







文章目录
pelt 算法以及负载与任务组权重的代码实现
在讲解复现脚本是如何触发问题,以及后面的 patch-2 触发问题的逻辑之前,必须要详细了解 cfs 组调度相关代码实现。这一篇主要是针对 cfs cgroup 代码实现的详细分析(内容枯燥,阅读可以适当跳读)。
1 几个重要的结构体
首先是一个组调度中几个结构体之间的关系图:
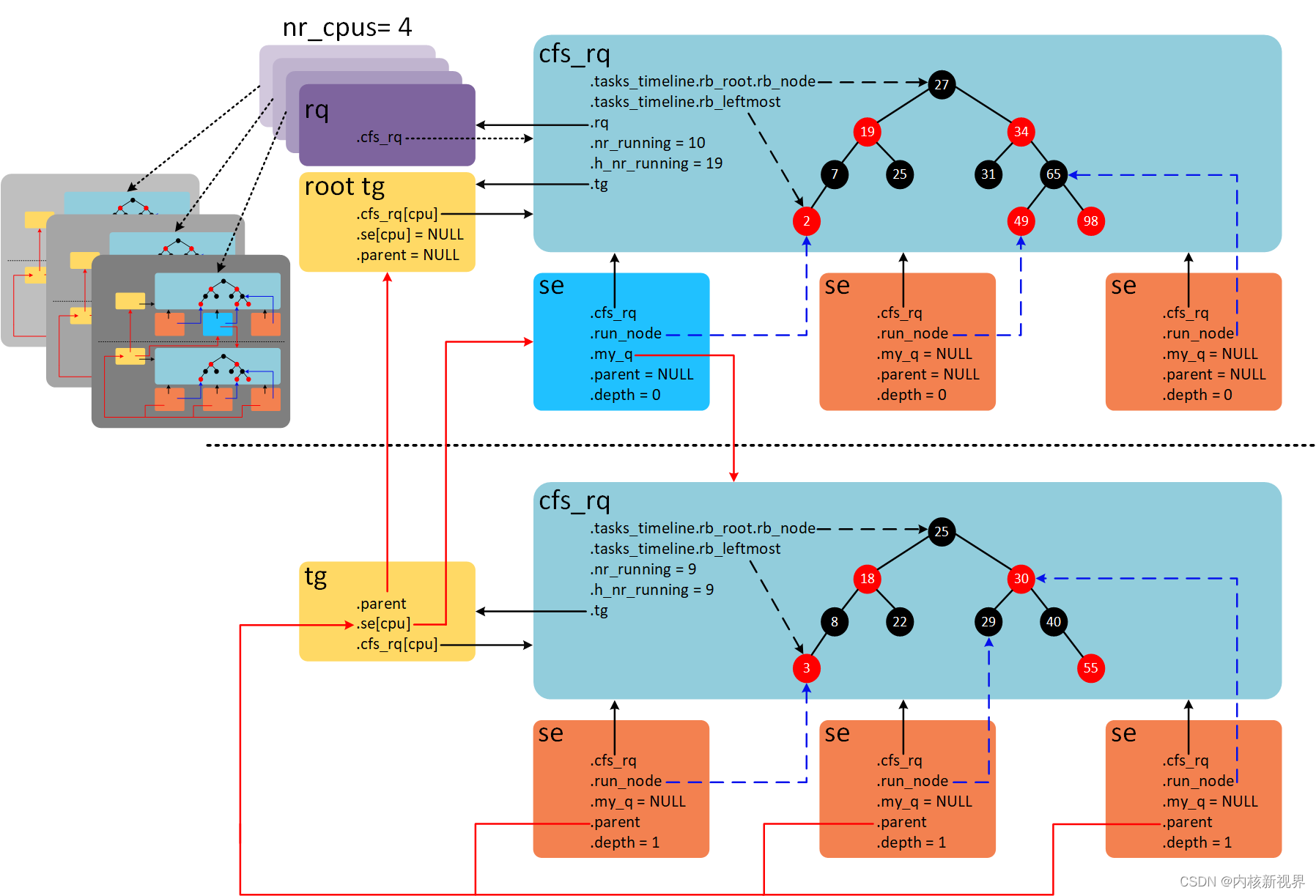
root tg是root_task_group所有任务默认在根任务组中。每个任务组有自己的percpu cfs_rq就绪队列,以及调度实体percpu se。- 每一个任务组的调度实体
se的权重来自于对应任务组shares,任务组load_avg以及对应任务组cfs_rq就绪队列的权重计算得来,详情看第二部分时间片计算。 - 每一个任务组的调度实体
se的负载来自于对应cfs_rq权重及 pelt 算法累加得来,对于任务的se则是根据周期内运行时间及 pelt 算法累加得来。 - 每一个任务组的 cfs_rq 就绪队列权重来自于该队列下所有调度实体
se权重之和。 - 每一个任务组的 cfs_rq 就绪队列负载来自于该队列下所有调度实体
se负载之和,如果cfs_rq负载变化则会更新任务组的load_avg,并在合适时机根据这些信息调整任务组调度实体权重信息。
1.1 struct rq
struct rq {
...
...
struct cfs_rq cfs; ------------------------------------------------ (1)
struct rt_rq rt; ------------------------------------------------ (2)
struct dl_rq dl; ------------------------------------------------ (3)
#ifdef CONFIG_FAIR_GROUP_SCHED
/* list of leaf cfs_rq on this CPU: */
struct list_head leaf_cfs_rq_list; ------------------------------------ (4)
struct list_head *tmp_alone_branch; ------------------------------------ (5)
#endif
...
struct task_struct *curr; ------------------------------------------------ (6)
struct task_struct *idle; ------------------------------------------------ (7)
struct task_struct *stop; ------------------------------------------------ (8)
...
int cpu; -------------------------------------------------------- (9)
};
每个 cpu 上都会有一个全局的就绪队列(cpu runqueue),使用 struct rq 描述,是 percpu 类型。上面也保存了当前 cpu 所有的调度类就绪队列,如 cfs_rq,rt_rq,dl_rq等。
(1)cfs 调度器的就绪队列 cfs_rq,所有 cfs 任务都将被挂载到该就绪队列里(任务组 task_group 也有自己的 cfs_rq 就绪队列)。
(2)(3)同上分别是 rt,deadline的就绪队列。
(4)(5)当启用 cfs 组调度时生效,用于自底向上遍历子叶节点,对于限流的 cfs_rq 将不在该链表里面,每一个cfs_rq 上有任务入队都会把这个 cfs_rq 添加到链表中,在之后负载均衡中将会遍历链表对每个 cfs_rq 的负载进行衰减。该链表存在的目的是因为带宽节流的存在,cfs_rq 可能因为节流原因会暂时移出进行节流,所以不参与负载衰减等,所以通过链表遍历当前 cpu 上所有 cfs_rq 进行更新。
(6)当前 cpu 上正在运行的任务,通过 curr 可以随时获取到对应任务是否正在运行。
(7)当前 cpu 对应的 idle task。
(8)当 stop 不为空时将会进行停机操作,目前由迁移线程使用,当有任务需要迁移时将会在对应cpu上启动迁移线程,进行任务迁移。
(9)标记当前 rq 属于哪一个 cpu。
1.2 struct sched_avg
struct sched_avg {
u64 last_update_time; ---------------------------------------(1)
u64 load_sum; -----------------------------------------------(2)
u64 runnable_load_sum; ----------------------------------------(3)
u32 util_sum; -------------------------------------------------(4)
u32 period_contrib; -------------------------------------------(5)
unsigned long load_avg; -----------------------------------------(6)
unsigned long runnable_load_avg; --------------------------------(7)
unsigned long util_avg; -----------------------------------------(8)
struct util_est util_est;
} ____cacheline_aligned;
该结构体由 pelt 算法使用,计算对应调度实体的负载及利用率。
该结构内嵌于struct sched_entity,struct cfs_rq 其中 cfs_rq 的 avg 由调度实体累加。
(1)用于记录上次做负载更新时的时间,在进行 pelt 计算时将会通过该变量计算衰减周期等。当新任务创建或任务迁移到其他 cpu 时变量修改为 0,新任务或在新 cpu 上运行时开始没是有负载贡献的,所以可用于表示当前 cfs_rq 是否需要进行负载更新。
(2)总的负载累加,包括可运行任务和阻塞任务,对于任务调度实体是时间片负载的累加,对于任务组调度实体是对应 cfs_rq 就绪队列权重与时间片负载共同计算累加。
(3)可运行任务总的负载累加,只包括可运行任务,同(2),在 linux 5.x 版本该值被移除也不参与任务组权重计算,不重要。
(4)正在运行任务的负载贡献总和,该值的计算与 cpu 算力相关,并在合适时机通过该变量像电源管理提供信息,以便进行 cpu 调频工作。
(5)用于记录上次更新负载不足 1024 us 周期的时间,在下次进行负载更新时将会把该部分时间加入计算。
(6)是(2)的平均值,分频系数是LOAD_AVG_MAX - 1024 + se->avg.period_contrib该值与 pelt 算法相关。cfs_rq 的 load_avg 将由 cfs_rq 下所有调度实体的 load_avg 累加,如果调度实体移出该 cfs_rq 将把 load_avg 从 cfs_rq 中移除。cfs_rq 的 load_avg 将参与 task_group 的 share 权重计算,影响任务组权重从而影响任务组能够分配到的时间片。
(7)同(3)。
(8)同(4),由 util_sum 除以分频系数(同(6)的分频系数,pelt 算法相关)得出。
1.3 struct sched_entity
struct sched_entity {
/* For load-balancing: */
struct load_weight load; -----------------------------------------------------(1)
unsigned int on_rq; ----------------------------------------------------(2)
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth; ------------------------------------------------------------(3)
struct sched_entity *parent; --------------------------------------------------(4)
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq; --------------------------------------------------(5)
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q; ----------------------------------------------------(6)
#endif
#ifdef CONFIG_SMP
/*
* Per entity load average tracking.
*
* Put into separate cache line so it does not
* collide with read-mostly values above.
*/
struct sched_avg avg; -----------------------------------------------------(7)
#endif
};
cfs 任务的调度实体,在组调度下也是一个任务组的调度实体,pelt 算法即针对该调度实体计算负载和利用率。
(1)对应调度实体的权重,对于任务则是 nice 值对应的权重,对于任务组的调度实体则是根据 task_group->shares,task_group->load_avg 以及 gcfs_rq->load 计算得来。
(2)标记调度实体是否在就绪队列上。
(3)该任务组的调度实体的深度。
(4)指向该调度实体对应的任务组的调度实体,即该调度实体的上一级,cfs 调度器中多处通过该变量向上遍历调度实体for_each_sched_entity(se)。
(5)同(4)指向该调度实体需要被挂入的 cfs_rq 节点。
(6)指向自己所属的 cfs_rq,cfs_rq/se 属于一个 task_group。
(7)记录该调度实体的 avg,在调度实体加入 cfs_rq 时,se 的 avg 将会累加 cfs_rq 的 avg,并且该部分负载同样参与衰减,并根据 UPDATE_TG 标记判断是否需要将该部分负载贡献到 task_group->load_avg 中。
1.4 struct cfs_rq
struct cfs_rq {
struct load_weight load; ---------------------------------------------------(1)
/*
* CFS load tracking
*/
struct sched_avg avg; ----------------------------------------------------(2)
struct {
raw_spinlock_t lock ____cacheline_aligned;
int nr;
unsigned long load_avg;
unsigned long util_avg;
unsigned long runnable_avg;
} removed; ------------------------------------------------------------------(3)
#ifdef CONFIG_FAIR_GROUP_SCHED
unsigned long tg_load_avg_contrib; ------------------------------------(4)
long propagate; --------------------------------------------------(5)
long prop_runnable_sum; ------------------------------------------(6)
#endif /* CONFIG_FAIR_GROUP_SCHED */
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; /* CPU runqueue to which this cfs_rq is attached */
int on_list;
struct list_head leaf_cfs_rq_list; ---------------------------------------(7)
struct task_group *tg; /* group that "owns" this runqueue */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};
cfs_rq 是 cfs 调度器使用的就绪队列,内嵌在 rq,task_group 结构体中分别表示就绪队列中的 cfs_rq 就绪队列,任务组中的 cfs_rq 就绪队列。
(1)cfs_rq 队列的权重,由队列下的调度实体的权重累加至此处,对于任务组的调度实体则是由任务组shares/load_avg计算得来,由update_cfs_group函数调用完成计算。
(2)cfs_rq 队列的负载,由队列下的调度实体的负载累加至此处,cfs_rq 负载参与任务组 se 权重计算,并且参与负载衰减。
(3)在任务迁移过程中,如果任务处于睡眠状态,任务负载不会直接从cfs_rq上减掉而是先将其需要移除的负载挂入 removed 节点中,在对 cfs_rq 负载更新时移出 cfs_rq 队列。
(4)用于标记该 cfs_rq 已经向 task_group 贡献的负载(load_avg),在update_tg_load_avg函数中用于计算向任务组贡献的负载,如果 cfs_rq 负载衰减,在更新任务组负载时任务组负载会逐渐降低。
(5)(6)当 cfs_rq load_sum 发生变化时(出队,入队),prop_runnable_sum用于记录发生变化的负载总量,并在 update_load_avg 期间向上广播这部分变化的负载,并更新每个层次的负载情况。
(7)加入到 rq 结构体中的 leaf_cfs_rq_list 中,按照自底向上的顺序排序链表。
1.5 struct task_group
struct task_group {
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each CPU */
struct sched_entity **se; ------------------------------------(1)
/* runqueue "owned" by this group on each CPU */
struct cfs_rq **cfs_rq; --------------------------------(2)
unsigned long shares; ----------------------------------(3)
atomic_long_t load_avg ____cacheline_aligned; ----------(4)
#endif
};
使用task_group描述一个组。在这个组中管理组内的所有进程。
(1)指针数组,数组大小等于CPU数量。现在假设只有一个CPU的系统。将一个用户组也用一个调度实体代替,插入对应的红黑树。例如,上面用户组A和用户组B就是两个调度实体se,挂在顶层的就绪队列cfs_rq中。用户组A管理9个可运行的进程,这9个调度实体se作为用户组A调度实体的child。通过se->parent成员建立关系。用户组A也维护一个就绪队列cfs_rq,暂且称之为group cfs_rq,管理的9个进程的调度实体挂在group cfs_rq上。当我们选择进程运行的时候,首先从根就绪队列cfs_rq上选择用户组A,再从用户组A的group cfs_rq上选择其中一个进程运行。现在考虑多核CPU的情况,用户组中的进程可以在多个CPU上运行。因此,我们需要CPU个数的调度实体se,分别挂在每个CPU的根cfs_rq上。
(2)上面提到的group cfs_rq,同样是指针数组,大小是CPU的数量。因为每一个CPU上都可以运行进程,因此需要维护CPU个数的group cfs_rq。
(3)调度实体有权重的概念,以权重的比例分配CPU时间。用户组同样有权重的概念,share就是task_group的权重,不过不直接使用,还需要 tg->load_avg 一起计算。
(4)整个用户组的负载贡献总和。由于是全局访问的,所以只有当每个 cfs_rq 负载绝对值超过 cfs_rq->tg_load_avg_contrib 的某个阈值后才累加到 tg->load_avg。
任务组权重的一个简单计算:
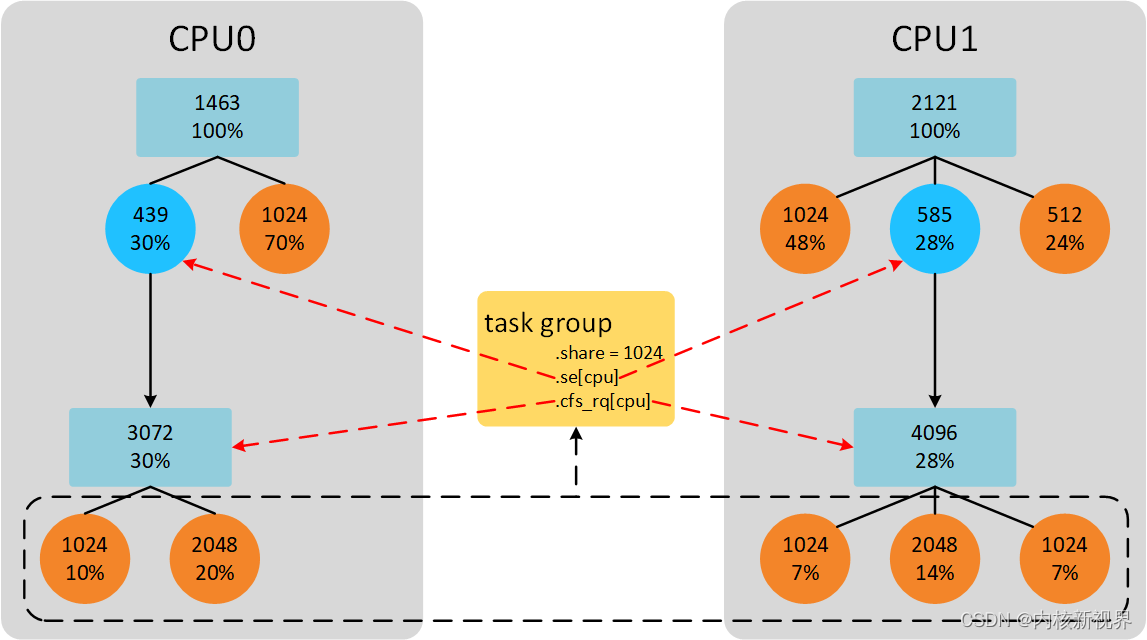
实际计算参考第一篇的权重与时间片计算。
2 pelt 算法(注:该部分来自网络窝窝科技)
2.1 为什么需要PELT?
在Linux 3.8之前,CFS以每个运行队列(runqueue,简称rq)为基础跟踪负载。但是这种方法,我们无法确定当前负载的来源。同时,即使工作负载相对稳定的情况下,在rq级别跟踪负载,其值也会产生很大变化。为了解决以上的问题,PELT算法会跟踪每个调度实体(per-scheduling entity)的负载情况。
2.2 如何进行PELT
了做到Per-entity的负载跟踪,时间(物理时间,不是虚拟时间)被分成了1024us的序列,在每一个1024us的周期中,一个entity对系统负载的贡献可以根据该实体处于runnable状态(正在CPU上运行或者等待cpu调度运行)的时间进行计算。如果在该周期内,runnable的时间是x,那么对系统负载的贡献就是(x/1024)。当然,一个实体在一个计算周期内的负载可能会超过1024us,这是因为我们会累积在过去周期中的负载,当然,对于过去的负载我们在计算的时候需要乘一个衰减因子。如果我们让Li表示在周期pi中该调度实体的对系统负载贡献,那么一个调度实体对系统负荷的总贡献可以表示为:
L = L0 + L1 * y + L2 * y2 + L3 * y3 + ... + Ln * yn
- y32 = 0.5, y = 0.97857206
Li表示在周期pi中的瞬时负载,对于过去的负载我们在计算的时候需要乘一个衰减因子y。在目前的内核代码中,y是确定值:y ^32等于0.5。这样选定的y值,一个调度实体的负荷贡献经过32个窗口(32 x 1024us)后,对当前时间的的符合贡献值会衰减一半。
通过上面的公式可以看出:
(1)调度实体对系统负荷的贡献值是一个序列之和组成
(2)过去的负荷也会被累计,但是是以递减的方式来影响负载计算。
(3)最近时间点的负荷值拥有最大的权重1,随着时间的推移,权重指数衰减
使用这样序列的好处是计算简单,我们不需要使用数组来记录过去的负荷贡献,只要把上次的总负荷的贡献值乘以y再加上新的L0负荷值就OK了。utility和runnable load的计算也是类似的:
L1 = L1
L2 = L1*y + L2
L3 = L1*y^2 + L2*y + L3
L3 = L1*y^3 + L2*y^2 L3*y + L4
Ln = L1 *y^n ..... + Ln
可以得出如下公式:
Ln = (((L1y + L2)y + L3)y + L4)y ... + Ln
所以可以看到计算负载只需要把上次负载衰减后加上当前负载即可。
内核中已根据公式做了优化,由函数 decay_load计算n周期的衰减值:
static u64 decay_load(u64 val, u64 n)
{
unsigned int local_n;
if (unlikely(n > LOAD_AVG_PERIOD * 63)) /* 1 */
return 0;
/* after bounds checking we can collapse to 32-bit */
local_n = n;
/*
* As y^PERIOD = 1/2, we can combine
* y^n = 1/2^(n/PERIOD) * y^(n%PERIOD)
* With a look-up table which covers y^n (n<PERIOD)
*
* To achieve constant time decay_load.
*/
if (unlikely(local_n >= LOAD_AVG_PERIOD)) { /* 2 */
val >>= local_n / LOAD_AVG_PERIOD;
local_n %= LOAD_AVG_PERIOD;
}
val = mul_u64_u32_shr(val, runnable_avg_yN_inv[local_n], 32);
return val;
}
LOAD_AVG_PERIOD的值为32,当时间经过2016个周期后,衰减后的值为0。即val*y^n=0, n > 2016。- 当n大于等于32的时候,就需要根据y32=0.5条件计算yn的值。
yn*232 = 1/2n/32 * yn%32*232=1/2n/32 * runnable_avg_yN_inv[n%32]。
2.3 负载计算
经过上面举例,我们可以知道计算当前负载贡献并不需要记录所有历史负载贡献。我们只需要知道上一刻负载贡献就可以计算当前负载贡献,这大大降低了代码实现复杂度。我们继续上面举例问题的思考,我们依然假设一个task开始从0时刻运行,那么1022us后的负载贡献自然就是1022。当task经过10us之后,此时(现在时刻是1032us)的负载贡献又是多少呢?很简单,10us中的2us和之前的1022us可以凑成一个周期1024us。这个1024us需要进行一次衰减,即现在的负载贡献是:(1024 - 1022 + 1022)y + 10 - (1024 - 1022) = 1022y + 2y + 8 = 1010。1022y可以理解成由于经历了一个周期,因此上一时刻的负载需要衰减一次,因此1022需要乘以衰减系数y,2y可以理解成,2us属于上一个负载计算时距离一个周期1024us的差值,由于2是上一个周期的时间,因此也需要衰减一次,8是当前周期时间,不需要衰减。又经过了2124us,此时(现在时刻是3156us)负载贡献又是多少呢?即:(1024 - 8 + 1010)y2 + 1024y + 2124 - 1024 - (1024 - 8) = 1010y2 + 1016y2 + 1024y + 84 = 3024。2124us可以分解成3部分:1016us补齐上一时刻不足1024us部分,凑成一个周期;1024us一个整周期;当前时刻不足一个周期的剩余84us部分。相当于我们经过了2个周期,因此针对上一次的负载贡献需要衰减2次,也就是1010y2部分,1016us是补齐上一次不足一个周期的部分,因此也需要衰减2次,所以公式中还有1016y2 部分。1024us部分相当于距离当前时刻是一个周期,所以需要衰减1次,最后84部分是当前剩余时间,不需要衰减。
针对以上示例,我们可以得到一个更通用情况下的计算公式。假设上一时刻负载贡献是u,经历d时间后的负载贡献如何计算呢?根据上面的例子,我们可以把时间d分成3和部分:d1是离当前时间最远(不完整的)period 的剩余部分,d2 是完整period时间,而d3是(不完整的)当前 period 的剩余部分。假设时间d是经过p个周期(d=d1+d2+d3, p=1+d2/1024)。d1,d2,d3 的示意图如下:
d1 d2 d3
^ ^ ^
| | |
|<->|<----------------->|<--->|
|---x---|------| ... |------|-----x (now)
p-1
u' = (u + d1) y^p + 1024 \Sum y^n + d3 y^0
n=1
p-1
= u y^p + d1 y^p + 1024 \Sum y^n + d3 y^0
n=1
上面的例子现在就可以套用上面的公式计算。例如,上一次的负载贡献u=1010,经过时间d=2124us,可以分解成3部分,d1=1016us,d2=1024,d3=84。经历的周期p=2。所以当前时刻负载贡献u’=1010y2 + 1016y2 + 1024y + 84,与上面计算结果一致。
2.4 记录负载
负载将记录在上面说的 sched_avg 结构体中。而 sched_avg 内嵌于调度实体中,调度实体可能是任务也可能是任务组,所以对于调度实体初始化代码如下:
void init_entity_runnable_average(struct sched_entity *se)
{
struct sched_avg *sa = &se->avg;
memset(sa, 0, sizeof(*sa));
/*
* Tasks are intialized with full load to be seen as heavy tasks until
* they get a chance to stabilize to their real load level.
* Group entities are intialized with zero load to reflect the fact that
* nothing has been attached to the task group yet.
*/
if (entity_is_task(se))
sa->runnable_load_avg = sa->load_avg = scale_load_down(se->load.weight);
se->runnable_weight = se->load.weight;
/* when this task enqueue'ed, it will contribute to its cfs_rq's load_avg */
}
在创建一个任务组时或者 fork 时将会调用init_entity_runnable_average来初始化一个调度实体的 avg。
对于task se 初始化,runnable_load_avg = load_avg = se->load.weight。即可运行平均负载,平均负载等于任务的权重。后续这两个变量负载计算累加的也是se的权重值。
对于任务组 se,runnable_load_avg ,load_avg 均是零,也说明该任务组没有任务需要调度。
2.5 负载计算代码实现
首先是公式:
u' = (u + d1) y^p + 1024 \Sum y^n + d3 y^0
n=1
= u y^p + (Step 1)
p-1
d1 y^p + 1024 \Sum y^n + d3 y^0 (Step 2)
上述公式分为两个部分实现,accumulate_sum 函数计算 step1部分,然后调用__accumulate_pelt_segments() 函数计算 step2 部分:
static __always_inline u32
accumulate_sum(u64 delta, int cpu, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
unsigned long scale_freq, scale_cpu;
u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */
u64 periods;
scale_freq = arch_scale_freq_capacity(cpu);
scale_cpu = arch_scale_cpu_capacity(NULL, cpu);
delta += sa->period_contrib; /* 1 */
periods = delta / 1024; /* A period is 1024us (~1ms) */ /* 2 */
/*
* Step 1: decay old *_sum if we crossed period boundaries.
*/
if (periods) {
sa->load_sum = decay_load(sa->load_sum, periods); /* 3 */
sa->runnable_load_sum = decay_load(sa->runnable_load_sum, periods);
sa->util_sum = decay_load((u64)(sa->util_sum), periods);
/*
* Step 2
*/
delta %= 1024;
contrib = __accumulate_pelt_segments(periods, /* 4 */
1024 - sa->period_contrib, delta);
}
sa->period_contrib = delta; /* 5 */
contrib = cap_scale(contrib, scale_freq);
if (load)
sa->load_sum += load * contrib;
if (runnable)
sa->runnable_load_sum += runnable * contrib;
if (running)
sa->util_sum += contrib * scale_cpu;
return periods;
}
period_contrib记录的是上次更新负载不足1024us周期的时间。delta是经过的时间,为了计算经过的周期个数需要加上period_contrib,然后整除1024。- 计算周期个数。
- 调用
decay_load()函数计算公式中的step1部分。 __accumulate_pelt_segments()负责计算公式step2部分。- 更新
period_contrib为本次不足1024us部分。
下面分析__accumulate_pelt_segments()函数:
static u32 __accumulate_pelt_segments(u64 periods, u32 d1, u32 d3)
{
u32 c1, c2, c3 = d3; /* y^0 == 1 */
/*
* c1 = d1 y^p
*/
c1 = decay_load((u64)d1, periods);
/*
* p-1
* c2 = 1024 \Sum y^n
* n=1
*
* inf inf
* = 1024 ( \Sum y^n - \Sum y^n - y^0 )
* n=0 n=p
*/
c2 = LOAD_AVG_MAX - decay_load(LOAD_AVG_MAX, periods) - 1024;
return c1 + c2 + c3;
}
__accumulate_pelt_segments()函数主要的关注点应该是这个c2是如何计算的。本来是一个多项式求和,非常巧妙的变成了一个很简单的计算方法。这个转换过程如下:
p-1
c2 = 1024 \Sum y^n
n=1
In terms of our maximum value:
inf inf p-1
max = 1024 \Sum y^n = 1024 ( \Sum y^n + \Sum y^n + y^0 )
n=0 n=p n=1
Further note that:
inf inf inf
( \Sum y^n ) y^p = \Sum y^(n+p) = \Sum y^n
n=0 n=0 n=p
Combined that gives us:
p-1
c2 = 1024 \Sum y^n
n=1
inf inf
= 1024 ( \Sum y^n - \Sum y^n - y^0 )
n=0 n=p
= max - (max y^p) - 1024
LOAD_AVG_MAX其实就是1024(1 + y + y2 + ... + yn)的最大值,计算方法很简单,等比数列求和公式一套,然后n趋向于正无穷即可。最终LOAD_AVG_MAX的值是47742。
上述的公式最终由 ___update_load_sum 调用:
static __always_inline int
___update_load_sum(u64 now, int cpu, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u64 delta;
delta = now - sa->last_update_time;
/*
* This should only happen when time goes backwards, which it
* unfortunately does during sched clock init when we swap over to TSC.
*/
if ((s64)delta < 0) {
sa->last_update_time = now;
return 0;
}
/*
* Use 1024ns as the unit of measurement since it's a reasonable
* approximation of 1us and fast to compute.
*/
delta >>= 10;
if (!delta) // pelt 周期单位为 1us,时间不足 1us 不需要进行负载更新。
return 0;
sa->last_update_time += delta << 10;
/*
* running is a subset of runnable (weight) so running can't be set if
* runnable is clear. But there are some corner cases where the current
* se has been already dequeued but cfs_rq->curr still points to it.
* This means that weight will be 0 but not running for a sched_entity
* but also for a cfs_rq if the latter becomes idle. As an example,
* this happens during idle_balance() which calls
* update_blocked_averages()
*/
if (!load)
runnable = running = 0;
/*
* Now we know we crossed measurement unit boundaries. The *_avg
* accrues by two steps:
*
* Step 1: accumulate *_sum since last_update_time. If we haven't
* crossed period boundaries, finish.
*/
if (!accumulate_sum(delta, cpu, sa, load, runnable, running))
return 0;
return 1;
}
___update_load_sum有如下几个调用点:
1. __update_load_avg_blocked_se // 对调度实体衰减过去负载,不会对累加当前负载,一般用于 idle 上,没有任务运行,则只需要对过去负载(一般是阻塞任务)进行衰减。
2. __update_load_avg_se // 根据参数更新调度实体负载,会累加当前负载。
3. __update_load_avg_cfs_rq // 更新对应 cfs_rq 的负载。
...
当上述函数计算负载有变化时会调用
___update_load_avg // 根据总负载更新平均负载,平均利用率。
针对频繁运行的进程,load_avg的值会越来越接近权重weight。例如,权重1024的进程长时间运行,其负载贡献曲线如下。上面的表格是进程运行的时间,下表是负载贡献曲线。
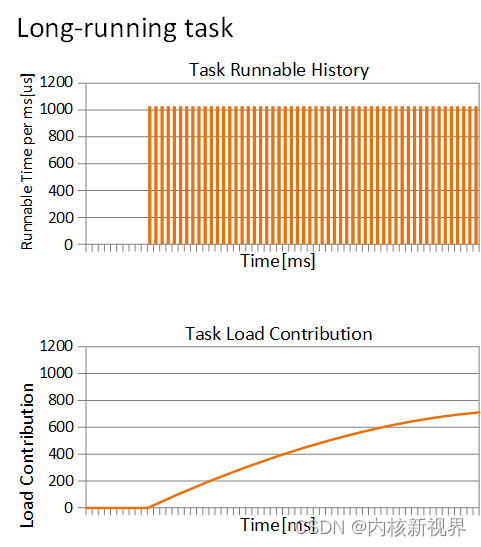
从某一时刻进程开始运行,负载贡献就开始一直增加。现在如果是一个周期运行的进程(每次运行1ms,睡眠9ms),那么负载贡献曲线图如何呢?
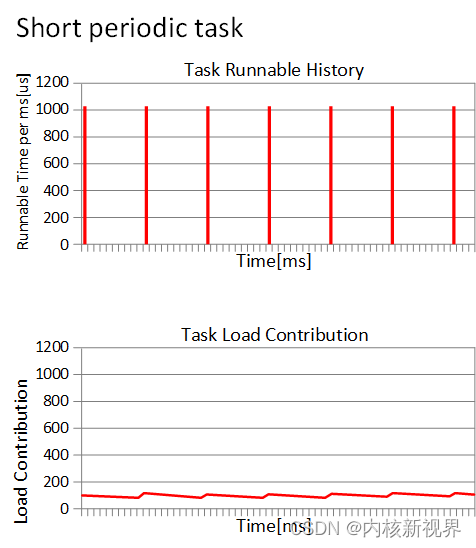
负载贡献的值基本维持在最小值和最大值两个峰值之间。这也符合我们的预期,我们认为负载贡献就是反应进程运行的频繁程度。因此,基于PELT算法,我们在负载均衡的时候,可以更清楚的计算一个进程迁移到其他CPU的影响。
3 负载更新的各处调用点
(1) __update_load_avg_blocked_se
/*
* Synchronize entity load avg of dequeued entity without locking
* the previous rq.
*/
void sync_entity_load_avg(struct sched_entity *se)
{
struct cfs_rq *cfs_rq = cfs_rq_of(se);
u64 last_update_time;
last_update_time = cfs_rq_last_update_time(cfs_rq);
__update_load_avg_blocked_se(last_update_time, cpu_of(rq_of(cfs_rq)), se);
}
在 sync_entity_load_avg 中将会调用 __update_load_avg_blocked_se,sync_entity_load_avg 函数作用描述在不锁定 rq 的情况下同步出队实体的负载,即只对过去负载进行更新。
(2)__update_load_avg_se
对调度实体负载进行更新,将在 update_load_avg 中调用。
(2)__update_load_avg_cfs_rq
对 cfs_rq 队列的更新,将在 update_cfs_rq_load_avg 中调用,而update_cfs_rq_load_avg 的调用有:
update_load_avg,update_blocked_averages 两个函数中,其中 update_blocked_averages 的调用将是在负载均衡期间,以及进入 idle cpu 之前和之后调用。
通过上述描述,可以看到负载更新都集中在 update_cfs_rq_load_avg 和 update_load_avg 中。下面详细分析这两个函数。
3.1 update_cfs_rq_load_avg
update_cfs_rq_load_avg 更新 cfs_rq 队列负载:
static inline int
update_cfs_rq_load_avg(u64 now, struct cfs_rq *cfs_rq)
{
unsigned long removed_load = 0, removed_util = 0, removed_runnable_sum = 0;
struct sched_avg *sa = &cfs_rq->avg;
int decayed = 0;
if (cfs_rq->removed.nr) { ----------------------------------------(1)
unsigned long r;
u32 divider = LOAD_AVG_MAX - 1024 + sa->period_contrib;
raw_spin_lock(&cfs_rq->removed.lock);
swap(cfs_rq->removed.util_avg, removed_util);
swap(cfs_rq->removed.load_avg, removed_load);
swap(cfs_rq->removed.runnable_sum, removed_runnable_sum);
cfs_rq->removed.nr = 0;
raw_spin_unlock(&cfs_rq->removed.lock);
r = removed_load;
sub_positive(&sa->load_avg, r);
sub_positive(&sa->load_sum, r * divider);
r = removed_util;
sub_positive(&sa->util_avg, r);
sub_positive(&sa->util_sum, r * divider);
add_tg_cfs_propagate(cfs_rq, -(long)removed_runnable_sum); ------(2)
decayed = 1;
}
decayed |= __update_load_avg_cfs_rq(now, cpu_of(rq_of(cfs_rq)), cfs_rq); -----(3)
#ifndef CONFIG_64BIT
smp_wmb();
cfs_rq->load_last_update_time_copy = sa->last_update_time;
#endif
if (decayed)
cfs_rq_util_change(cfs_rq, 0); --------------------------------------(4)
return decayed;
}
(1)当对cfs_rq队列负载进行更新时,如果当前 cfs_rq->removed.nr 不为零,则说明有有需要移除的负载在该cfs_rq上,我们需要将该部分负载移除。如果任务处于睡眠状态触发迁移操作,则会标记p->wake_cpu为 new_cpu,在任务 try_to_wake_up 中调用 migrate_task_rq_fair 添加任务实体负载到此处,并在更新cfs_rq 队列负载时移除,大致流程如下:
try_to_wake_up
-> if (task_cpu(p) != cpu)
set_task_cpu(p, cpu)
-> p->sched_class->migrate_task_rq(p, new_cpu)
-> migrate_task_rq_fair
-> if (p->on_rq != TASK_ON_RQ_MIGRATING)
remove_entity_load_avg(&p->se)
-> sync_entity_load_avg(se) // 同步更新阻塞负载
-> ++cfs_rq->removed.nr ... // 附加负载到 cfs_rq->removed 上,后续update_cfs_rq_load_avg中移除。
update_load_avg
update_blocked_averages
-> update_cfs_rq_load_avg // 任务状态更新,负载均衡中更新 cfs_rq 负载。
可以看到有迁移附加到 removed 的负载将在上述流程中移除。
(2)如果负载被移除则 cfs_rq 队列负载发生变化,则会调用 add_tg_cfs_propagate 把变化的 load_sum 负载从底向上标记为需要广播,向上通知负载的变化量,以便每个调度任务组实体更新自身负载。
(3)调用 __update_load_avg_cfs_rq 更新当前 cfs_rq 队列负载(做衰减,remove有移除也一并更新了)。
(4)cfs_rq 队列负载有变化,则在这里向电源管理提供信息,根据 util_sum 信息看看是否有必要调频。
最后函数会返回队列负载是否有变化,以便调用函数根据这个信息进行任务组的 load_avg 更新。
3.2 update_load_avg
根据上文信息可以得知,负载更新调用最频繁的函数是 update_load_avg,这个函数完成所有阶段的负载更新,包括调度实体,cfs_rq 队列,广播负载,更新任务组负载。而该函数的调用点有下面这些地方:
enqueue_entity
-> unthrottle_cfs_rq // 解除 cfs_rq 带宽限制时调用。
-> do_cfs_timer_xxx // 对带宽限制资源补充或者到期时调用。
-> enqueue_task_fair // 任务入队时调用。
dequeue_entity
-> dequeue_task_fair // 任务出队时调用。
set_next_entity
-> pick_next_task_fair // 选择下一个任务时调用。
-> set_curr_task_fair // 设置当前任务时调用。
put_prev_entity
-> pick_next_task_fair // 选择下一个任务时调用。
-> put_prev_task_fair // 更新上一个任务时调用。
update_blocked_averages
-> _nohz_idle_balance // 进入 nohz 模式时调用以便更新阻塞负载。
-> idle_balance // 同上在 idle cpu进行负载均衡检测时调用,同步更新 idle cpu上阻塞任务负载
-> run_rebalance_domains // 负载均衡时调用。
propagate_entity_cfs_rq
-> detach_entity_cfs_rq // 将一个任务移出某个 cfs_rq 队列时调用。
-> attach_entity_cfs_rq // 将一个任务加入某个 cfs_rq 队列时调用。
detach_entity_cfs_rq // 同上
attach_entity_cfs_rq // 同上
sched_group_set_shares // 设置任务组 shares 文件时调用。
可以看到负载的更新是在整个调度器任务状态发生变化时均可能会触发调用,代码如下:
static inline void update_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
u64 now = cfs_rq_clock_task(cfs_rq);
struct rq *rq = rq_of(cfs_rq);
int cpu = cpu_of(rq);
int decayed;
/*
* Track task load average for carrying it to new CPU after migrated, and
* track group sched_entity load average for task_h_load calc in migration
*/
if (se->avg.last_update_time && !(flags & SKIP_AGE_LOAD))
__update_load_avg_se(now, cpu, cfs_rq, se); -----------------(1)
decayed = update_cfs_rq_load_avg(now, cfs_rq); -----------------(2)
decayed |= propagate_entity_load_avg(se); -----------------------(3)
if (!se->avg.last_update_time && (flags & DO_ATTACH)) {
/*
* DO_ATTACH means we're here from enqueue_entity().
* !last_update_time means we've passed through
* migrate_task_rq_fair() indicating we migrated.
*
* IOW we're enqueueing a task on a new CPU.
*/
attach_entity_load_avg(cfs_rq, se, SCHED_CPUFREQ_MIGRATION); -(4)
update_tg_load_avg(cfs_rq, 0); -------------------------------(5)
} else if (decayed && (flags & UPDATE_TG))
update_tg_load_avg(cfs_rq, 0); -------------------------------(6)
}
(1)对于正在该 cfs_rq 队列上运行的调度实体并且不跳过负载更新则会去进行调度实体的负载更新。如果 last_update_time 为零说明任务是新任务或者是从其他 cpu 迁移而来,那么此时的任务是没有负载的不需要去进行更新。
(2)更新对应 cfs_rq 队列负载,包括移除 removed 中负载,如果负载变化还需要标记变化的 load_sum 需要向上广播。并可能触发调频操作。
(3)在这里检验 cfs_rq 是否有标记广播负载,如果有则会更新 cfs_rq 对应的任务组 se 的负载并且继续标记广播,直至顶层。
(4)同(1)对于新任务或者迁移而来的任务我们需要把调度实体的负载累加到当前 cfs_rq 以及更新任务组对应的 se 上。
(5)cfs_rq 队列有新负载更新,那么把更新对应任务组的总负载load_avg。
(6)如果负载变化并且标记为 UPDATE_TG 说明需要更新任务组 load_avg。
3.3 update_cfs_group
上述的负载更新后怎么使用呢?在 update_cfs_group 中将会把累加到任务组的负载和任务组shares进行计算更新到对应任务组 se 的权重中,参与任务组时间片计算,代码如下:
static void update_cfs_group(struct sched_entity *se)
{
struct cfs_rq *gcfs_rq = group_cfs_rq(se);
long shares, runnable;
if (!gcfs_rq)
return;
if (throttled_hierarchy(gcfs_rq)) // 对于已经限流的 cfs_rq 不需要进行权重更新。
return;
shares = calc_group_shares(gcfs_rq); // 根据任务组负载贡献和shares值返回一个新的权重值,后续更新对对应cfs_rq权重中。
runnable = calc_group_runnable(gcfs_rq, shares); // 不重要
reweight_entity(cfs_rq_of(se), se, shares, runnable); // 计算新的 se 权重,更新se负载以及对应 cfs_rq 负载。
}
static void reweight_entity(struct cfs_rq *cfs_rq, struct sched_entity *se,
unsigned long weight, unsigned long runnable)
{
if (se->on_rq) {
/* commit outstanding execution time */
if (cfs_rq->curr == se)
update_curr(cfs_rq);
account_entity_dequeue(cfs_rq, se);
dequeue_runnable_load_avg(cfs_rq, se);
}
dequeue_load_avg(cfs_rq, se); // se 负载需要重新计算,把原有的负载暂时先从 cfs_rq 中移除
se->runnable_weight = runnable;
update_load_set(&se->load, weight); // 设置se一个新的权重,由 calc_group_shares 计算。
#ifdef CONFIG_SMP // 更新 se 的负载
do {
u32 divider = LOAD_AVG_MAX - 1024 + se->avg.period_contrib;
se->avg.load_avg = div_u64(se_weight(se) * se->avg.load_sum, divider);
se->avg.runnable_load_avg =
div_u64(se_runnable(se) * se->avg.runnable_load_sum, divider);
} while (0);
#endif
enqueue_load_avg(cfs_rq, se); // se 已更新,把新的负载重新附加到 cfs_rq 上。
if (se->on_rq) {
account_entity_enqueue(cfs_rq, se);
enqueue_runnable_load_avg(cfs_rq, se);
}
}
权重计算可以参考第一篇中 grq->se.load 描述的权重计算过程。














 933
933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









