







关于使用requests爬取酷狗hot500的案例
1. 案例环境:
python版本:python3.x;
IDE:anaconda-spider;(已安装好需要的requests,bs4库等)
数据库:mysql.5.7
工具包:pymsql(安装将补充)、requests,beautifulsoup
2. 思路分析:
2.1 确定待爬取的url:
http://www.kugou.com/yy/rank/home/1-8888.html?from=homepage
说明:其页数的变化是修改1-8888中的1,即第n页为n-8888
使用火狐浏览器查看网页的代码:ctrl+shift+i,先点击如图红框中按钮,再在网页上点击需要查看内容就会定位到对应的代码,如图1:

图1
2.2 确定爬取的数据
确定爬取的歌曲排名的标签class类名:pc_temp_songnum,如图2:
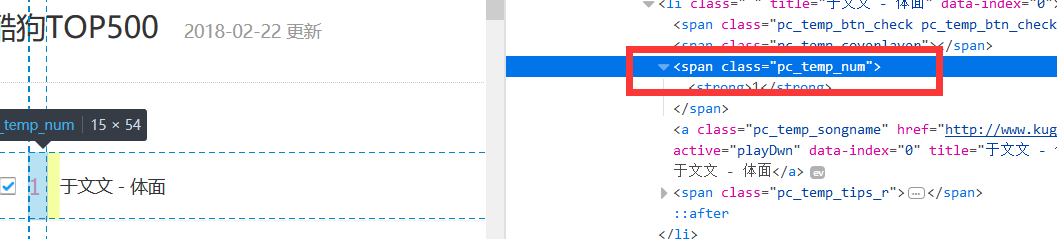
图2
确定爬取的歌曲名称和歌手的标签class类名:pc_temp_songname,如图3:

图3
确定爬取的歌曲时间的标签class类名:pc_temp_time;如图4:
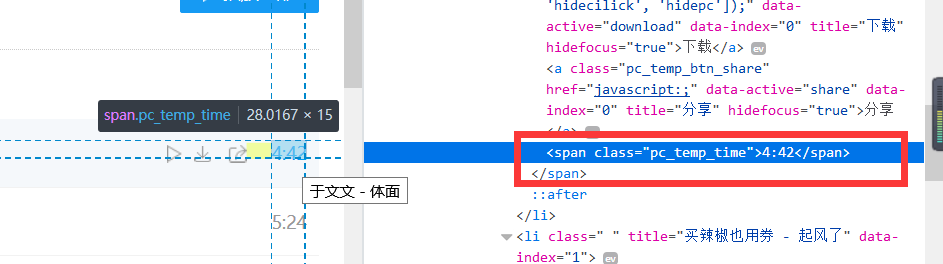
图4
3. 代码分析:
# -*- coding: utf-8 -*-
"""
Created on Sat Feb 24 21:00:31 2018
@author: piqia
"""
# 导入时间模块 可以调用sleep方法,避免频繁地爬去信息而被屏蔽
import time
#使用requests库获取爬取的页面
import requests
#从bs4中导入BeautifulSoup,用于解析html页面
from bs4 import BeautifulSoup
#这是使用mysql数据库,将爬取的数据写到mysql数据中
import pymysql
#初始化连接对象、执行对象
connection=None
cursor=None
#设置访问的头,伪装浏览器,注释1
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/58.0'
}
#爬取的函数,获取酷狗音乐TOP500的信息,参数为一个连接地址,一个数据操作对象
def get_info(url,mysqlHelper):
#使用requests获取,并设置headers参数
wb_data=requests.get(url, params=headers)
#对爬取到的数据使用text获取,进行解析
soup = BeautifulSoup(wb_data.text, 'lxml')
# 获取排名
ranks = soup.select('.pc_temp_num')
# 获取歌名和歌手
titles = soup.select('.pc_temp_songname')
# 歌曲时长list
song_times = soup.select('.pc_temp_time')
#排名,歌名。歌手,时间都是一一对应的列表格式,用for循环进行遍历,写入data字典中,可写入mongodb,也可写到mysql,这是写到mysql中
for rank,title,song_time in zip(ranks,titles,song_times):
data={
'rank': rank.get_text().strip(), #获取标签的中的内容,并把附近的空格、换行删除
'singer':title.get_text().split('-')[0].strip(), #将字符串切割出一个列表获取第一个
'song':title.get_text().split('-')[1].strip(), #将字符串切割出一个列表获取第二个
'time':song_time.get_text().strip() #获取时间值
}
#根据获取的数据,写出插入数据
sql='''insert into songs values("{0}","{1}","{2}","{3}")'''.format(data['rank'],data['singer'],data['song'],data['time'])
#打印验证
print(sql)
print("-"*20)
#调用对象这的方法写入方法
mysqlHelper.insert(sql)
#创建一个数据库操作对象
class mysqlHelper():
#初始化,类似于java中的数据的定义
def __init__(self):
self.connection=None
self.cursor=None
#关闭数据方法
def close(self):
if self.cursor:
self.cursor.close()
if self.connection:
self.connection.close()
#操作mysql语句
def insert(self,sql):
#使用try except,处理异常
try:
#使出pymysql获取mysql数据库连接
self.connection=pymysql.connect(host='localhost',user='root',passwd='root',db='myproject',charset='utf8')
#获取数据操作对象
self.cursor=self.connection.cursor()
#执行sql语句
self.cursor.execute(sql)
#事务提交
self.connection.commit()
except Exception as ex:
#异常数据回滚,不进行mysql数据的执行
self.connection.rollback()
#打印异常信息
print(ex)
finally:
#关闭资源
self.close()
#如果直接使用本文件就执行
if __name__=='__main__':
#初始化数据库
sql0="DROP TABLE IF EXISTS `songs`"
sql1 = "CREATE TABLE `songs` (`rank` varchar(5),`songer` varchar(100),`song` varchar(50),`time` varchar(10))ENGINE=InnoDB DEFAULT CHARSET=utf8;"
#创建对象
mysqlHelper=mysqlHelper()
#清空数据库中songs的表格
mysqlHelper.insert(sql0)
#创建表格,经过测试,不可以同时执行这两条语句
mysqlHelper.insert(sql1)
#生成要遍历成的url,使用列表生成器的方式
urls=['http://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(str(i)) for i in range(1,24)]
for url in urls:
#调用get_info方法进行爬取
get_info(url,mysqlHelper)
#推迟1s
time.sleep(1)
4. 执行结果
如图5为spider执行结果片段,图6是将爬取的数据写到数据的结果。

图5
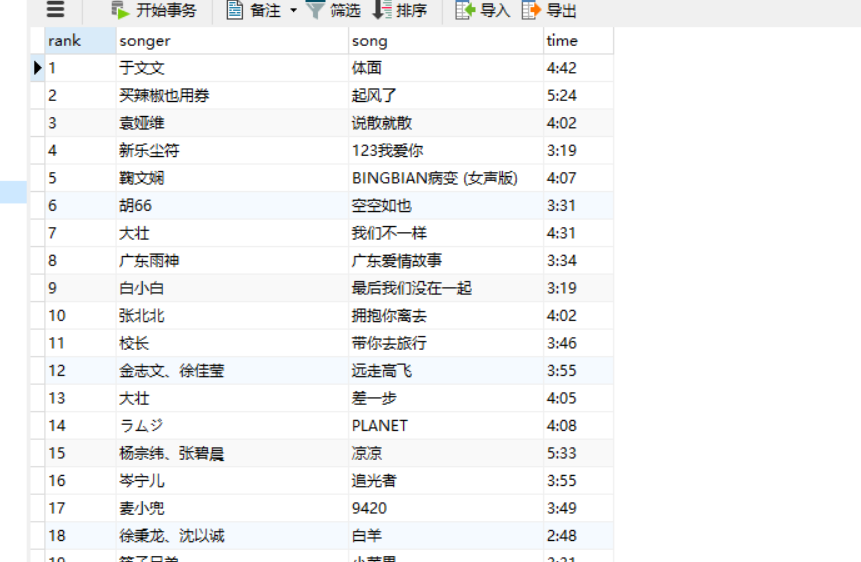
图6
5. 补充
5.1 Headers的获取
打开火狐-->crtl+shift+i-->网络(图7)-->消息头(图8)即可找到。

图7
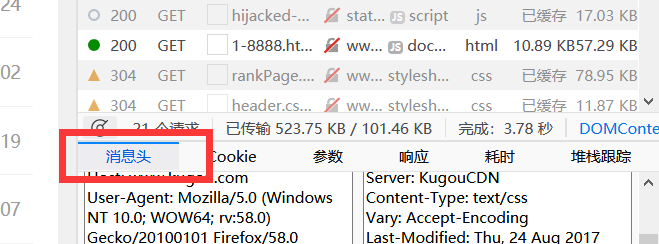
图8
5.2 注意
由于歌曲名,歌手长度不定在创建数据库的时候要考虑各个列的长度。
5.3 pymysql工具包的安装
方式比较多,这里我使用anaconda中便捷的安装方式:打开anaconda --> envirments(图9)选择All-->搜索pymysql(图10)安装即可。
图9
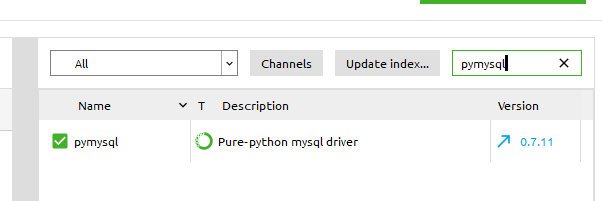
图10















 8457
8457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











