






2021SC@SDUSC
山大软工实践hive(12)-逻辑优化过程中的六种基础接口的作用与关系的梳理
文章目录
目的
这一次梳理一下各大接口之间的关系,正好它们都在 package org.apache.hadoop.hive.ql.lib;

共六种,当然实际结构的交互不止这些接口
Node

它是DAG算子结构的基础,关系是算子继承Operator,Operator实现Node
它要求实现两个方法以达到:能够遍历出DAG的结构,以及识别每个Node是什么种类
它是数据结构的骨架
它的注释上,更倾向于描述它在逻辑优化上的用处:它需要实现的方法让Dispatcher和Walker调用
另外,在了解过程中,有一个不像算子的东西继承了Node,它是ExprNodeDesc,在优化器里表现为predicate的类型,可以认为是一种储存语句信息的类型

关于它在类机构上的位置,比如FIL算子类上,FilterDesc里就会储存ExprNodeDesc类型的变量

另外这些Desc有统一的接口

所以这一部分可以认为是,不同的算子实现不同的Operator,Operator的不同之处体现于它的泛型,这些Desc会储存ExprNodeDesc的变量,它关于着算子对应的语句(比如where id=3)
Rule

它被用于dispatch过程
它必须要实现两个方法,cost用于计算开销,getName没什么用,或许能被用于Debug
实现这接口的类很少
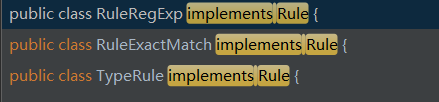
而我接触过的优化器用的都是RuleRegExp

而RuleRegExp是优化器transform方法里很早就会用到的类型,它的规则明显地区分了各优化器
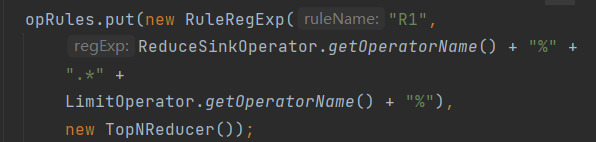
关于它的规则长啥样:
- 输入Name如R1对应它的名字,也是getName()返回的东西
- 输入正则表达式一样的规则如“FIL%”,“TS%.*RS%”来匹配不同的算子结构,只有DAG,准确的说是,dispatch时传入的栈中有能匹配上的结构,其中%只是每个算子后必加的符号,除了分割算子没有其他意义
- cost方法算的是匹配的字符串长度,而不是算子链长度,所以怀疑算子名字的长度本身带有开销的意味
下面是找到的带有正则的规则
GraphWalker

添加完规则后,会先声明Dispatcher,但下一步运行的是Walker的方法
接口方法只有startWalking:用于启动对DAG的walk
但是实际上,所有Walker都继承DefaultGraphWalker,更多的实现在这个类里

它有默认的一系列方法:
- 初始化:传入的参数有Dispatcher,它需要保存这个,才能在walk到一个正确的点后进行dispatch;然后初始化自己的栈和队列,栈是储存walk过程中的路径,并且传入Dispatcher,队列记录了被dispatch节点的先后顺序。另外还有retMap,用于储存各个节点的dispatch后的信息
- startWalking:启动walk,从传入的头节点集合一个一个拿出来启动walk。。。
- walk:怎样对DAG上的节点dispatch,默认的方法是所有子节点先被dispatch,栈存的是从头结点到这个字节点的一条路径;其他的Walker可能会有不同的策略如优先父节点,并且栈存的节点的次序也可能不同。这个方法是最有可能改动的
- dispatch与dispatchAndReturn:总之就是开始调用dispatcher的方法了
- 其他:略
Dispatcher

需要实现dispatch方法:它用于判断一个算子能不能被优化,如何被优化
用DefaultRuleDispatcher举例

它的流程是:
对一个算子,找到它匹配的所有规则(Rule)里的cost最小规则,如果不存在,则用默认的NodeProcessor(优化器输入),反之则用规则对应的优化器(储存在一个map里),对node进行process
另外,翻了一些其他的Dispatcher,他们的dispatch方法很不相同
NodeProcessor

process:用于执行的算子的逻辑优化,也是逻辑优化过程中对语句产生真正的修改的地方
关于怎么使用,会在开始时记录一个 map<Rule,Processor>,每种Rule对应一种Processor,并且在后面初始化dispatcher时还会传入一个默认的Processor
这个类的实现很多,各种内部类,各种单独的子方法,甚至有的会在方法里又进行一次walk,再起进行一遍优化流程
目前我看的两个优化器里,相同的地方是:都会从算子拿出旧的predicate,然后对其修改(也可能不改),然后新的predicate放回去,并记录在retMap里
下面是一个processor的实现,它是PointLookUpOptimizer的内部类,可以看见它对predicate的修改

这个processor的子方法,它又walk了,并且规则对应另一个processor

另一个processor,也是这个类的内部类,很长,是真正对语句修改的地方

NodeProcessorCtx

这个是在找lib包时才发现的,之前对这个没有印象,甚至可能完全没见过
另外,这上面有一大堆注释,不过是和什么许可证有关
感觉也是个存各种信息、变量的地方,之前看优化器有查到过一个相关的类,注释是处理常量传播时的上下文
但凡包含Context(ctx)的类,我认为是存的与某流程相关的环境:各种变量,boolean,阈值,等等
总结
这一次梳理了各个接口的关系,也变相地梳理了优化器的流程















 1250
1250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









