







openSMILE简介
openSMILE(open Speech and Music Interpretation by Large Space Extraction)是一个用于信号处理和机器学习的特征提取器,它具有高度模块化和灵活性等特点。
openSMILE最基础的功能可用于语音信号特征的提取,当然,它还可以分析其他形态的信号,如视觉信号,医学生理信号等等。
openSMILE使用C++编写的,具有高速、高效的特点,拥有灵活的体系结构,并且可以在各大主流操作系统上运行,例如Linux, Windows, and MacOS。OpenSMILE的设计初衷是用于实时的在线处理,然而它也可用于离线处理大批量数据集,这种特性是其他相关软件不具有的,其他大部分相关软件都只是支持离线功能的数据处理。
openSMILE可通过PortAudio进行语音的实时输入和回放。为了增强互用性,它支持用于数据挖掘领域和机器学习领域的各种读写类型文件,例如PCM WAVE、CSV、HTK。由于openSMILE高度模块化的特性,还具有可视化功能。
下图为SMILE结构简图
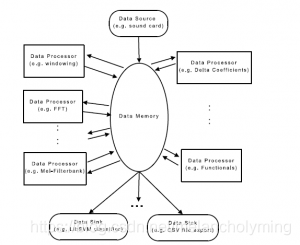
其中,Data Memory是它的核心组件,用于存储数据。Data Source组件可输入数据至Data Memory;Data Processor从Data Memory中读取数据处理完后再次写入Data Memory。最后,Data Sink组件从Data Memory读取数据并且提供给分类器或者将数据写入文件中。














 4286
4286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









