







一.数据库存储引擎
查看mysql版本:
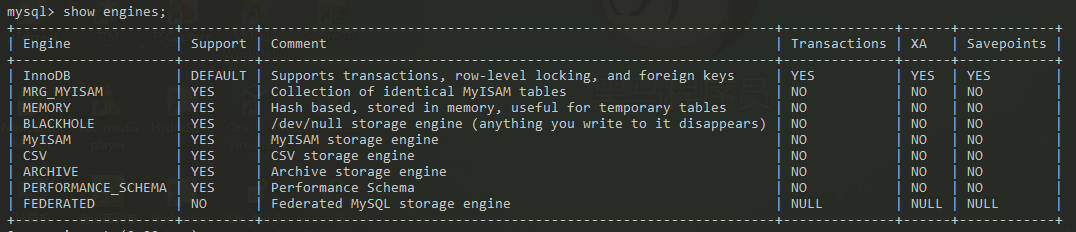
查看当前mysql版本支持的存储引擎:
本文只介绍两种常用存储引擎:
1. MyISAM
不支持事务处理
表锁:发生死锁概率高,相对并发也低
2. InnoDB(MySQL 5.5之后默认存储引擎)
支持事务处理
行锁:发生死锁概率低,相对并发也高
3. 行锁与表锁的界定
SQL示例:update stu set c1 = ? where c2 = ?;
行锁:其他线程无法操作当前检索的数据,但是可以操作其他行数据
表锁:其他线程无法操作当前表数据
4. 查看数据表存储引擎,指定数据表存储引擎
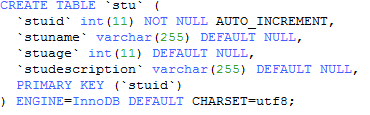
4.1 创建数据表
create table stu(
stuidint primary key auto_increment,
stunamevarchar(255),
stuageint,
studescriptionvarchar(255)
);
4.2 查看该数据表使用的存储引擎
使用可视化工具查看该表信息:

我们可以在创建数据表的时候指定存储引擎:
去查看该表的DDL语句,发现数据库在执行SQL表创建语句的时候默认给我们加了一部分内容,结尾部分即指定ENGINE=InnoDB,如果我们要指定使用其他的数据库存储引擎,可以在创建表的时候修改该值即可,但是不建议修改为其他存储引擎!!!
二.数据库索引
- PRIMARY KEY
- UNIQUE
- INDEX
- FULLTEXT
三.执行计划
对于慢SQL的优化,从哪儿着手?
通过查看执行计划,可以确认该SQL在执行的时候有没有使用索引
在stu表中插入一部分模拟数据:
insertinto stu(stuname,stuage,studescription) values('张三',18,'爱好下棋');
insertinto stu(stuname,stuage,studescription) values('李四',22,'今天状态不佳');
insertinto stu(stuname,stuage,studescription) values('王五',16,'生病');
insertinto stu(stuname,stuage,studescription) values('赵六',21,'喜欢三国演义');
insertinto stu(stuname,stuage,studescription) values('田七',17,'最近在研究机器学习');
分别查看下列SQL语句的执行计划:
select stuid,stuname,stuage,studescription from stu;
select stuname,stuage,studescription from stu where stuid = 3;
select stuname,stuage,studescription from stu where stuname = '田七';
select stuname,stuage,studescription from stu where stuid > 2;




下面分别对id | select_type | table | partitions | type | possible_keys |key | key_len | ref | rows | filtered | Extra字段进行讲解:
1. id
- 数字越大越先执行
- 如果数字一样大,就从上往下执行
- 如果为null就表示这是一个结果集,不需要使用它来进行查询
2. select_type
- 每个SELECT子句的类型
- 常见选项
- simple:表示一个不需要union操作或者不包含子查询的select查询,有连接查询时,外层查询为simple,且只有一个
- primary:表示一个需要union操作或者包含子查询的select查询,最外层查询为primary,且只有一个
- union
- dependent union
- union result
- subquery:除了from子句中包含的子查询外,其他地方出现的子查询都可能是subquery
- dependent query
- derived
3. table
- 显示查询的表名,如果查询使用了别名,那么这儿显示的是别名
- 如果不涉及对数据表的操作,显示的是null
- 如果显示的是<derived N>,表示这是一张临时表,N即是执行计划中的id,表示这张表来源于这次查询
- 如果显示的是<union M,N>,表示这是一张临时表,表示这张表来源于union查询id为M,N的结果集
4. partitions
5. type
- 性能从好到差:system、const、eq_ref、ref、fulltext、ref_or_null、unique_subquery、index_subquery、range、index_merge、index、ALL
- 除了ALL以外,其他的type都可以使用到索引
- 除了index_merge以外,其他的type只可以使用到一个索引
- 不同连接类型的解释
- system:表示只有一行数据或者是空表,且只出现在myisam和memory表,如果是innoDB表,这时候通常显示为ALL或者index
- const:表示使用了主键索引或者唯一索引,返回一行记录的等值where条件,通常type是const
- eq_ref
- ref
- range:索引范围扫描,常见于使用>、<、is null、between、in、like的SQL语句
- index:索引全表扫描
- ALL
6. possible_keys
- 查询可能使用到的索引
7. key
- 查询实际使用到的索引,如果没有,则为NULL
- 如果select_type为index_merge,这里可能出现两个以上索引
8. key_len
- 只计算where条件用到的索引长度,而排序和分组就算使用到了索引,也不会计算到key_len中
9. ref
- 如果是常量等值查询,这里显示const
- 如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段
- 如果查询条件中使用了表达式或者函数,或者条件列发生隐式转换,这里可能显示为func
10. rows
- 执行计划估算的扫描行数
11. filtered
- 满足查询条件的比例,单位是百分比
12. Extra
该列包含MySQL解决查询的详细信息,有以下几种情况:
- distinct:查询语句中使用了distinct关键字
- no tables used:不带from子句的查询或者from dual查询
- using filesort:如果排序时无法使用到索引,就会出现这个
- using index:查询时不需要回表查询,直接通过索引就可以获取想要的数据
- using intersect:表示使用and连接各个索引条件,表示从处理结果获取交集
- using union:表示使用or连接各个索引条件,表示从处理结果获取并集
- using temporary:表示使用了中间表存储中间结果
- using where:表示存储引擎返回的记录并不是所有都满足查询条件















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









