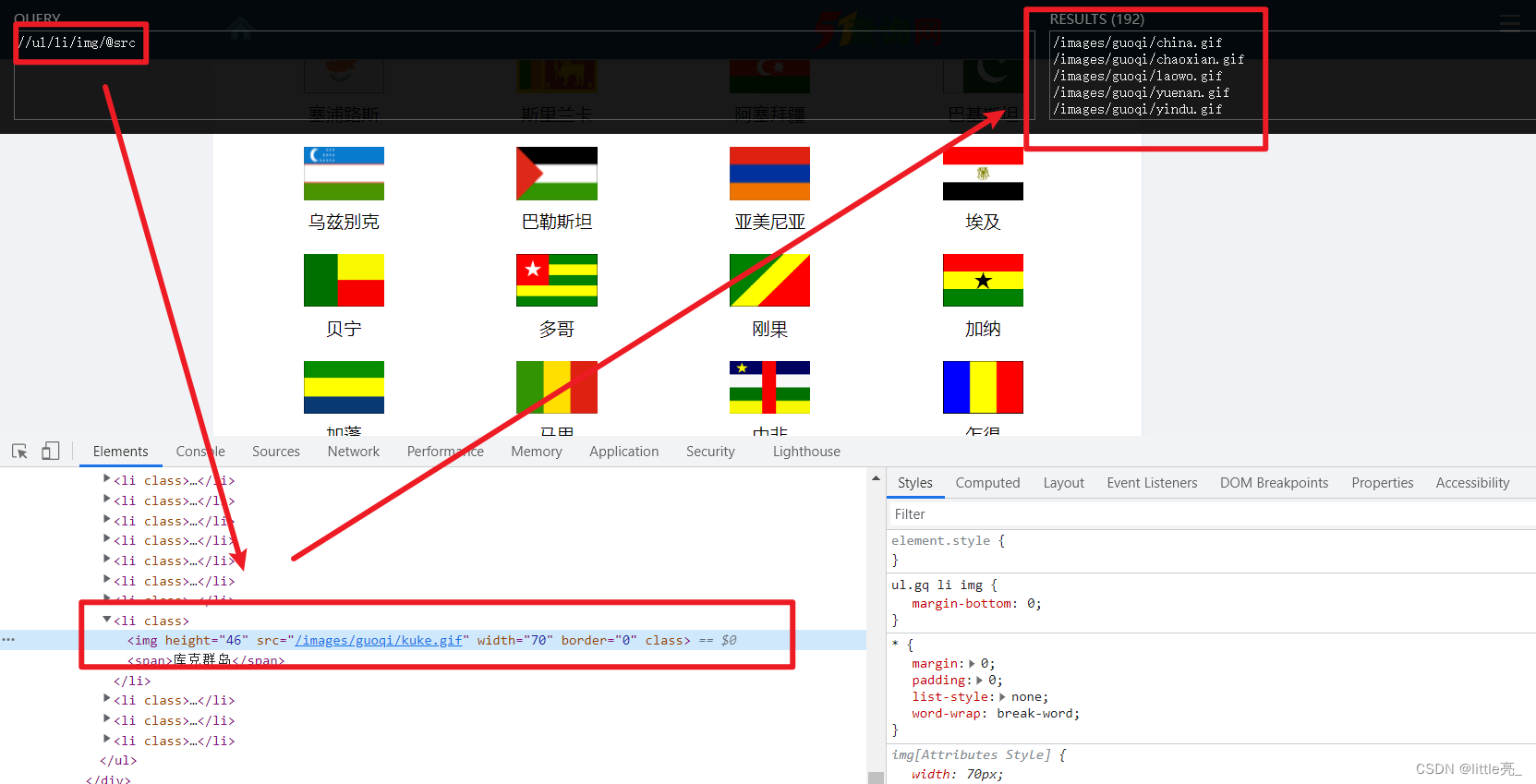
相关代码:
# 获取各国国旗的下载地址
def get_country_img_urls() -> List[Tuple]:
url = 'http://www.51zzl.com/jiaoyu/guoqi.asp'
response = get(url, headers=HEADERS)
response.encoding = 'gb2312' # 编码格式
html = response.text
e = etree.HTML(html)
country_url_li, country_name_li = e.xpath('//ul[@class="gq"]/li/img/@src'), e.xpath('//ul[@class="gq"]/li/span/text()') # xpath获取国家名称和图片地址
country_name_url_li = []
for country_url, country_name in zip(country_url_li, country_name_li):
country_name_url_li.append((country_name, f'http://www.51zzl.com{country_url}'))
return country_name_url_li这个函数的主要功能就是,拿到所有旗帜的url,并同它的国家名以列表的形式返回。
下载图片的函数
# 下载一张图片
def download_one(name: str, url: str) -> Tuple:
'''
下载到图片的二进制数据并返回
'''
response = get(url, headers=HEADERS)
content = response.content
return (name, content)保存图片的函数
# 保存一张图片
def save_one(name: str, content: bytes) -> None:
path_ = 'imgs'
if not path.exists(path_): mkdir(path_)
save_path = f'{path_}/{name}.gif'
with open(save_path, 'wb') as f:
f.write(content)
# 进度条
process_bar()下载并保存一张图片
# 下载并保存一张图片
def download_save_one(name, url):
name, content = download_one(name, url)
save_one(name, content)这个函数其实就是对上面两个函数的调用。
单线程版
# 串行执行
@clokced
def single_execute(country_name_url_li):
while country_name_url_li:
download_save_one(*country_name_url_li.pop())协程版
# 下载 并保存(协程版)
async def async_spider(name, url):
path_ = 'imgs'
if not path.exists(path_): mkdir(path_)
save_path = f'{path_}/{name}.gif'
session = ClientSession()
async with session.get(url) as img_data:
async with aio_open(save_path, 'wb') as f:
await f.write(await img_data.content.readany())
await session.close() # 关闭会话
# 进度条
process_bar()多线程版
# 多线程执行
@clokced
def mul_th_execute(country_name_url_li):
th_pool = ThreadPoolExecutor(len(country_name_url_li))
while country_name_url_li:
th_pool.submit(download_save_one, *country_name_url_li.pop())
th_pool.shutdown()多进程版
# 多进程执行
@clokced
def mul_pr_execute(country_name_url_li):
# 创建和cpu数量相同的进程数
pr_pool = ProcessPoolExecutor(cpu_count())
while country_name_url_li:
pr_pool.submit(download_save_one, *country_name_url_li.pop())
pr_pool.shutdown()值得注意的是,因为多各个进程之间是隔离的,所以这里使用了Manager实现进程之间的通信。

测试结果
单线程测试结果
单线程爬取图片
协程测试结果
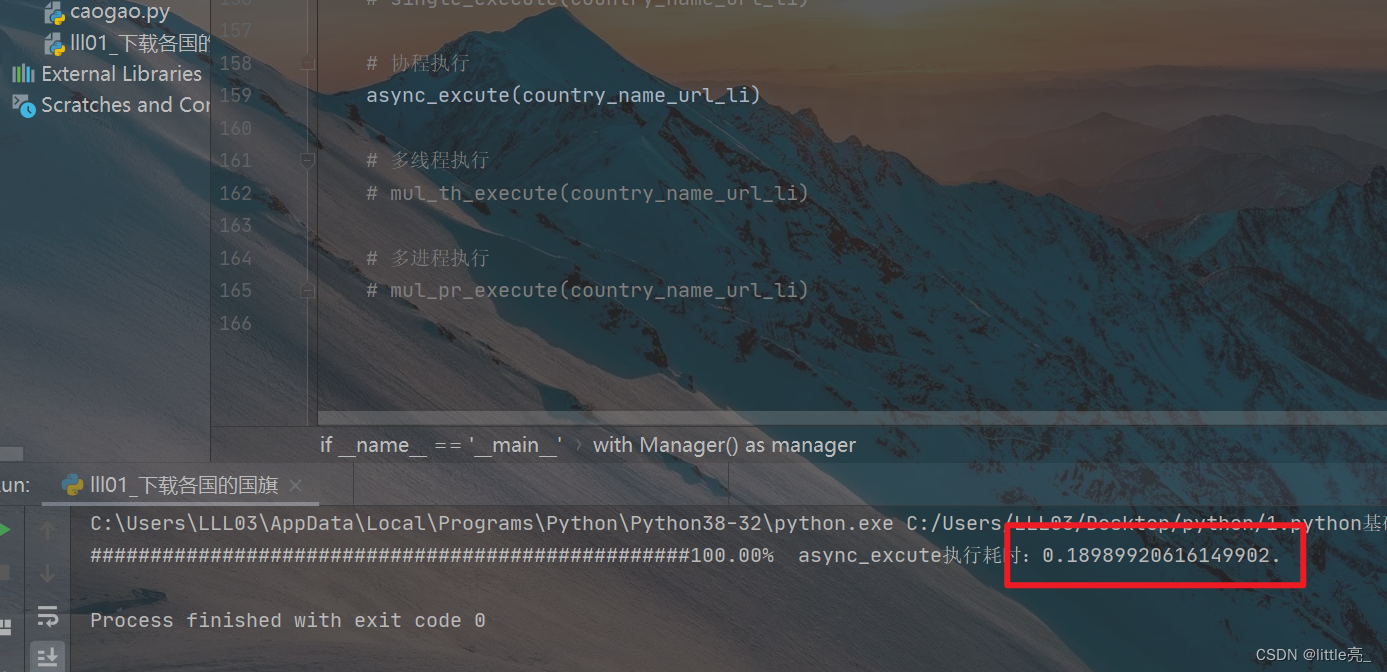
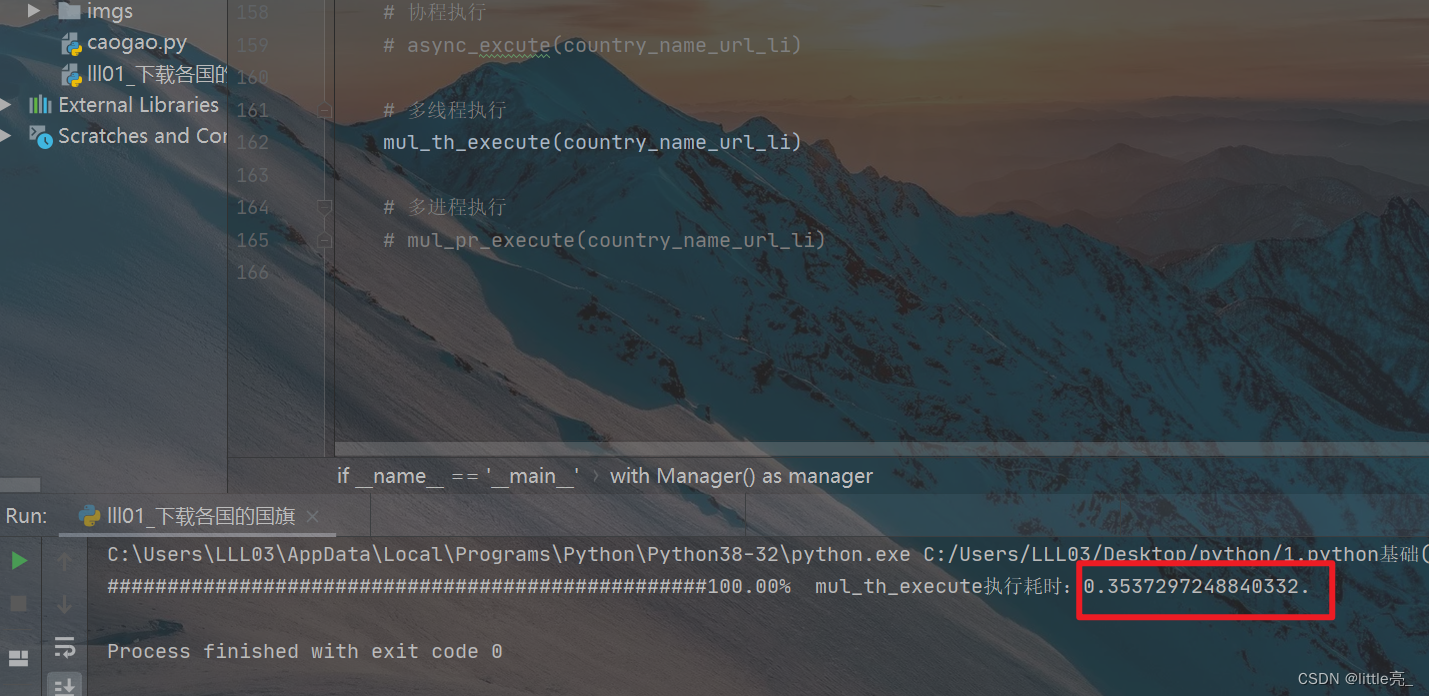
多线程测试结果
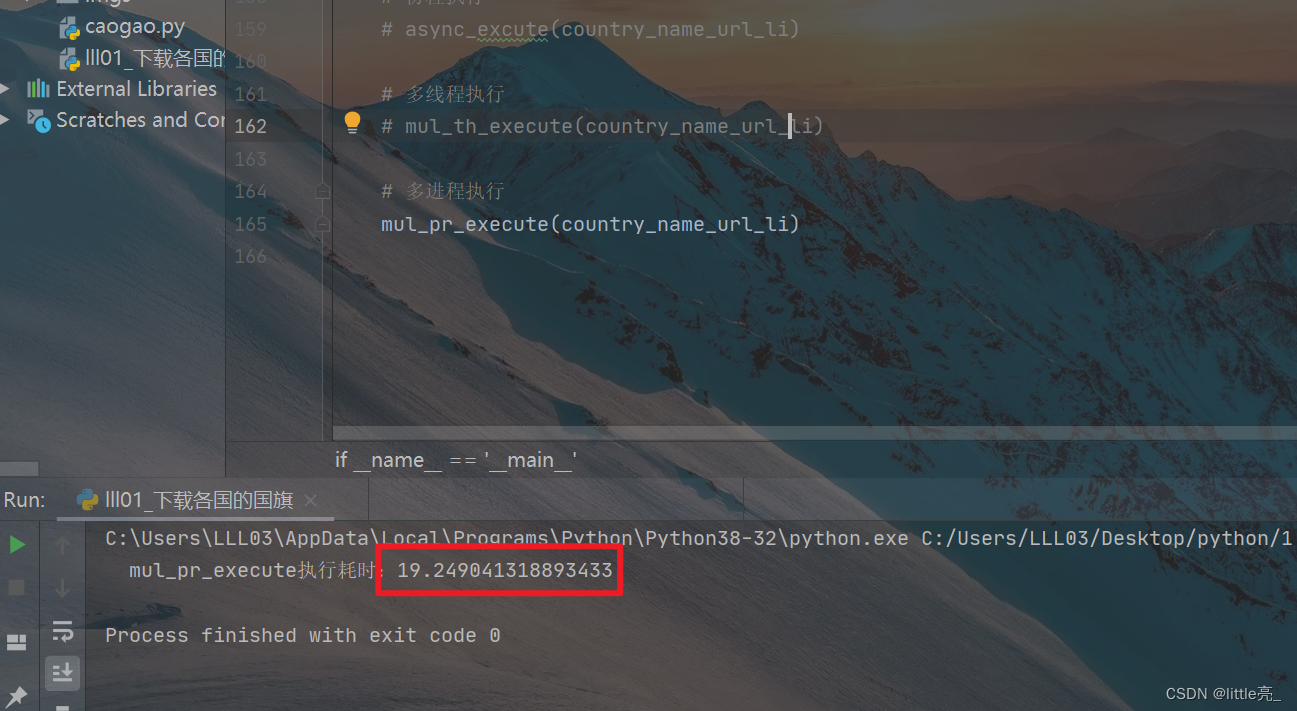
多进程测试结果
单线程:21s
多进程:19.24s
多线程:0.35s
协程:0.19s
多进程和单线程的速度差不多;多线程和协程的速度比它们快了将近100倍的量级,而协程的速度又差不多是多线程的两倍!
赏心悦目的测试结果!!!
同步更新于个人博客系统:以爬虫为例,单线程,协程,线程,进程之间性能的比较,原来协程可以这么快?
源码:
# -*- coding: UTF-8 -*-
'''
*****************LLL*********************
* @Project :17.使用future处理并发
* @File :lll01_下载各国的国旗.py
* @IDE :PyCharm
* @Author :LLL
* @Date :2022/5/1 16:05
*****************************************
'''
from asyncio import get_event_loop, wait
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from multiprocessing import cpu_count, Manager
from functools import wraps
from sys import stdout
from time import time
from typing import List, Tuple
from aiofiles import open as aio_open
from aiohttp import ClientSession
from requests import get
from os import path, mkdir
from lxml import etree
# 请求头
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
}
# 计时装饰器:用来计算一个函数执行所需花费的时间
def clokced(func):
@wraps(func) # 将原函数的函数名等一些属性一并“带过来”
def clock(*args, **kwargs):
start = time()
res = func(*args, **kwargs)
end = time()
print(f' {func.__name__}执行耗时:{end - start}.')
return res
return clock
# 进度条
def process_bar():
global country_name_url_li, original_sum
now_len = len(country_name_url_li)
done = original_sum - now_len
stdout.write('\r{}{}%'.format('#' * int(done * 50 / original_sum), '%.2f' % (done * 100 / original_sum))) # \r:回到首行
stdout.flush()
# 获取各国国旗的下载地址
def get_country_img_urls() -> List[Tuple]:
url = 'http://www.51zzl.com/jiaoyu/guoqi.asp'
response = get(url, headers=HEADERS)
response.encoding = 'gb2312' # 编码格式
html = response.text
e = etree.HTML(html)
country_url_li, country_name_li = e.xpath('//ul[@class="gq"]/li/img/@src'), e.xpath('//ul[@class="gq"]/li/span/text()') # xpath获取国家名称和图片地址
country_name_url_li = []
for country_url, country_name in zip(country_url_li, country_name_li):
country_name_url_li.append((country_name, f'http://www.51zzl.com{country_url}'))
return country_name_url_li
# 下载一张图片
def download_one(name: str, url: str) -> Tuple:
'''
下载到图片的二进制数据并返回
'''
response = get(url, headers=HEADERS)
content = response.content
return (name, content)
# 保存一张图片
def save_one(name: str, content: bytes) -> None:
path_ = 'imgs'
if not path.exists(path_): mkdir(path_)
save_path = f'{path_}/{name}.gif'
with open(save_path, 'wb') as f:
f.write(content)
# 进度条
process_bar()
# 下载并保存一张图片
def download_save_one(name, url):
name, content = download_one(name, url)
save_one(name, content)
# 串行执行
@clokced
def single_execute(country_name_url_li):
while country_name_url_li:
download_save_one(*country_name_url_li.pop())
# 下载 并保存(协程版)
async def async_spider(name, url):
path_ = 'imgs'
if not path.exists(path_): mkdir(path_)
save_path = f'{path_}/{name}.gif'
session = ClientSession()
async with session.get(url) as img_data:
async with aio_open(save_path, 'wb') as f:
await f.write(await img_data.content.readany())
await session.close() # 关闭会话
# 进度条
process_bar()
# 协程执行
@clokced
def async_excute(country_name_url_li):
loop = get_event_loop()
tasks = []
while country_name_url_li:
tasks.append(loop.create_task(async_spider(*country_name_url_li.pop())))
loop.run_until_complete(wait(tasks))
loop.close()
# 多线程执行
@clokced
def mul_th_execute(country_name_url_li):
th_pool = ThreadPoolExecutor(len(country_name_url_li))
while country_name_url_li:
th_pool.submit(download_save_one, *country_name_url_li.pop())
th_pool.shutdown()
# 多进程执行
@clokced
def mul_pr_execute(country_name_url_li):
# 创建和cpu数量相同的进程数
pr_pool = ProcessPoolExecutor(cpu_count())
while country_name_url_li:
pr_pool.submit(download_save_one, *country_name_url_li.pop())
pr_pool.shutdown()
if __name__ == '__main__':
# 使用Manager实现进程之间的通信
with Manager() as manager:
country_name_url_li = get_country_img_urls()
original_sum = len(country_name_url_li) # 一开始的总数
# 串行执行
single_execute(country_name_url_li)
# 协程执行
# async_excute(country_name_url_li)
# 多线程执行
# mul_th_execute(country_name_url_li)
# 多进程执行
# mul_pr_execute(country_name_url_li)















 1118
1118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









