







C++多线程 Lesson 2 笔记:在线程间传递数据
报名了Udacity(优达学城)的 C++ Nanodegree 课程,其中关于C++相关高级内容比如内存管理,多线程是其比较吸引我的地方,也正是自己想要提高的方面。由于这两部分的课程中的文字资料相比视频来说多了很多很多,而且全英文读起来很累,于是打算在这里边学边通过自己的理解记下一些笔记,以便日后查阅,同时与其他有需要的人分享。
这一篇对应于 Lesson 2: Passing data between threads
(C++多线程的部分总共有4个Lessons,有时间会逐步更新后面的内容)
1.1. Promises and Futures
- Promises and Futures 通信访问机制
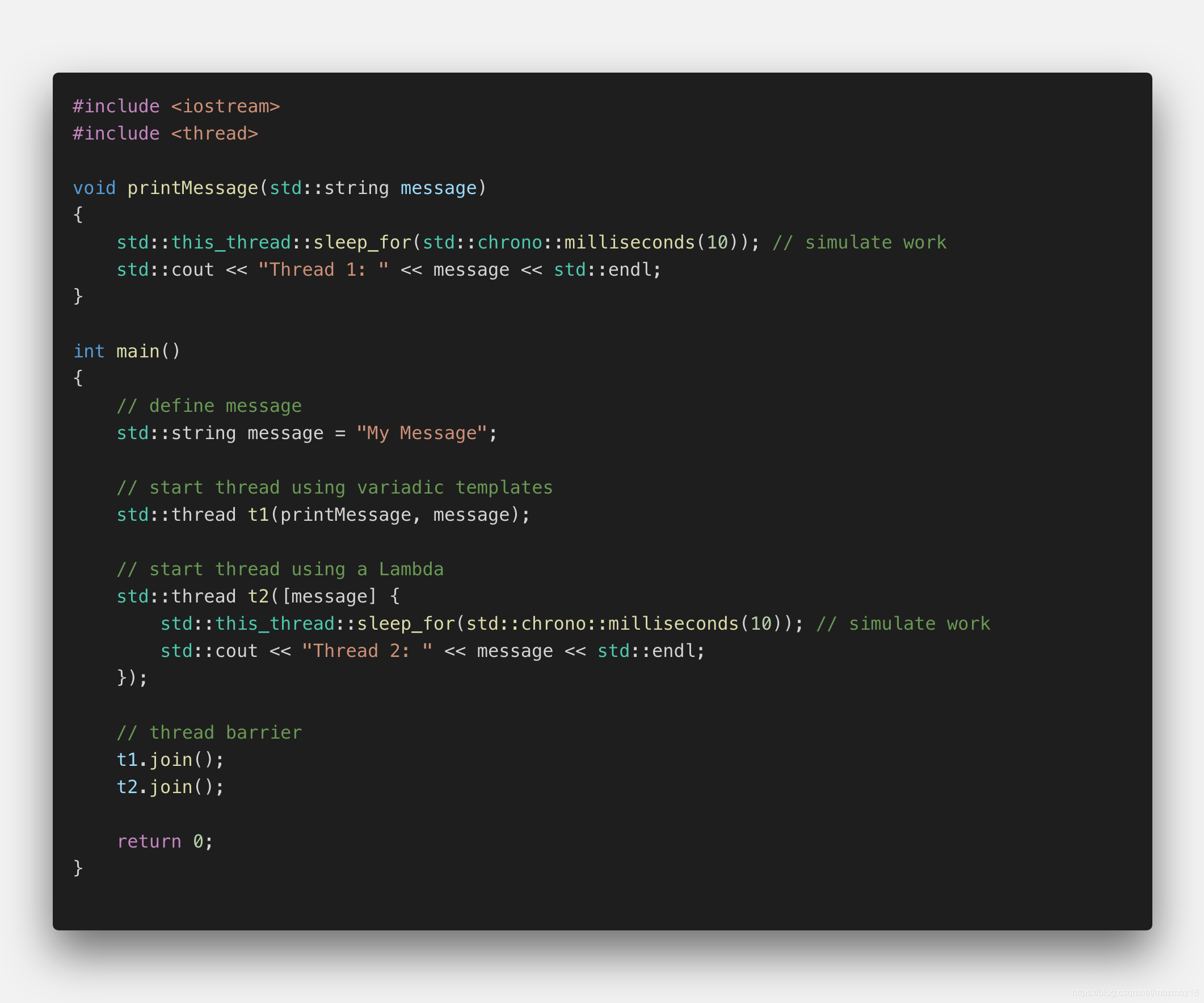
在上一节中,我们介绍了如何向子线程传递数据:这个步骤往往是在对新线程的构造时完成的,比如可以使用可变参数模版,或者使用Lambda表达式。下面的图片回顾了这两种构建线程的方式。
然而,这两种方式存在一个不足,那就是我们只能从主线程main()向子线程t1, t2传递数据,而相反的数据传递方向是行不通的。为了解决这个问题,线程需要遵守一个严格的同步协议。 因此,C++提供了一种通信机制,该机制可以充当线程之间单向的通道(子线程向主线程传递数据)。该通道的发送端称为“Promise”,而通道的接收端称为“Future”。在C++中,类模板std::promise提供了一种方便的方法来存储将在以后通过std::future对象异步地获取的数据(可能是数值或是异常)。另外需要注意,每个std::promise对象只能使用一次。
在下面的示例代码中,我们想声明一个promise对象以便在线程中传递并修改一个string。在定义了消息的string后,我们需要在主函数中定义一个合适的promise对象以便用于传递string类型数据。除此之外,为了获得相应的future对象,我们需要用promise对象调用get_feature()函数。这样,在promise和future对象在主程序中都被建立好之后,string类型的数据就可以被传递。之后,我们就可以创建一个函数,并开启一个子线程来调用这个函数。在向线程函数传递参数的过程中,建立的promise对象和需要被子线程修改的string当然是需要的,另外特别需要注意的是,promise对象需要通过移动语义进行处理,即使用move()函数来得到实参,形参的类型则是相应的右值引用。在线程函数modifyMessage()中,当string被修改之后,还需要promise对象调用函数set_value()以传递回修改后的string。在子线程执行的同时,主线程中,我们用future对象调用函数get()以实时监听是否有从promise对象传递回来的string数据。这里,get()函数会阻断主线程的运行,直到promise对象将消息从子线程发送回来为止(即当promise对象在子线程中调用函数set_value()之后)。当然,也存在主线程运行比较慢的情景,即promise对象很快的就完成调用了set_value()函数,而主线程的future()过了一段时间才执行到get()函数,那么,get()函数在这种情况下就会立刻返回,主线程得以继续执行。另外,当future对象调用过get()函数之后,future对象就不再有效了,因为信息的交换已经完成了。再次调用get()函数会跑出异常。
#include <iostream>
#include <thread>
#include <future>
void modifyMessage(std::promise<std::string>&& prms, std::string message)
{
std::this_thread::sleep_for(std::chrono::milliseconds(4000)); // simulate work
std::string modifiedMessage = message + " has been modified";
// set_value()
prms.set_value(modifiedMessage);
}
int main()
{
// define message
std::string messageToThread = "My Message";
// create promise and future
std::promise<std::string> prms;
std::future<std::string> ftr = prms.get_future();
// start thread and pass promise as argument
std::thread t(modifyMessage, std::move(prms), messageToThread);
// print original message to console
std::cout << "Original message from main(): " << messageToThread << std::endl;
// retrieve modified message via future and print to console
std::string messageFromThread = ftr.get();
std::cout << "Modified message from thread(): " << messageFromThread << std::endl;
// thread barrier
t.join();
return 0;
}
- get()函数与wait()函数的比较
在一些情形下,我们希望分离对消息的等待与对消息的接收,即,我们可以先选择等待一会儿,以确保消息已经发回,再执行消息的接收。针对这种情况,Future恰好提供了wait()函数来满足这个功能:用future对象调用wait()函数可以等待一段时间,一旦返回的数据可以被接收,wait()立即返回,即,我们可以在后面没有延迟的调用之前讲过的get()函数。
在wait()函数之外,C++还提供了wait_for()函数,它既可以通过设定一个值用来等待指定的时间,也可以向get()一样,等待直到返回的数据可以被接收。两种情况下,哪种情况更早,就优先被执行。即,可能出现的情况就是设定的等待时间仍然不够长,数据在等待之后依然还不可接收,这时,我们可以通过查看wait_for()函数的返回值就可以判断是消息否接收成功。相应的内容请参考下面给出的代码。
#include <iostream>
#include <thread>
#include <future>
#include <cmath>
void computeSqrt(std::promise<double>&& prms, double input)
{
std::this_thread::sleep_for(std::chrono::milliseconds(2000)); // simulate work
double output = sqrt(input);
prms.set_value(output);
}
int main()
{
// define input data
double inputData = 42.0;
// create promise and future
std::promise<double> prms;
std::future<double> ftr = prms.get_future();
// start thread and pass promise as argument
std::thread t(computeSqrt, std::move(prms), inputData);
// wait for result to become available
auto status = ftr.wait_for(std::chrono::milliseconds(1000));
if (status == std::future_status::ready) // result is ready
{
std::cout << "Result = " << ftr.get() << std::endl;
}
// timeout has expired or function has not yet been started
else if (status == std::future_status::timeout || status == std::future_status::deferred)
{
std::cout << "Result unavailable" << std::endl;
}
// thread barrier
t.join();
return 0;
}
- 传递一个异常
Promises and Futures 通信访问机制除了在传递值之外,还可以传递异常(exceptions),两者间用到的原理以及调用的函数是类似的。
在下面展示的程序里,promise对象在线程函数中调用set_exception()函数即可设置一个需要被传递的异常。在这个函数中,需要被传递的异常,即子线程程序中产生的异常,可以通过std::current_exception()函数来获得。另外,在主线程端,我们也可以通过future对象调用get()函数来接收消息(这里是接收异常)。这里,我们想在主线程中捕获std::runtime_error,相应的,可以调用what()函数来获得异常的具体信息。
#include <iostream>
#include <thread>
#include <future>
#include <cmath>
#include <memory>
void divideByNumber(std::promise<double>&& prms, double num, double denom)
{
std::this_thread::sleep_for(std::chrono::milliseconds(500)); // simulate work
try
{
if (denom == 0)
throw std::runtime_error("Exception from thread: Division by zero!");
else
prms.set_value(num / denom);
}
catch (...)
{
prms.set_exception(std::current_exception());
}
}
int main()
{
// create promise and future
std::promise<double> prms;
std::future<double> ftr = prms.get_future();
// start thread and pass promise as argument
double num = 42.0, denom = 0.0;
std::thread t(divideByNumber, std::move(prms), num, denom);
// retrieve result within try-catch-block
try
{
double result = ftr.get();
std::cout << "Result = " << result << std::endl;
}
catch (std::runtime_error e)
{
std::cout << e.what() << std::endl;
}
// thread barrier
t.join();
return 0;
}
1.2. Threads和Tasks
- 使用std::async()启动线程
std::async()是相较于std::thread()一种更简单直接的实现子线程的方法,可用于子线程向主线程传递数据的情景。为了比较,我们利用std::async()实现了之前例子中介绍过的相同功能,代码在下方给出。可以观察,在线程函数中,我们不需要再次定义和使用promise对象,也不再需要try-catch的结构。另外,线程函数的返回值不再是void,而是直接向主线程返回一个double类型的数据。甚至,线程函数就和一个普通的函数没有区别,你看不到其中任何关于线程或promise/future的痕迹。在主线程中,我们用std::async()函数代替了std::thread(),由于std::async()函数会返回一个future,我们还需要创建一个future对象来接收返回值(promise对象不再需要)。在主线成中,我们可以用future对象调用get()函数来得到子线程返回的数据,这和之前是相同的。最后一个区别是,在主线程中,我们不需要再次调用join()函数,这是因为std::async()函数创建的子线程可以自动被析构,这也降低了出现Bug的可能性。
#include <iostream>
#include <thread>
#include <future>
#include <cmath>
#include <memory>
double divideByNumber(double num, double denom)
{
std::this_thread::sleep_for(std::chrono::milliseconds(500)); // simulate work
if (denom == 0)
throw std::runtime_error("Exception from thread: Division by zero!");
return num / denom;
}
int main()
{
// use async to start a task
double num = 42.0, denom = 2.0;
std::future<double> ftr = std::async(divideByNumber, num, denom);
// retrieve result within try-catch-block
try
{
double result = ftr.get();
std::cout << "Result = " << result << std::endl;
}
catch (std::runtime_error e)
{
std::cout << e.what() << std::endl;
}
return 0;
}
- std::async()的同步或异步
下面的一段程序与上一段代码基本完全相同,只不过我们想在这里额外打印输出子线程与主线程的线程ID。在程序编译运行后,我们可以从输出清楚地看到,子线程与主线程的ID是不同的,这正说明了他们在程序中被平行地执行。
然而,当我们在std::async()函数中使用了std::launch::deferred关键字后并编译运行程序,又会发现打印出的子线程与主线程的ID是相同的。这是因为,std::launch::deferred可以被理解为延迟调用,系统并没有创建新的子线程,而是同步(synchronous execution)执行。 与之相反的是std::launch::async关键字,它可以强迫系统创建子线程,异步执行(asynchronous execution)。那么,回到最初的情形,我们没有添加任何的关键字(默认的情况),这时,系统会自行选择是否执行带有std::launch::deferred的选项或者是带有std::launch::async的选项。这一点正是std::async()和std::thread()启动子线程的重要区别。
最后,对std::async()做一点总结:与使用std::thread()相比,编译器自动生成了一个promise对象并且直接在返回值中提供了一个与之相应的future对象,因此在代码上相比传统的Promises-Futures的调用要简洁了许多。另外一点,就是编程者可以通过给定关键字std::launch::deferred或std::launch::async来显式地指定程序执行方式。在默认的情况下(即没有显式地提供关键字),系统可以自行选择程序的执行方式,在多线程执行的任务量与总体运行时间上找到一个更优的平衡点(防止线程过载,因为子线程的开启也要消耗运行资源,还需要额外的调度开销。可以说,程序总体运行时间与子线程数量间不是反比关系,还需考虑计算机硬件方面的一些影响因素,比如处理器的架构)。
#include <iostream>
#include <thread>
#include <future>
#include <cmath>
#include <memory>
double divideByNumber(double num, double denom)
{
// print system id of worker thread
std::cout << "Worker thread id = " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(500)); // simulate work
if (denom == 0)
throw std::runtime_error("Exception from thread#: Division by zero!");
return num / denom;
}
int main()
{
// print system id of worker thread
std::cout << "Main thread id = " << std::this_thread::get_id() << std::endl;
// use async to start a task
double num = 42.0, denom = 2.0;
// 1.case: system will decide async or sync
std::future<double> ftr = std::async(divideByNumber, num, denom);
// 2.case: enforce asynchronous execution
//std::future<double> ftr = std::async(std::launch::async, divideByNumber, num, denom);
// 3.case: enforce synchronous execution
//std::future<double> ftr = std::async(std::launch::deferred, divideByNumber, num, denom);
// retrieve result within try-catch-block
try
{
double result = ftr.get();
std::cout << "Result = " << result << std::endl;
}
catch (std::runtime_error e)
{
std::cout << e.what() << std::endl;
}
return 0;
}
- 以Task为基础的并发
在编程的过程中,如何确定最优的线程使用数量是一个难题:它通常取决于系统硬件中处理器的核心数,是否有意义来顺序执行程序或使用多个线程。通过对std::async()的使用(也正是Tasks的使用,可以被翻译为“异步任务”),这个难题会交给计算机来解决。可以说,通过Tasks,编程者可以决定哪些代码本质上“可以”被平行执行,而系统将在程序执行时具体分配哪些代码“实际会”被平行地执行。
在系统的内部,这个特性是通过线程池(展示了所有能供使用的线程,基于系统硬件)以及Work-stealing Queues(Tasks会被动态地分配到不同的处理其中来执行)来实现的。下面的一个图片展示了一个多核的系统,其中Core1中的任务太多产生了堆积,而其它的Cores则是闲置状态。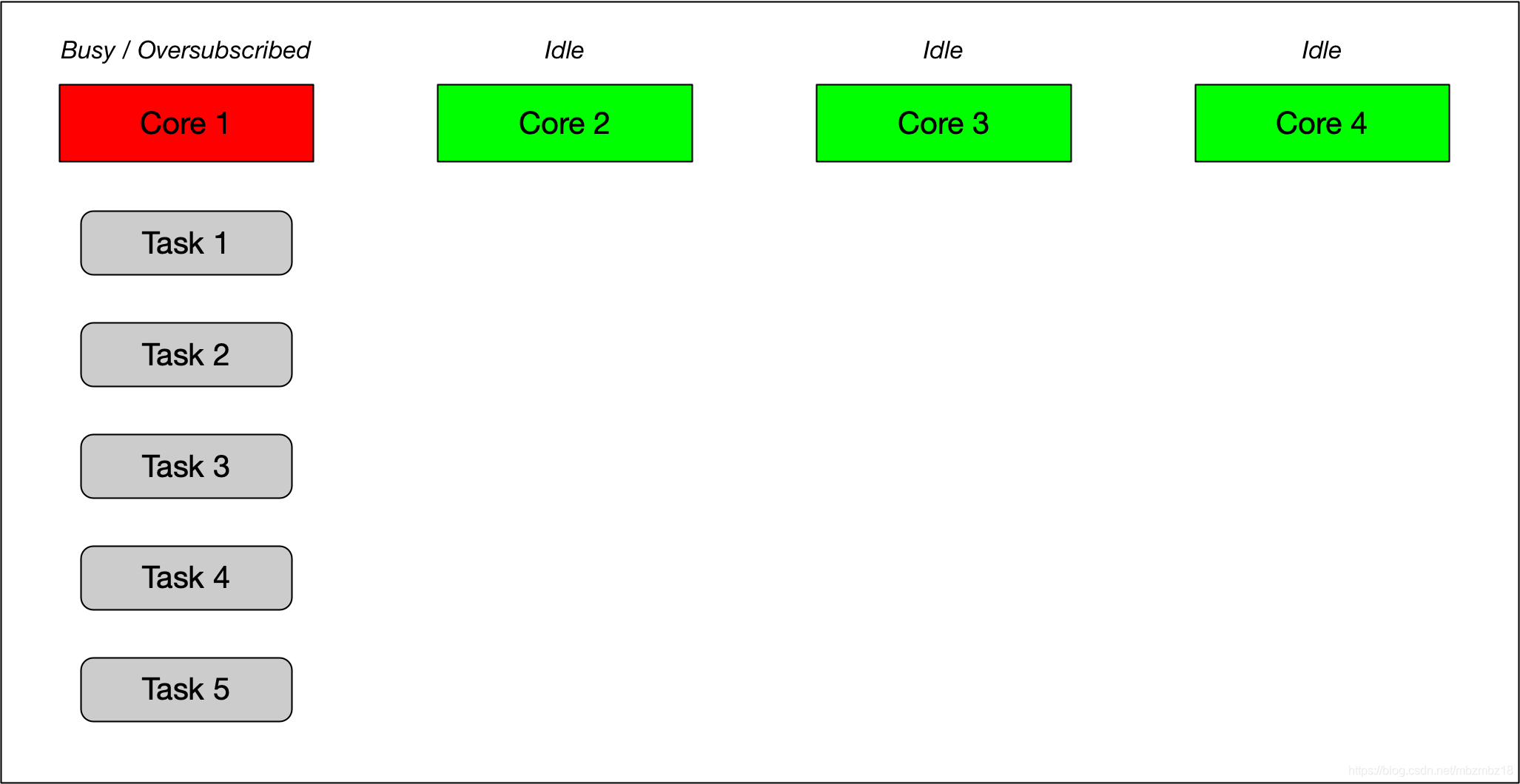
这时,使用Work-stealing Queues技术的想法就是拥有一个系统看门狗一样的程序,在系统的背后一直执行,并且可以时刻监视着系统的运行状态并在适当的时候重新分配每个处理器需要执行的任务。对于上面这张图描述的系统状态来说,Core1中的需要执行的任务会被重新分配(“偷”)到其他的Cores中,以减少这些Cores的闲置时间。在Tasks经过重新分配后,可以得到下面的图: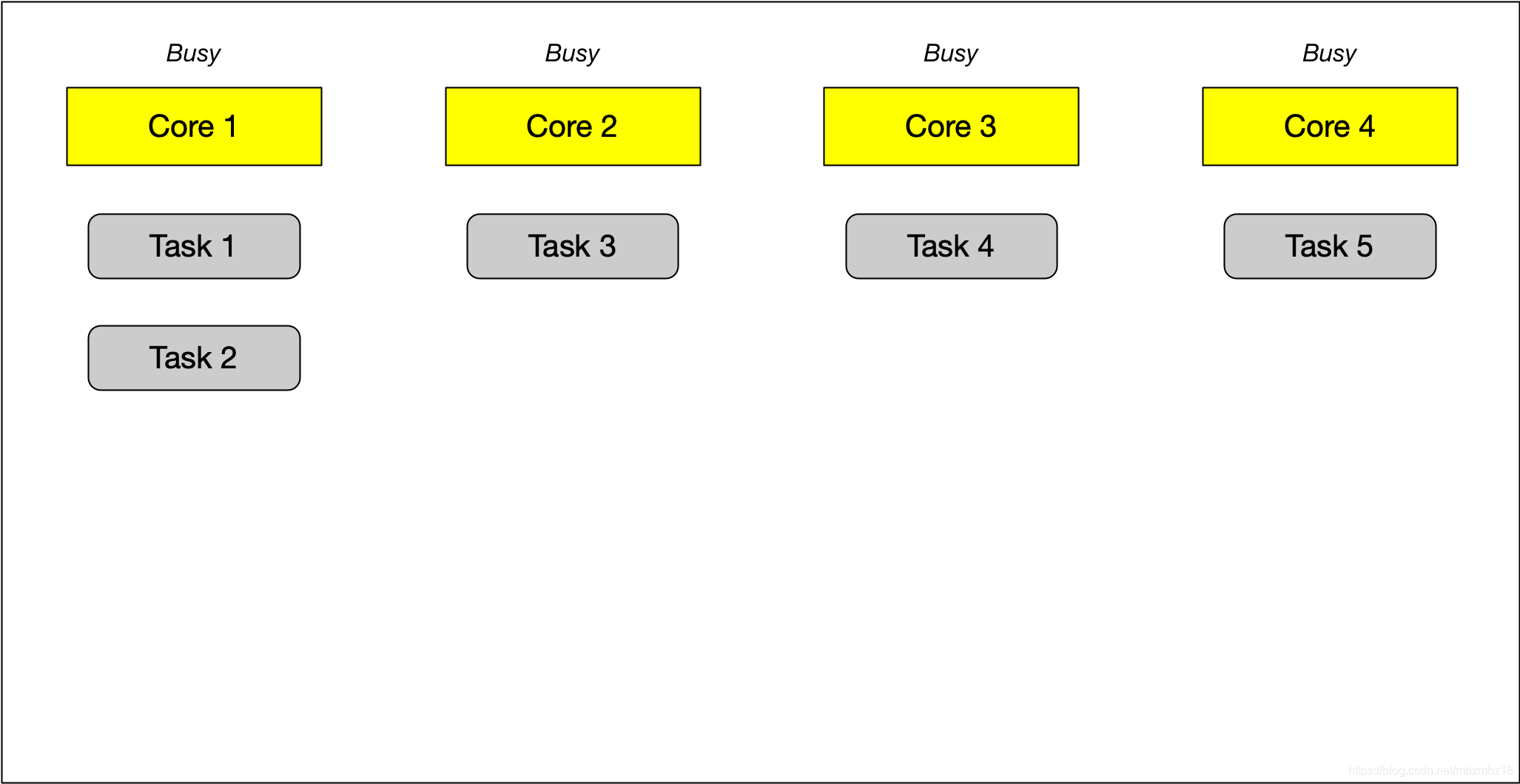
最后,对以Task为基础的编程和以Thread为基础的编程方式进行对比:对于Tasks,系统会自动处理许多程序中的细节(比如join()函数的调用)。对于Threads,编程者需要负责许多细节。对于使用的资源来讲,Threads是一种较大的类型,因为它们是直接由操作系统生成的,调用操作系统并为Threads分配内存/堆栈/内核数据结构需要花费一定的时间。同样,销毁Threads也是较复杂的操作。与此相比,Tasks更加轻量,因为它们会使用已创建的线程池。
Threads和Tasks拥有不同的应用场景。其中,Threads与延迟有关,Threads可以避免程序被阻止,例如服务器正在等待响应。另一方面,Tasks专注于吞吐量,在那里有许多操作并行地被执行。 - 实验:不同的时间开销
下面的一段程序中,可以选择不同的参数(nLoops, nThreads, std::launch::async/std::launch::deferred),来验证不同的程序配置的情况下,对应运算时间的对比。
#include <iostream>
#include <thread>
#include <future>
#include <cmath>
#include <vector>
#include <chrono>
void workerFunction(int n)
{
// print system id of worker thread
std::cout << "Worker thread id = " << std::this_thread::get_id() << std::endl;
// perform work
for (int i = 0; i < n; ++i)
{
sqrt(12345.6789);
}
}
int main()
{
// print system id of worker thread
std::cout << "Main thread id = " << std::this_thread::get_id() << std::endl;
// start time measurement
std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();
// launch various tasks
std::vector<std::future<void>> futures;
int nLoops = 1e7, nThreads = 5;
for (int i = 0; i < nThreads; ++i)
{
futures.emplace_back(std::async(std::launch::async, workerFunction, nLoops));
//futures.emplace_back(std::async(std::launch::deferred, workerFunction, nLoops));
}
// wait for tasks to complete
for (const std::future<void> &ftr : futures)
ftr.wait();
// stop time measurement and print execution time
std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>( t2 - t1 ).count();
std::cout << "Execution finished after " << duration <<" microseconds" << std::endl;
return 0;
}
1.3. 避免数据竞争
- 理解数据竞争
在并发编程中,数据竞争(data races)是错误的主要来源之一。当两个并发线程正在同时访问同一内存位置的数据,并且它们中至少有一个正在修改该数据(另一个线程可能正在读取或修改)时,问题就会发生。在这种情况下,在内存位置中存储的数值完全是未定义的。根据系统的调度程序,第二个线程将在未知的时间点执行,因此每次的执行都可能会在相同的内存位置看到不同的数据。这类的问题称为“数据竞争”,因为两个线程正在争先(racing)访问一个存储位置,而存储于该位置的数据的变动可能要取决于这个竞争的结果。
下面图示的一个例子反映了数据竞争所带来的影响。这里,我们有两个线程,一个想要把变量X的值自增1,而另一个尝试打印输出X的值。取决于程序实际运行中时间和执行顺序,打印输出的X值可能在每次执行程序后都不同。在这个例子中,一个更好更安全的处理方法可能是使用join()函数或Promises-Futures的通讯机制来确保多线程执行时对数据的正确获取。可以说,数据竞争直接不会带来程序的崩溃等大的影响,但注定会带来程序的一些Bug,所以必须要设法避免。
- 向子线程传递数据:按值传递(拷贝)
在下面的第一段代码中,我们有一个Vehicle的类,并通过默认的构造函数和一个有参的构造函数生成了两个对象v0和v1。我们利用Lambda表达式向用std::async()生成的子线程中直接传入了v1,注意这里时值传递,即生成了一份v1的拷贝。在子线程以及主线程中,我们均尝试修改v1的ID(一个线程想改为2,一个线程想改为3),并在最后打印输出v1的ID。程序最后的打印输出v1的ID为3,证明还是以在主线程中的更改为主。这种方式避免了数据的竞争。
然而,对于一些自定义的变量(比如结构体,类)的拷贝,有时可能会有特别的情况要处理。与之对比的下面的第二段代码。在这里,我们向使用了Lambda表达式作为线程函数的子线程中直接传入了已创建的对象v0,这里使用的也是值传递,即生成了一份v0的拷贝。但是不同的是,这次的Vehicle类中我们新增了一个成员属性叫做_name,它的类型是一个指向string的指针。因此,在生成v0的拷贝的过程中,v0的拷贝体的成员属性_name依然指向了v0本身成员属性_name指向的位置。在程序中,由于有了sleep_for()函数延后了子线程的执行,程序最后打印输出的ID结果依旧是2,即在子线程中被更改。如果我们去掉了sleep_for()函数,则数据竞争就会发生,程序最终的打印结果可能在每次执行时都有不同,具体会取决于操作系统Scheduler实时的调度结果。这个例子给了我们一个警示,即需要注意在实际对对象的拷贝过程中到底是发生了深拷贝还是浅拷贝。这里当然深拷贝是需要的,因此有必要去检查自定义类中的拷贝构造函数或是赋值运算符的定义(=operator),即它们有没有适当地被重写,以确保深拷贝的发生。
#include <iostream>
#include <thread>
#include <future>
class Vehicle
{
public:
// default constructor
Vehicle() : _id(0)
{
std::cout << "Vehicle #" << _id << " Default constructor called" << std::endl;
}
// initializing constructor
Vehicle(int id) : _id(id)
{
std::cout << "Vehicle #" << _id << " Initializing constructor called" << std::endl;
}
// setter and getter
void setID(int id) { _id = id; }
int getID() { return _id; }
private:
int _id;
};
int main()
{
// create instances of class Vehicle
Vehicle v0; // default constructor
Vehicle v1(1); // initializing constructor
// read and write name in different threads (which one of the above creates a data race?)
std::future<void> ftr = std::async([](Vehicle v) {
std::this_thread::sleep_for(std::chrono::milliseconds(500)); // simulate work
v.setID(2);
}, v0);
v0.setID(3);
ftr.wait();
std::cout << "Vehicle #" << v0.getID() << std::endl;
return 0;
}
#include <iostream>
#include <thread>
#include <future>
class Vehicle
{
public:
//default constructor
Vehicle() : _id(0), _name(new std::string("Default Name"))
{
std::cout << "Vehicle #" << _id << " Default constructor called" << std::endl;
}
//initializing constructor
Vehicle(int id, std::string name) : _id(id), _name(new std::string(name))
{
std::cout << "Vehicle #" << _id << " Initializing constructor called" << std::endl;
}
// setter and getter
void setID(int id) { _id = id; }
int getID() { return _id; }
void setName(std::string name) { *_name = name; }
std::string getName() { return *_name; }
private:
int _id;
std::string *_name;
};
int main()
{
// create instances of class Vehicle
Vehicle v0; // default constructor
Vehicle v1(1, "Vehicle 1"); // initializing constructor
// launch a thread that modifies the Vehicle name
std::future<void> ftr = std::async([](Vehicle v) {
std::this_thread::sleep_for(std::chrono::milliseconds(500)); // simulate work
v.setName("Vehicle 2");
}, v0);
v0.setName("Vehicle 3");
ftr.wait();
std::cout << v0.getName() << std::endl;
return 0;
}
- 重写拷贝构造函数
上一段示例中我们谈到了深拷贝和浅拷贝的问题。下面的一段程序展示了Vehicle类的一个重写的拷贝函数,它可以确保深拷贝的发生(尤其是对于成员属性_name,被new出来了一份新的空间)。
#include <iostream>
#include <thread>
#include <future>
class Vehicle
{
public:
//default constructor
Vehicle() : _id(0), _name(new std::string("Default Name"))
{
std::cout << "Vehicle #" << _id << " Default constructor called" << std::endl;
}
//initializing constructor
Vehicle(int id, std::string name) : _id(id), _name(new std::string(name))
{
std::cout << "Vehicle #" << _id << " Initializing constructor called" << std::endl;
}
// copy constructor
Vehicle(Vehicle const &src)
{
// QUIZ: Student code STARTS here
_id = src._id;
if (src._name != nullptr)
{
_name = new std::string;
*_name = *src._name;
}
// QUIZ: Student code ENDS here
std::cout << "Vehicle #" << _id << " copy constructor called" << std::endl;
};
// setter and getter
void setID(int id) { _id = id; }
int getID() { return _id; }
void setName(std::string name) { *_name = name; }
std::string getName() { return *_name; }
private:
int _id;
std::string *_name;
};
int main()
{
// create instances of class Vehicle
Vehicle v0; // default constructor
Vehicle v1(1, "Vehicle 1"); // initializing constructor
// launch a thread that modifies the Vehicle name
std::future<void> ftr = std::async([](Vehicle v) {
std::this_thread::sleep_for(std::chrono::milliseconds(500)); // simulate work
v.setName("Vehicle 2");
},v0);
v0.setName("Vehicle 3");
ftr.wait();
std::cout << v0.getName() << std::endl;
return 0;
}
- 向子线程传递数据:使用移动语义
即便自定义拷贝构造函数可以帮助我们避免在一定情况下的数据竞争,但它的开销相对较大。在这里,我们将使用移动语义的方法来实现一种将数据安全地传递到线程的更有效的方式。确切的说,通过移动语义, 可以使右值对象拥有的资源移动到左值中,而无需进行物理意义上的复制。右值引用的特性支持了移动语义的实现,它使得程序员能够编写代码直接将资源(例如动态分配的内存)从一个对象转移到另一个对象中。为了使用移动语义,我们需要自定义一个移动构造函数(系统提供默认的拷贝构造函数,但不提供自定义的移动构造函数)。
移动构造函数可以按照如下的方式定义:(1)首先,创建一个空的构造函数,将函数的参数定义为右值引用的类型。(2)在移动构造函数中,将源对象的相关属性赋值到新建的对象中。(3)将源对象的相关属性重新赋上默认值。
下面的一段代码演示了移动构造函数在子线程中的使用。代码要实现的内容与之前类似,需要注意的是,将v0对象move()后,v0对象就会在移动构造函数中被重新赋上给定的默认值。
#include <iostream>
#include <thread>
#include <future>
class Vehicle
{
public:
//default constructor
Vehicle() : _id(0), _name(new std::string("Default Name"))
{
std::cout << "Vehicle #" << _id << " Default constructor called" << std::endl;
}
//initializing constructor
Vehicle(int id, std::string name) : _id(id), _name(new std::string(name))
{
std::cout << "Vehicle #" << _id << " Initializing constructor called" << std::endl;
}
// copy constructor
Vehicle(Vehicle const &src)
{
//...
std::cout << "Vehicle #" << _id << " copy constructor called" << std::endl;
};
// move constructor
// 1.step: use rvalue reference as input parameter
Vehicle(Vehicle&& src)
{
// 2.step: assign the class data members from the source object
// to the object that is being constructed
_id = src.getID();
_name = new std::string(src.getName());
// 3.step: assign the data members of the source object to default values
src.setID(0);
src.setName("Default Name");
std::cout << "Vehicle #" << _id << " move constructor called" << std::endl;
};
// setter and getter
void setID(int id) { _id = id; }
int getID() { return _id; }
void setName(std::string name) { *_name = name; }
std::string getName() { return *_name; }
private:
int _id;
std::string *_name;
};
int main()
{
// create instances of class Vehicle
Vehicle v0; // default constructor
Vehicle v1(1, "Vehicle 1"); // initializing constructor
// launch a thread that modifies the Vehicle name
std::future<void> ftr = std::async([](Vehicle v) {
v.setName("Vehicle 2");
},std::move(v0));
ftr.wait();
std::cout << v0.getName() << std::endl;
return 0;
}
- 移动语义和唯一性
与上述的拷贝构造函数一样,按值传递通常是安全的,但前提是对要传递的对象内的所有成员数据进行深拷贝。借助移动语义,在默认情况下,我们还可以使用唯一性的概念(notion of uniqueness)来防止潜在的数据竞争。在下面的示例中,我们在Vehicle类中的string属性_name使用了智能指针unique_pointer而不是普通的指针。可以看出,unique_pointer的使用意味着仅允许对其指向的位置进行唯一的引用。因此,当移动构造函数通过使用move()将这个unique_pointer传递给子线程是,会导致主线程中的unique_pointer变为无效。在编译运行程序是,语句v0.getName()处引发异常。这样,编程者可以清楚知道此时不允许访问数据,这正是利用unique_pointer的好处,我们可以防止数据竞争的发生。
这个例子想要说明的重点是,移动语义本身的使用不足以避免数据竞争的发生。线程安全的关键是结合使用移动语义和唯一性。编程者有责任确保指向在线程之间被move的对象的指针是唯一的。
#include <iostream>
#include <thread>
#include <future>
#include <memory>
class Vehicle
{
public:
//default constructor
Vehicle() : _id(0), _name(new std::string("Default Name"))
{
std::cout << "Vehicle #" << _id << " Default constructor called" << std::endl;
}
//initializing constructor
Vehicle(int id, std::string name) : _id(id), _name(new std::string(name))
{
std::cout << "Vehicle #" << _id << " Initializing constructor called" << std::endl;
}
// move constructor with unique pointer
Vehicle(Vehicle&& src) : _name(std::move(src._name))
{
// move id to this
_id = src.getID();
// reset id in source
src.setID(0);
std::cout << "Vehicle #" << _id << " move constructor called" << std::endl;
};
// setter and getter
void setID(int id) { _id = id; }
int getID() { return _id; }
void setName(std::string name) { *_name = name; }
std::string getName() { return *_name; }
private:
int _id;
std::unique_ptr<std::string> _name;
};
int main()
{
// create instances of class Vehicle
Vehicle v0; // default constructor
Vehicle v1(1, "Vehicle 1"); // initializing constructor
// launch a thread that modifies the Vehicle name
std::future<void> ftr = std::async([](Vehicle v) {
v.setName("Vehicle 2");
},std::move(v0));
ftr.wait();
std::cout << v0.getName() << std::endl; // this will now cause an exception
return 0;
}
本篇内容结束。。。















 7627
7627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









