







Map
Map也被称为映射表(关联数组),使得你可以用键来查找对象,键所关联的对象被称为值,因此你可以使用键来找值,用对象来查找对象。Map保存的键不重复,如果有相同的键被加入,那么原来的值将被加入的值覆盖。键必须是唯一的,而值可以有重复。标准的java类库中包含了Map的几种基本实现,包括:HashMap、TreeMap、LinkedHashMap、WeakHashMap、ConcurrentHashMap、IdentityHashMap。它们都有同样的基本接口Map,但是行为特征各不相同,这表现在效率、键值对的保存及呈现次序、对象的保存周期、映射表如何在多线程程序中工作和判断“键”等价的策略等方面。
- HashMap:和HashSet一样,以散列的方式来存储数据,提供了快速查找的能力(它取代了HashTable)。插入和查询“键值对”的开销是固定的。可以通过构造方法的容量和负载因子,以调整容器的性能。
- LinkHashMap: 类似于HashMap,但是迭代遍历它时,取得“键值对”的顺序是其插入顺序,或者是最近最少使用(LRU)的次序。查询时只比HashMap慢一点;而在迭代访问时反而更快,因为它使用了链表维护内部次序。
- TreeMap:基于红黑树的实现。查看“键”或“键值对”时,它们会被排序(次序由Comparable或Comparator决定)。TreeMap的特点在于所得到的结果是经过排序的。TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子数。
- WeakHashMap:弱键(weak key)映射,允许释放映射表所指向的对象;这是为解决某类特殊问题而设计的。如果映射表之外没有引用指向这个”键“,则该”键“可以被垃圾收集器(GC)回收。
- ConcurrentHashMap:一种线程安全的Map,它不涉及同步加锁。
- IdentityHashMap:使用==代替equals(),对“键”进行比较的散列映射。专为解决某类特殊问题而设计的。
带有Hash字段的映射类都是利用散列来存储元素的,如果“键”被用于散列Map,那么它必须还具有恰当的hashCode方法;而TreeMap则是利用树来存储”键“的,该键必须实现Comparable接口。
HashMap如何进行快速查找:
HashMap专门对速度进行了优化,那么HashMap是如何在映射表中快速查找键对象呢,如果使用线性查找(for循环)那执行速度会相当地慢。因此HashMap使用了特殊的值散列码,来取代对键的缓慢搜索。散列码是通过将对象的某些信息进行转换而生成的,散列码是”相对唯一”的,是int类型。通过根类Object中的hashCode()方法就可以获取散列码,所以每个对象都能产生散列码。HashMap就是使用对象的hashCode()进行快速查询,此方法能够显著提高性能。因此散列是映射中存储元素时最常用的方式。 散列的价值在于速度:散列使得查询得以快速进行。
那么键值是如何利用散列进行快速查询的呢?首先我们必须要知道存储一组数据最快的数据结构是数组,我们可以通过数组下标就可以立即得到该数据,所以我可以通过数组来存储键的信息。但是Map中保存键值的数量是不确定的,而数组的容量却是固定的,这不就冲突了吗?其实数组并不是保存键本身。而是通过键对象生成一个数字,将其作为数组的下标。这个数字就是散列码。也是就是我们上面所说的,由hashCode()方法生成()。
每个对象的散列码是”相对唯一”的,如果有1w个对象就差不多有1w个散列码,难道我们就必须创建1w容量的数组?因为hashCode()返回的是int类型的值,所以我只要把散列值除以一个特定数字,结果的余数就是数组的下标,而这个特定数字就是数组容量的大小。 如果把余数当作数组的下标,那么不同的键就就可能产生相同的下标。也就是说,可能产生冲突。因此,数组多大就不重要了,任何键总能在数组中找到它的位置。
于是查询一个值的过程首先就是计算散列码,然后使用散列码查询数组。而数组中的元素并不是存储键对象本身,而是存储是链表,链表中存储的是所有余数相同的键对象。然后根据链表中的键对象使用equal()方法进行线性查询。这部分的查询自然会比较慢,但是,如果散列函数好的话,数组每个位置就只有较少的值。
利用hashCode值快速跳到数组某个位置,然后对该位置的链表进行较少的线性比较,这就是HashMap之所以快的原因,就如下表所示:
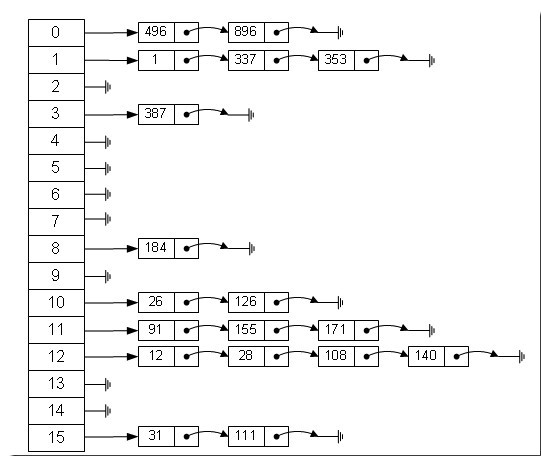
理解了散列的原理,我们就能够实现一个简单的散列Map了:
/**
* 简单的Map容器,继承AbstractMap省去我们重写很多通用的方法
*
*/
public class SimpleHashMap<K, V> extends AbstractMap<K, V> {
/**
* 实现Map.Entry接口,用于存储键值对的节点
*/
class Node<K, V> implements Map.Entry<K, V> {
private K key;
private V value;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return value;
}
@Override
public V setValue(V v) {
V result = v;
value = v;
return result;
}
@Override
public int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
/**
* 只有键和值一样才相等
*/
@Override
public boolean equals(Object obj) {
if (obj == this)
return true;
if (obj instanceof Map.Entry) {
Map.Entry<K, V> e = (Map.Entry<K, V>) obj;
//key和value都相等才返回true
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
@Override
public String toString() {
return key + "=" + value;
}
}
/**
* 使用2的次方作为哈希数组的大小
*/
static final int SIZE = 512;
/**
* 声明了一个LinkedList类型的数组,LinkedList存放的是Node类型的键值对元素
*/
LinkedList<Node<K, V>>[] buckets = new LinkedList[SIZE];
/**
* 继承Map接口,需要实现entrySet方法,用于返回所有的键值对集合。
*/
@Override
public Set<Entry<K, V>> entrySet() {
Set<Map.Entry<K, V>> set = new HashSet<Map.Entry<K, V>>();
for (LinkedList<Node<K, V>> bucket : buckets) {
if (bucket == null) continue;
for (Node<K, V> mpair : bucket) {
set.add(mpair);
}
}
return set;
}
/**
* 把键值对存入Map中
*/
@Override
public V put(K key, V value) {
V oldValue = null;
//用key的hashCode余数作为数组的下标
int index = Math.abs(key.hashCode()) % SIZE;
if (buckets[index] == null) {
buckets[index] = new LinkedList<Node<K, V>>();
}
//获取数组中LinkedList对象
LinkedList<Node<K, V>> bucket = buckets[index];
//创建键值对节点,存放键值对对象
Node<K, V> pair = new Node<K, V>(key, value);
boolean found = false;
ListIterator<Node<K, V>> it = bucket.listIterator();
//遍历LinkedList中是否有相等的key
while (it.hasNext()) {
Node<K, V> iPair = it.next();
if (iPair.getKey().equals(key)) {
//有相等的key
//取出老value用于返回
oldValue = iPair.getValue();
//取代原来的键值对对象
it.set(pair);
found = true;
break;
}
}
//如果LinkedList中没有key于之相等,则把新的键值对对象加入。
if (!found) {
buckets[index].add(pair);
}
return oldValue;
}
/**
* 根据key获取value
*/
public V get(Object key) {
//用key的hashCode余数作为数组的下标
int index = Math.abs(key.hashCode()) % SIZE;
if (buckets[index] == null) return null;
//返回和key相等的value对象
for (Node<K, V> iPair : buckets[index]) {
if (iPair.getKey().equals(key)) {
return iPair.getValue();
}
}
return null;
}
public static void main(String[] args) {
SimpleHashMap<String, String> m = new SimpleHashMap<>();
m.put("A", "C");
m.put("B", "C++");
m.put("C", "Java");
m.put("D", "C#");
m.put("E", "Go");
m.put("E", "Swift");
System.out.println(m);
System.out.println("-----------------");
System.out.println(m.get("A"));
System.out.println("-----------------");
System.out.println(m.entrySet());
}
/*Output:
{B=C++, A=C, C=Java, D=C#, E=Swift}
-----------------
C
-----------------
[B=C++, A=C, C=Java, D=C#, E=Swift]
*/
}散列表中数组的每个元素我们称为”槽位”(slot) 也称为“桶位”(bucket),所以我们将表示实际散列表中的数组命令为bucket。桶的数量通常为2的整数次方。对现代处理器来说,除法与求余是最慢的操作。使用2的整数次方长度的散列表,可用掩码代替除法。因为get()是使用最多的操作,求余数的%操作是其开销最大的部分,而使用2的整数次方可以消除此开销。
get()和put()方法都用相同的方式计算在buckets数组中的索引,如果此位置有LinkedList存在,就对其查询。注意上面例子的实现并不意味着对性能进行了调优;它只是想要展示散列映射表执行的各种操作。你可以通过浏览HashMap的代码,看到一个调优过程的实现。比如我们可以修改Node使其成为一种自包含的单向链表(每个Node都有指向下一个的Node的引用),从而不用对每个桶位都使用LinkedList。
下面是用自定义的单向链表代替LinkedList:
public class SimpleHashMap<K, V> extends AbstractMap<K, V> {
/**
* 用于存储键值对的节点
*/
class Node<K, V> implements Map.Entry<K, V> {
private K key;
private V value;
Node<K, V> next;//用于指向下一个节点
public Node(K key, V value, Node<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return value;
}
@Override
public V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
@Override
public int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
/**
* 只有键和值一样才相等
*/
@Override
public boolean equals(Object obj) {
if (obj == this)
return true;
if (obj instanceof Map.Entry) {
Map.Entry<K, V> e = (Map.Entry<K, V>) obj;
//key和value都相等才返回true
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
@Override
public String toString() {
return key + "=" + value;
}
}
/**
* 使用2的整数次方作为数组的大小
*/
static final int SIZE = 512;
/**
* 声明了一个Node节点的数组
*/
Node<K, V>[] buckets = new Node[SIZE];
/**
* 继承Map接口,需要实现entrySet方法,用于返回所有的键值对集合。
*/
@Override
public Set<Entry<K, V>> entrySet() {
Set<Map.Entry<K, V>> set = new HashSet<Map.Entry<K, V>>();
for (Node bucket : buckets) {
for (Node<K, V> e = bucket; e != null; e = e.next) {
set.add(e);
}
}
return set;
}
/**
* 把键值对存入Map中
*/
@Override
public V put(K key, V value) {
//用key的hashCode余数作为数组的下标
int index = Math.abs(key.hashCode()) % SIZE;
for (Node<K, V> e = buckets[index]; e != null; e = e.next) {
//桶内有Node节点,并且key值相等则进行替换
if (key.equals(e.key)) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
//如果桶内没有Node节点 或 桶内有Node节点但是key值都不匹配
//那么就创建一个新的Node节点,并插入链表的头部
buckets[index] = new Node<K, V>(key, value, buckets[index]);
return null;
}
/**
* 根据key获取value
*/
public V get(Object key) {
//用key的hashCode余数作为数组的下标
int index = Math.abs(key.hashCode()) % SIZE;
for (Node<K, V> e = buckets[index]; e != null; e = e.next) {
K eKey = e.key;
if (key.equals(eKey)) {
return e.value;
}
}
return null;
}
public static void main(String[] args) {
SimpleHashMap<String, String> m = new SimpleHashMap<>();
m.put("A", "C");
m.put("B", "C++");
m.put("C", "Java");
m.put("D", "C#");
m.put("E", "Go");
m.put("E", "Swift");
System.out.println(m);
System.out.println("-----------------");
System.out.println(m.get("A"));
System.out.println("-----------------");
System.out.println(m.entrySet());
}
/*Output:
{B=C++, A=C, C=Java, D=C#, E=Swift}
-----------------
C
-----------------
[B=C++, A=C, C=Java, D=C#, E=Swift]
*/
}如何设计hashCode?
在明白了如何散列之后,如何编写自己的hashCode()就有十分重要的意义。设计hashCode()时最重要的因数是:如何何时,对同一个对象调用hashCode()都应该生成同样的值。如果在将一个对象用put()添加进去HashMap时产生一个hashCode()值,而用get()取出时却产生了另一个hashCode()值,那就就无法重现取得该对象了。所以,如何你的hashCode()方法依赖于对象中易变的数据,就要当心了,因为此数据发送变化时,hashCode()就会产生一个不同的散列码,相当于产生了一个不同的键。
此外,也不应该使用hashCode()依赖于具有唯一性的对象信息,尤其是使用this的值,因为这样做无法生存一个新的键,使之与put()中原始的键值对中的键相同。默认Object的hashCode()的值映射的就是对象的地址。所以我们应该使用对象内有意义的识别信息。
以String为例,String有个特点只要字符串一样,那么不管多少个String对象,它们的hashCode的值都是一样的:
String s1=new String("Hello");
String s2=new String("Hello");
String s3=new String("Hello");
System.out.println(s1.hashCode()+" "+s2.hashCode()+" "+s3.hashCode());输出的结果都为69609650,很明显String的hashCode的值是基于String内容的,下面是String类重写hashCode()的代码:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}我们可以看出String的hashCode值就是基于每个字符产生的。
因此,想要使hashCode()实用,它必须速度快,并且必须有意义。也就是说,它必须基于对象的内容生成散列码。散列码不必是对一无二的(应该更关注生成速度,而不是唯一性),但是通过hashCode()和equals(),必须能够完全确定对象的身份。散列码的生成范围并不重要,只要int即可。好的hashCode()应该产生分布均匀的散列码。如果散列码都集中在一块,那么HashMap或者HashSet在某些区域的负载会很重,这样就不如分布均匀的散列函数快。
在Effective Java Programming Language Guide这本书中,为怎样一份像样的hashCode()给出了基本的指导:
- 给int变量result赋予某个非零常量值,例如17
为对象内每个有意义的域f(即每个可以做equals()操作的域)计算出一个int散列吗hashCode:
如果是数组类型则对每个元素应用上述规则- 合并计算得到散列码
result=37*result+hashCode; - 返回result。
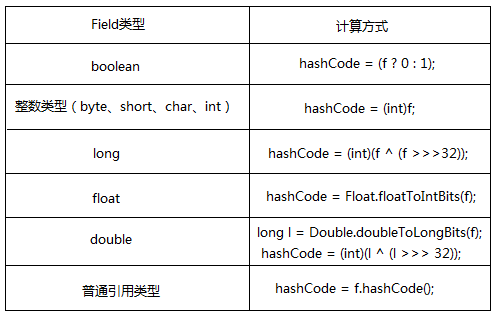
下面便是遵循这些指导的一个例子:
public class Animal {
private String name;
private int age;
private char gender;
public Animal(String name, int age, char gender) {
this.name = name;
this.age = age;
this.gender = gender;
}
@Override
public String toString() {
return "Animal{" +
"name='" + name + '\'' +
", age=" + age +
", gender=" + gender +
", hashCode=" + hashCode() +
'}'+"\n";
}
@Override
public int hashCode() {
int result = 17;
result = 37 * result + name.hashCode();
result = 37 * result + age;
result = 37 * result + (int) gender;
return result;
}
@Override
public boolean equals(Object o) {
if (!(o instanceof Animal)) return false;
Animal animal = (Animal) o;
if (age != animal.age) return false;
if (gender != animal.gender) return false;
return name.equals(animal.name);
}
public static void main(String[] args) {
Map<Animal, Integer> map = new HashMap<Animal, Integer>();
for (int i = 0; i < 5; i++) {
Animal animal = new Animal("Jack", i, '男');
map.put(animal, i);
}
System.out.println(map);
}
/*Output:
{Animal{name='Jack', age=4, gender=男, hashCode=-1144106977}
=4, Animal{name='Jack', age=3, gender=男, hashCode=-1144107014}
=3, Animal{name='Jack', age=0, gender=男, hashCode=-1144107125}
=0, Animal{name='Jack', age=2, gender=男, hashCode=-1144107051}
=2, Animal{name='Jack', age=1, gender=男, hashCode=-1144107088}
=1}
*/
}上面的例子中hashCode和equals()都基于Animal中三个字段来生成结果的,只要发们其中一个发生改变,就会产生不同的结果。
HashMap的性能因子
我们可以通过手工调整HashMap来提高性能,从而满足我们特点应用的需求。为了调整HashMap时让你理解性能问题,需求了解以下的术语:
- 容量:表中的桶的数量(数组的长度)
- 初始容量:表在创建时所拥有的的桶位数。HashMap和HashSet创建时都可以指定初始容量。
- 尺寸:表中当前存储的元素数量。
- 负载因子:尺寸/容量。
空表的负载因子是0,而半满表的负载因子是0.5以此类推。负载轻(负载因子小)的表产生冲突的可能性小,因此对于插入和查找都是最理想的(但是会减慢使用迭代器进行遍历的过程)。HashMap和HashSet都具有指定负载因子的构造器:
public HashMap(int capacity, float loadFactor) {
this(capacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new IllegalArgumentException("Load factor: " + loadFactor);
}
/*
* Note that this implementation ignores loadFactor; it always uses
* a load factor of 3/4. This simplifies the code and generally
* improves performance.
*/
}表示当负载情况达到该负载因子的水平时,容器将自动增加其容量(桶位数),HashMap中的实现方式是使容量(数组大小)变成之前的2倍,并重新将现有的对象分布到新的桶位中(这被称为再散列)。
HashMap使用默认的负载因子是0.75,只有当表达到四分之三满时,才进行散列:
static final float DEFAULT_LOAD_FACTOR = .75F;这个因子在时间和空间代价之间达到了平衡。更高的负载因子可以降低表(数组)所需的空间,但是会增加查找代价,而查找操作是我们用得最多的操作(包括put()和put())。而更低的负载因子就会提高表(数组)所需的空间,造成空间浪费,迭代速度变慢。所以负载因子应该设置成合理的值。
参考
《Thinking in Java》















 493
493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









