






论文地址:https://www.aclweb.org/anthology/P19-1129.pdf
文章标题:Entity-Relation Extraction as Multi-turn Question Answering(实体关系提取作为多轮问题的回答)ACL2019
Abstract
本文提出了一种新的实体关系抽取方法。我们将任务转换为一个多回合的问题回答问题,即,实体和关系的提取被转化为从上下文中识别答案的任务。这种多轮QA形式化有几个关键的优点:首先,问题查询为我们想要识别的实体/关系类编码重要信息;其次,QA为实体与关系的联合建模提供了一种自然的方式;第三,它使我们能够利用发展良好的机器阅读理解(MRC)模型。
在ACE和CoNLL04语料库上的实验表明,所提出的范例明显优于先前的最佳范例。我们能够获得所有ACE04、ACE05和CoNLL04数据集的最新结果,这三个数据集的SOTA结果分别为49.4(+1.0)、60.2(+0.6)和68.9(+2.1)。
此外,我们建构了一个新开发的中文资料库,它需要多步骤的推理来建构实体的相依性,而不是单一步骤的相依性萃取。所提出的多回合质量保证模型在简历数据集上也达到了最佳的性能。
一、Introduction
识别实体及其关系是从非结构化的原始文本中提取结构化知识的前提,近年来人们对非结构化的原始文本越来越感兴趣。给定一组自然语言文本,实体-关系提取的目标是将其转换为结构化的知识库。例如,给定以下文本:

我们需要提取四种不同类型的实体,即三种关系:建立关系、建立时间关系和服务角色关系。文本将被转换为表1中所示的结构数据集。
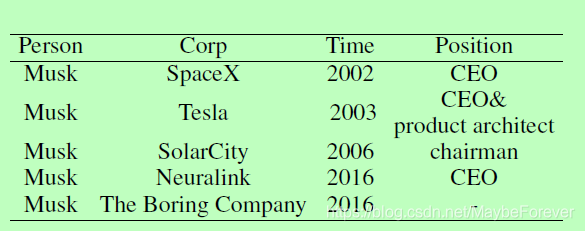
表一:提取的结构表的说明。
大多数现有的模型通过从文本中提取三元组列表来完成此任务,即REL(e1; e2)表示实体e1与实体e2之间的关系REL。以前的模型主要分为两大类:流水线方法,它首先使用标记模型来识别实体,然后使用关系提取模型来识别每个实体对之间的关系;联合方法通过约束或参数共享等不同策略,将实体模型与关系模型相结合。
当前的方法在任务形式化和算法方面存在几个关键问题。在形式化层次上,REL(e1;e2)三元组结构不足以充分表达文本背后的数据结构。以Musk为例,标签之间存在层次依赖关系:时间的提取依赖于位置,因为一个人可以在不同的时间段内担任公司的多个位置。职位的选择也取决于公司,因为一个人可以在多家公司工作。在算法层面,对于大多数现有的关系提取模型(Miwa和Bansal, 2016;王等,2016a;(Ye et al., 2016),模型的输入是两个标记提及的原始语句,输出是两个提及之间是否存在关系。Wang et al. (2016a)指出;Zeng et al.(2018),在这种形式化过程中,神经模型很难捕捉到所有的词汇、语义和句法线索,特别是当(1)实体距离较远的时候;(2)一个实体涉及多个三元组;或(3)关系跨有重叠。
本文提出一个新的范式去解决关系抽取问题,将关系抽取任务顶一个多轮问答任务:每个实体类型和关系类型由问答模板表征,实体和关系通过回答模板问题来提取。答案是文本跨度(text spans),使用现在标准的机器阅读理解(MRC)框架提取:预测给定上下文时的答案跨度。
Q:在文本中谁被提及? A:Musk
Q:Musk为哪一个公司工作? A:SpaceX, Tesla, SolarCity, Neuralink
and The Boring Company
Q:Musk在SpackX中的职位是什么? A:CEO
将实体关系抽取任务当做多轮QA有以下优势:(1)多轮QA的设置提供了优雅的方式捕获标注的层级依赖。随着多轮QA的进行,可以逐步获得下一轮所需的实体。这与多轮槽填充对话系统类似。(2)问题查询编码需要识别的关系分类的重要先验知识。这种信息性可以潜在地解决现有关系抽取模型无法解决的问题,例如实体对之前距离较远,关系跨度重叠等;(3)QA框架提供了一种同时提取实体和关系的自然方式:大多数MRC模型支持输出特殊的NONE标记,表明该问题没有答案。通过这样,原始的两个任务-实体抽取和关系抽取可以合并到单独的QA任务中:如果对应于该关系的问题的返回答案不是NONE,则关系成立,并且此返回的答案是希望提取的实体。
在本文中,我们证明了所提出的范例,将实体-关系抽取任务转换成多回合的QA任务,在现有的系统上引入了显著的性能提升。它在ACE和CoNLL04数据集上实现了最先进的(SOTA)性能。这些数据集上的任务被形式化为三重抽取问题,其中两次QA就足够了。因此,我们建立了一个更复杂和更困难的数据集称为RESUME,它需要从原始文本中提取个人的传记信息。从RESUME构建结构化知识库需要四到五次QA。我们还表明,这种多回合QA设置可以很容易地集成强化学习(就像在多回合对话系统中一样),以获得额外的性能提升。
本文的其余部分组织如下:第二节详细介绍了相关工作。我们在第3节中描述了数据集和设置,在第4节中描述了提出的模型,在第5节中描述了实验结果。我们在第6节对本文进行了总结。
二、Related Work
2.1、Extracting Entities and Relations
许多早期的实体-关系提取系统都是流水线的(Zelenko et al., 2003;Miwa等人,2009;陈和罗斯,2011年;Lin et al., 2016):实体提取模型首先识别感兴趣的实体,然后关系提取模型构建被提取实体之间的关系。尽管流水线系统可以灵活地集成不同的数据源和学习算法,但是它们会受到错误传播的严重影响。
为了解决这一问题,提出了联合学习模型。早期的联合学习方法通过各种依赖关系将两个模型连接起来,包括用整数线性规划求解的约束(Yang and Cardie, 2013;Roth和Yih, 2007),卡片金字塔解析(Kate和Mooney, 2010),和全球概率图形模型(Yu和Lam, 2010;辛格等人,2013)。在后来的研究中,Li和Ji(2014)使用结构化感知器和有效的集束搜索来提取实体提及和关系,这比基于约束的方法更有效,更省时。Miwa和Sasaki (2014);Gupta等人(2016);Zhang等人(2017)提出了表格填充方法,该方法提供了将更复杂的特征和算法纳入模型的机会,如解码中的搜索顺序和全局特征。神经网络模型在文献中也得到了广泛的应用。Miwa和Bansal(2016)提出了一种端到端方法,使用具有共享参数的神经网络模型提取实体及其关系,即,使用神经标记模型提取实体,使用基于树LSTMs的神经多类分类模型提取关系(Tai et al., 2015)。Wang等人(2016a)利用多级注意力CNNs提取关系。Zeng等人(2018)提出了一种新的框架,利用序列到序列模型生成实体关系三元组,将实体检测与关系检测自然地结合起来。
另一种将实体和关系提取模型进行绑定的方法是采用强化学习或最小风险训练,其中训练信号是基于两个模型的联合决策给出的。Sun等(2018)优化了全局损失函数,在最小风险训练框架下联合训练两个模型。Takanobu等(2018)采用分层强化学习的方法,以分层的方式提取实体和关系。
2.2、Machine Reading Comprehension
主流MRC模型(Seo等,2016;王和江,2016;熊等,2017;Wang等人,2016b)提取给定查询的段落中的文本跨度。文本跨度提取可以简化为两个多类分类任务,即,预测答案的起始和结束位置。类似的策略可以扩展到多通道MRC (Joshi et al., 2017;(Dunn et al., 2017),答案需要从多个段落中选择。多通道的MRC任务通过连接通道可以很容易地简化为单通道的MRC任务(Shen et al., 2017;Wang et al., 2017b)。Wanget al. (2017a)首先对文章进行排序,然后对选定的文章运行单段MRC。Tan等(2017)将文章排名模型与阅读理解模型联合训练。训练前的方法如BERT (Devlin et al., 2018)或Elmo (Peters et al., 2018)已被证明对MRC任务非常有帮助。
有将非QA NLP任务转换为QA任务的趋势(McCann et al., 2018)。我们的工作深受Levy等人(2017)的启发。Levy等人(2017)和McCann等人(2018)专注于识别两个预定义实体之间的关系,并将关系提取任务形式化为单轮QA任务。在本文中,我们研究了一个更复杂的场景,其中需要对分层标签依赖关系进行建模,单轮QA方法不再适用。我们证明,我们的多回合质量保证方法能够解决这一挑战,并获得新的最先进的结果。
三、Datasets and Tasks
3.1、ACE04, ACE05 and CoNLL04
ACE04定义了7种实体类型:Person (PER)、Organization (ORG)、Geographical Entities (GPE)、Location (loc)、Facility (FAC)、Weapon (WEA)、Vehicle (VEH)。七种关系:Physical ( PHYS )、Person-Social ( PER-SOC )、Employment-Organization ( EMP-ORG )、Agent-Artifact ( ART )、PER/ORG Affiliation ( OTHER-AFF )、GPE- Affiliation ( GPE-AFF )、Discourse ( DISC )。
ACE05依据ACE04构建,实体类型不变,6种关系类型如下:Person-Social (PER-SOC)、Agent-Artifact (ART)、PER/ORG Affiliation (OTHER-AFF)、Physical (PHYS)、PART-WHOLE、EMP-ORG。注:删除DISC,EMP-ORG和OTHER-AFF合并为EMP-ORG(新的),PHYS拆分为PHYS和PART-WHOLE(新的)。
CoNLL04实体及关系类型如下:四种实体:LOC、ORG、PER、OTHERS。五种关系:located in、work for、organization based in、live in、kill。
3.2、RESUME: A newly constructed dataset
ACE和CoNLL-04数据集是为了用来做三元组抽取的,并且两轮的QA已经足够抽取出其中的三元组:一轮用来抽取头实体,另一轮用来同时抽取尾实体和关系。这两个数据集都没有包含类似于之前Musk例子中的层次(hierarchical)实体关系,然而这种情况在现实生活中是很常见的。
因此,本文构建了一个新的数据集–RESUME,从IPO招股说明书中描述管理团队的章节中提取了841段内容。每一段都描述了一位高管的一些工作经历,主要是想从简历中提取结构数据。数据集是中文的,例子如下:


此数据集定义了四种类型的实体:①Person (the name of the executive)② Company (the company that the executive works/worked for) ③Position (the position that he/she holds/held) ④Time (the time period that the executive occupies/occupied that position)。值得注意的是,一个人可以在不同时期为不同的公司工作,也可以在同一公司的不同时期担任不同的职务。
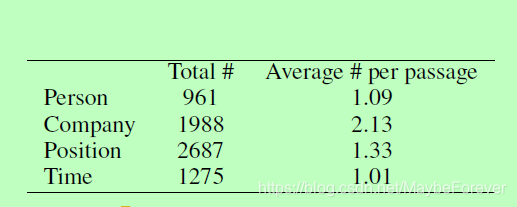
表二:RESUME数据集的统计信息。
我们征集了合伙人员以填补表1中的槽位(slot)。每个段落均由两个不同的合伙人员标记。 如果两个注释者的标签不一致,则要求一个或多个注释者为句子加上标签,并以多数票作为最终决定。 由于文本的措词通常非常明确和正式,因此注释者之间的共识非常高,所有槽位的价值达到93.5%。 表2中显示了该数据集的一些统计数据。我们将数据集随机分为训练(80%),验证(10%)和测试集(10%)。
四、Model
4.1、System Overview
算法的伪代码如Algorithm 1(下图)所示,大概分为两个阶段:

(1)头实体抽取阶段(4-9行)
多回合问答的每个步骤均由一个实体触发,为了抽取这个头实体,本文使用EntityQuesTemplates(第四行)将每个实体类型转化为一个问题,实体e可以通过回答问题(第五行)抽取。如果系统输出了特殊的NONE结果,这意味着s没有包含任何符合类型的实体。
(2)关系和尾实体抽取阶段(10-24行)
ChainOfRelTemplates定义了一个关系链,我们需要按照该关系链的顺序进行多轮QA,因为一些实体的抽取式依赖于其他实体的抽取。举个例子,在RESUME数据集中,一个高管的职位取决于他所工作的公司,并且时间实体的抽取依赖于公司和职位。当然,抽取的顺序是需要手动预定义的。ChainOfRelTemplates同样定义了每个关系的模板,每个模板包含了一些待填充的槽。为了生成一个问题(14行),我们将先前抽取的头实体插入到模板槽中,这样的话,关系REL和尾实体e可以通过回答生成的问题(15行)进行联合抽取。如果返回了NONE,那么说明给定的句子没有答案。
值得注意的是:头实体抽取阶段所抽取到的实体可能并不都是头实体。在关系和尾实体抽取阶段,从第一阶段得到的实体最初被假定为头实体,并将其馈送到模板以生成问题。如果从第一阶段抽取的实体e确实是一个头实体,那么QA模型将会通过回答相应的问题来提取头实体,否则答案将会制定为NONE并忽略掉。
对于ACE04、ACE05和CoNLL04数据集而言,只需要两轮的QA即可解决问题,所以ChainOfRelTemplates只需要包含一个链。对于RESUME而言,需要抽取4个实体,所以ChainOfRelTemplates需要包含三个链。
4.2、Generating Questions using Templates
每个实体类型都与模板生成的特定类型问题相关联。使用模板生成问题的两种方法:自然语言问题和伪问题。对于伪问题而言,它不一定是符合语法规则的。例如:对于设施(Facility)这种类型而言,(1)自然语言问句可以为:Which facility is mentioned in the text。(2)伪问题为:entity: facility。
在关系和尾实体抽取阶段,可以通过将特定于关系的模板与提取的头实体组合来生成问题。这个问题可以是一个自然语言问题,也可以是一个伪问题。例如表3和表4中的例子:
4.3、Extracting Answer Spans via MRC
目前为止,很多种机器阅读理解模型(MRC)被提出来,例如BiDAF和QANet。在标准的MRC设置中,给定一个问题Q={q1,q2,…,qNq},其中Nq表示问题Q中单词的个数,上下文C={c1,c2,…,cNc}其Nc表示上下文C中单词的个数,我们需要预测答案的跨度(span)。对于QA框架而言,本文使用BERT作为骨干。BERT使用transformer对大规模数据集进行双向语言模型的预训练,并在MRC数据集(例如:SQUAD)上取得了SOTA效果。为了与BERT模型对齐,问题Q和上下文C被合并到列表中:[CLS,Q,SEP,C,SEP],其中CLS和SEP都是特殊的token,Q是token化的问题,C是上下文。每个上下文token的表示是通过使用多层的transformer获得的。
传统的MRC模型(Wang and Jiang,2016; Xiong et al., 2017)通过将两个softmax层应用于上下文token来预测开始和结束索引,这种基于softmax的跨度抽取策略仅仅适用于单答案抽取任务,但是对于本文的任务不合适,因为在本文的环境中,一句话/段落可能会获得多个答案。为了解决这个问题,本文将任务转化为基于查询的标记问题(Lafferty et al., 2001; Huang et al., 2015;Ma and Hovy, 2016)。特别地,在给定查询的情况下,本文为上下文中的每个token预测一个BMEO(beginning, inside, ending 和 outside)标签。每个单词的表示都会馈送到softmax层并输出一个BMEO标签,可以认为我们正在将预测开始和结束索引的两个N类分类任务(其中N表示句子的长度)转换为N个5类分类任务(此处可以理解为beginning, inside, ending , outside 和 other)。
Training and Test 在训练的时候,本文共同训练了两个阶段的目标函数:

其中,λ∈[0,1]是控制两个目标之间权衡的参数,在验证集上可以调整其值。这两个模型都是通过标准的BERT模型进行初始化的,并且在悬链的过程中共享参数。在测试的时候,head-entities和tail-entities是基于两个目标分别抽取的。
4.4、Reinforcement Learning
在本文的设定中,在一轮中抽取的答案不仅仅影响到自身的准确率,还会影响到下游轮次中问题的构建,反过来还会影响到后面的准确率。我们觉得采用强化学习来解决这个问题。
Action and Policy在RL设定中,我们需要定义行为(action)和策略(policy)。在多轮QA设定中:action是在每个回合中选择一个文本范围(span),policy定义了在给定问题和上下文的情况下选择某个范围(span)的可能性。 由于算法依赖于BMEO标注的输出,因此选择某个跨度w1,w2…,wn的概率是将w1分配给B(beginning),w2,…,wn−1分配给M(inside)和wn被分配给E(end)的联合概率,公式如下:
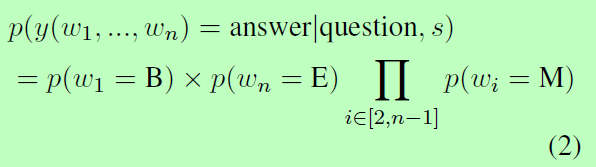
Reward对于给定的句子s,我们使用正确检索的三元组数作为奖励。我们使用REINFORCE算法(Williams, 1992)–一种策略梯度方法,用于找到使期望收益Eπ[R(w)]最大化的最优策略。其中,期望值是通过从策略π采样来近似得到,并使用似然比来计算梯度:
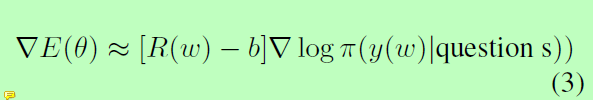
其中b表示基准值。对于多回合QA设置中的每回合,正确回答都会赢得+1的奖励,这所有轮奖励的累加便可以得到最终的奖励值。基线准设置为所有先前奖励的平均值。我们不会从头开始初始化策略网络,而是使用上一节中描述的经过预先训练的头实体和尾实体抽取模型。我们还使用体验重播策略(experience replay
strategy,Mnih et al,2015):对于每一个batch,一半示例通过模拟得来,而另一半则是从先前生成的示例中随机选择的。
对于RESUME数据集,本文采用课程学习的策略(curriculum learning, Bengio et al., 2009),在训练过程中逐渐将轮次从2提升到4。
五、Experimental Results
5.1、Results on RESUME
根据Person(第一轮),Company(第二轮),Position(第三轮)和Time(第四轮)的顺序提取答案,并且每个答案的提取取决于之前的答案。
对于基线,我们首先实现一个联合模型,在该模型中一起训练了实体抽取和关系抽取(以标签+关系表示)。 如Zheng等人(2017年)的工作,使用BERT标记模型提取实体,并通过将CNN应用于BERTtransformer输出的表示来提取关系。
涉及实体和关系识别阶段(管道或联合)的现有基准模型非常适合于三元组提取,但并不是真正适合本文的设置,因为在第三和第四轮中,需要更多的信息来确定关系,而不仅仅是两个实体。例如,例如,要提取Postion,我们需要Person和Company,而提取时间,我们需要Person,Company和Position。这类似于依赖项解析任务,但在标签级别而非单词级别(Dozat和Manning,2016; Chen和Manning,2014)。因此,本文提出了以下基准,该基准将先前的实体+关系策略修改为实体+依赖关系,用标签+依赖表示。本文使用BERT标记模型为每个单词分配标记标签,并修改当前的SOTA依存关系解析模型Biaffine(Dozat和Manning,2016)来构建标记之间的依存关系。Biaffine依赖模型和实体抽取模型是共同训练的。
结果如表5所示。从中可以看出,标签+依赖模型优于标签+关系模型。本文提出的多轮QA模型表现最佳,而RL增加了其性能提升。 特别地,对于仅需要单轮QA的Person提取,多轮QA + RL模型的执行与多轮QA模型相同。 标记+关系和标记+依赖性也是如此。
5.2、Results on ACE04, ACE05 and CoNLL04
对于ACE04,ACE05和CoNLL04数据集而言,仅需要进行两轮QA。对于评估,我们记录了实体和关系的 micro-F1、精确度和召回率(表6、7和8),如Li and Ji (2014); Miwa and Bansal (2016);Katiyar and Cardie (2017); Zhang et al. (2017)等。在ACE04数据集中,对于实体提取,本文提出的多轮QA模型已经比以前的SOTA增长了1.8%,对于关系提取,其增长了1.0%。对于ACE05,对于实体提取,建议的多回转QA模型优于先前的SOTA,对于实体提取而言,性能提高了+ 1.2%,对于关系提取,性能提高了+ 0.6%。对于CoNLL04,本文提出的多轮QA模型在关系F1上提升了2.1%。
六、Ablation Studies
6.1、Effect of Question Generation Strategy
在本小节中,将比较自然语言问题和伪问题的影响,具体的结果见表9。
从中可以看到自然语言问题在所有数据集上都实现了严格的F1改进,这是因为自然语言问题提供了更细粒度的语义信息,并且可以帮助实体/关系提取。 相比之下,伪问题提供了实体和关系类型的粗粒度,模棱两可和隐式提示,这甚至可能使模型混乱。
6.2、Effect of Joint Training
本文主要将实体关系提取任务分解为两个子任务:用于头实体提取的多答案任务和用于联合关系和尾实体提取的单答案任务,然后共同训练两个共享参数的模型,并用参数λ控制两个子任务之间的权衡:
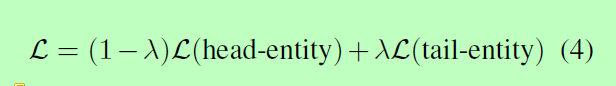
ACE05数据集上有关λ的不同值的结果如下表所示:
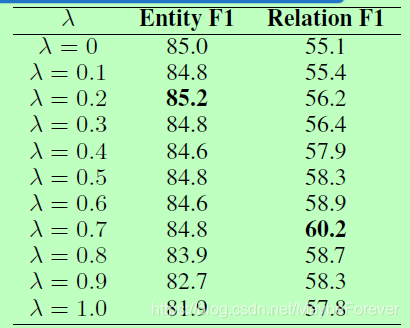
当λ设置为0时,该系统基本上仅在头实体预测任务上训练。 有趣的是,λ= 0不会导致最佳的实体提取性能。 这表明第二阶段关系提取实际上有助于第一阶段实体提取,这再次证实了将这两个子任务一起考虑的必要性。 对于关系提取任务,当λ设置为0.7时可获得最佳性能。
6.3、Case Study
表10将多轮QA模型的输出与以前的SOTA MRT模型的输出进行了比较(Sun等,2018):
在第一个示例中,MRT无法识别john scottsdale和伊拉克之间的关系,因为这两个实体相距太远,但是我们提出的QA模型能够处理此问题。
在第二个示例中,句子包含两对相同关系。 MRT模型很难确定如何处理这种情况,无法定位ship实体及其相关的关系,多轮QA模型则可以处理这种情况。
七、Conclusion
在本文中,我们提出了一个多回合的问题回答范例来完成实体-关系抽取的任务。我们在3个基准数据集上实现了新的最先进的结果。我们还构造了一个新的实体-关系提取数据集,该数据集需要层次关系推理,所提出的模型达到了最佳的性能。














 2762
2762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









