







转自:https://blog.csdn.net/u011564172/article/details/53310530
概要
RDD是为了处理迭代算法和数据发掘应运而生的,keep数据在内存,显著提升性能。
RDD基于lineage实现容错,而不是shared state的update。
简介
背景
原有的并行框架MapReduce无法有效利用内存,并且不能重复利用迭代计算的中间结果,而是将中间结果存储在磁盘上,增加了数据备份(hdfs默认为3份)开销,磁盘IO,序列化的时间,迭代计算在数据挖掘和图算法中很常见,例如k-means,逻辑回归,PageRank。
挑战
RDD设计中的主要挑战是提供高效的“fault tolerance”编程接口,现有的对于内存存储的容错都是细粒度的对于可变状态的update,具体为跨机器的数据备份(replicate data cross machine)或者跨机器的日志更新(log updates cross machine),需要跨机器传输备份数据,效率低。不同的RDD提供基于粗粒度的transformations(例如map,filter等)构建的lineage(血统),如果一个RDD丢失数据,则可根据lineage找出丢失数据的来源,重新计算,达到容错,而不需要数据备份。
RDD(Resilient Distributed Datasets)
Spark数据存储的核心是弹性分布式数据集(RDD)。RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的。逻辑上RDD的每个分区叫一个partition。
在Spark的执行过程中,RDD经历一个个的Transformation算子之后,最后通过Action算子进程触发操作。逻辑上每经历一次变换,就会将RDD装换为一个新的RDD,RDD之间通过Lineage产生关系,这个关系在容错中有很重要的作用。变换的输入和输出都是RDD。RDD会被划分成很多的分区分布到集群的多个节点中。分区是个逻辑概念,变换前后的新旧分区在物理上可能是同一块内存存储。这是很重要的优化,以防止函数式数据不变性(immutable)导致的内存需求无限扩张。有些RDD是计算的中间结果,其分区并不一定有相应的内存或磁盘数据与之对应,如果要迭代使用数据,可以调用cache()函数缓存数据。
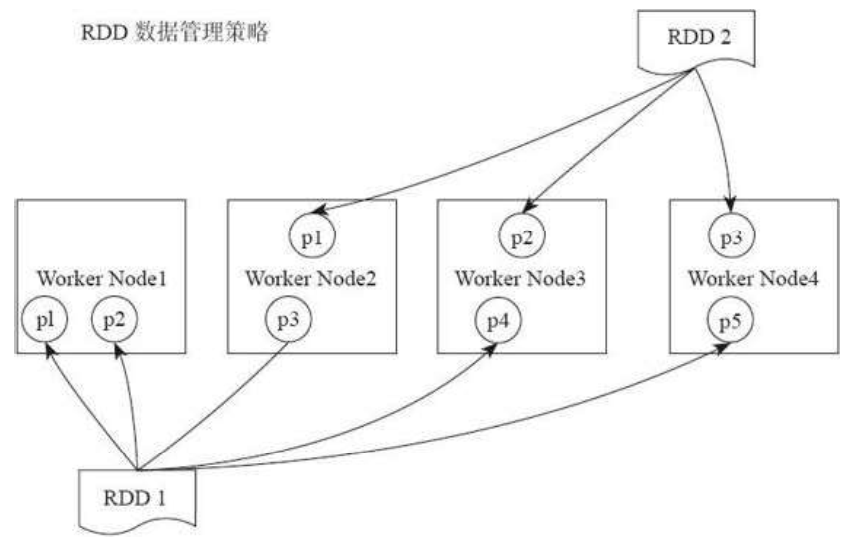
在物理上,RDD对象实质上是一个元数据结构,存储着Block、Node等的映射关系,以及其他的元数据信息。以及其他的元数据信息。一个RDD就是一组分区,在物理数据存储上,RDD的每个分区对应的就是一个Block,Block可以存储在内存,当内存不够时可以存储到磁盘上。
RDD抽象
只读的,分区的数据集(a collection of Java or Python object across a cluster.),通过其他RDD或者数据源(data in stable storage)创建。RDD通过lineage保留自身创建信息,RDD只有在执行action之后才会触发真正的计算。
spark编程接口
spark的实现中,使用对象存储数据,transformation是操作这些对象的方法,RDD可以通过外部数据源或者parallelize操作数组的方式初始化,执行transformation获得新RDD,最后是action操作(例如count,collect,save),spark中RDD的计算是lazy的,此外程序可以使用persist和cache(cache是调用persist(StorageLevel.MEMORY_ONLY))缓存数据达到重复利用。
RDD和shared state对比
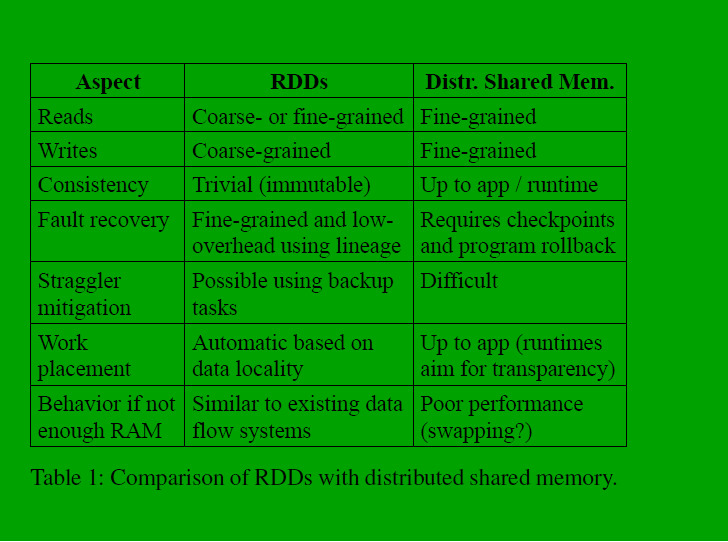
因为RDD是只读的(不可变的)和使用了lineage,一致性和容错都得到了保障,对于stragglers(是指long-running tasks,slow nodes)的策略和MapReduce相似,使用了备份任务,同时执行的方式,此外,跟性能相关性大的一点是计算跟着数据走。
RDD模型优势
1.容错方式:RDD只能通过粗粒度的transformation操作,这确保RDD可以bulk write,不需要通过checkpoing就能实现数据容错,此外,只有丢失数据的partition需要重算,根据lineage。
2.任务备份:通过对运行慢的任务进行备份,提高任务的执行速度。
3.就近执行:计算跟着数据走,提高执行效率。
4.不只是内存:内存不足,数据可以存储在硬盘,并通过压缩的方式获得和内存处理相近的性能。
RDD不是万能的
RDD适合批处理,不适合细粒度的对于shared state的update,如web程序的DB,持续增长的web爬虫数据存储等。
Spark编程接口
RDD相关操作

spark采用scala语言实现,简介,效率不错
RDD组成
组成
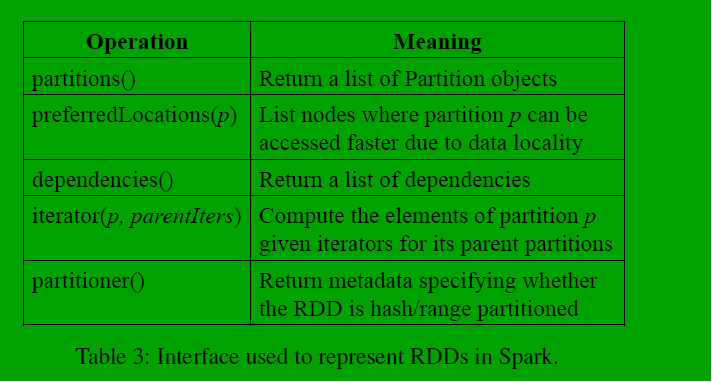
RDD分类
窄依赖:父RDD只被一个子RDD引用
宽依赖:父RDD被不止一个子RDD引用
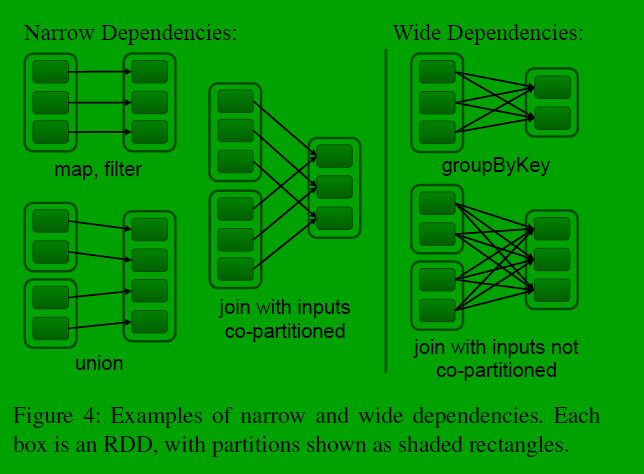
为什么要区分窄依赖和宽依赖
1.窄依赖可以流水线(pipeline)执行,执行效率高,宽依赖需要等所有父RDD执行完再执行下一步计算。
2.窄依赖的恢复更容易且快速,因为只有一个父RDD的partition需要重新计算。
部分RDD的实现
1.hadoopRDD:一个block对应一个partition,preferredLocations方法返回block,然后iterator reads the block。
2.mapRDD:map方法返回mapRDD,保持和父RDD相同的partition和preferredLocations,只是将map方法应用于父RDD的每一条记录。
3.unionRDD:union方法返回,每一个child RDD的partition通过窄依赖计算得来。
4.sampleRDD:和map类似,多了一个随机数生成器,用来获取样本RDD中记录。
5.joinRDD:可能导致两个宽依赖,两个窄依赖,或者各有一个,result RDD拥有的partition schema,可以是默认的hash partitioner,或者从父RDD继承的。
任务调度
stage划分
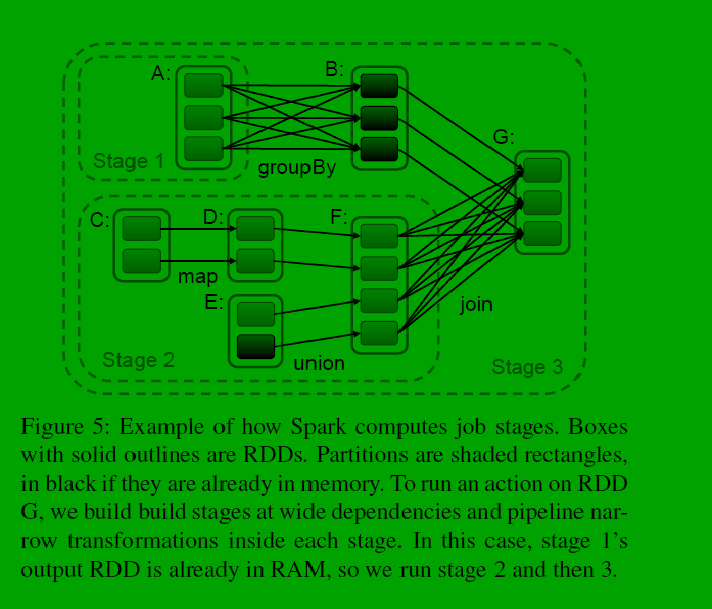
当调用action方法时,spark根据lineage构建DAG生成task。如上图所示,以RDD的partition为最小粒度,划分stage时,从一个RDD开始,尽可能多的包含流水线操作(窄依赖),将其划分为一个stage(如上图stage2),每个stage的边界是shuffle操作(宽依赖)。
对于宽依赖,会保存中间结果便于遇到错误后数据恢复,和MapReduce的map端类似。
任务调度
stage划分完毕后,根据stage生成一系列task,使用delay scheduling算法,根据计算跟着数据走的原则分发task到各节点执行,计算后的结果返回给driver节点的action操作。
内存管理
spark提供三种RDD持久化方案:
1.内存存储序列化的Java对象
2.内存存储其他格式的序列化数据
3.磁盘存储
第一种性能最好,第二种选择合适的序列化和压缩工具能有效利用内存,第三种适合特别大的数据量。为了更有效的使用内存,使用LRU算法,然后,内存不足时,清除的却是最近被使用的RDD的partition,保存old partition在内存,目的是为了防止partition频繁的in and out。因为我们通常操作整个RDD,那么早已在内存中的partition将来被用到的可能性大。目前spark集群的每个实例单独管理自己的memory,未来调研统一内存管理的可行性(unified memory manager)。
支持保存点(checkpoint)
虽然RDD可以通过lineage实现fault recovery,但是这个回复可能是很耗时的,因为提供保存点很有必要,通常保存点在有宽依赖时(shuffle耗时)很有用,相反,窄依赖时则不值得使用。spark提供了API,但何时使用由用户决定,也在调研自动保存点的可行性,RDD的只读属性也使其实现保存点功能比传统的shared state更容易。
总结
RDD是高效的,通用的,容错的,更是spark的基石。














 8528
8528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









