







 文章讲述了如何使用并查集数据结构解决四道面试题:判断朋友圈数量、字符串相似性分组、查找多余边以及计算最长连续序列。这些问题都涉及图的子集操作,通过并查集的合并和查找功能来解决图的相关问题。
文章讲述了如何使用并查集数据结构解决四道面试题:判断朋友圈数量、字符串相似性分组、查找多余边以及计算最长连续序列。这些问题都涉及图的子集操作,通过并查集的合并和查找功能来解决图的相关问题。
目录
前言
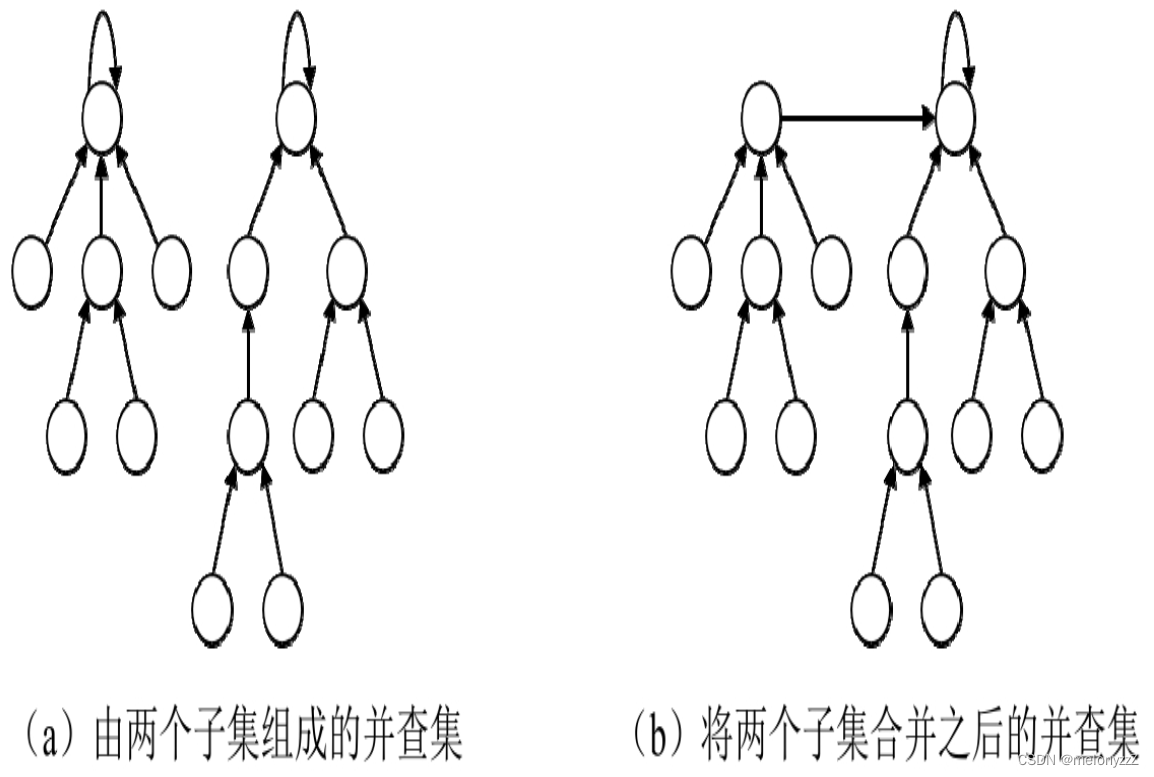
并查集是一种树形的数据结构,用来表示不相交集合的数据。并查集中的每个子集是一棵树,每个元素是某棵树中的一个节点。树中的每个节点有一个指向父节点的指针,树的根节点的指针指向它自己。例如,下图 (a) 所示是一个由两棵树组成的并查集。
并查集支持两种操作,即合并和查找。合并操作将两个子集合并成一个集合,只需要将一个子集对应的树的根节点的指针指向另一个子集对应的树的根节点。将下图 (a) 中的并查集的两个子集合并之后的并查集如下图 (b) 所示。
另一种操作是查找,即确定某个元素 v 处于哪个子集中。并查集的子集由对应的树的根节点代表。从元素 v 对应的节点开始沿着指向父节点的指针一直找到树的根节点,即节点的祖先节点。并查集的查找操作经常用来判断两个元素是否属于同一个子集。如果两个元素的祖先节点相同,那么它们属于同一个子集。
并查集经常用来解决图的动态连接问题。假设一个图中有 n 个节点,最开始的时候这 n 个节点互不连通,形成 n 个只有一个节点的子图。每次从图中选取两个节点,如果这两个节点不在同一个子图中,添加一条边连接着两个节点,那么它们所在的子图也就连通了。在添加了 m 条边之后,这个图中子图的数目是多少?最大的子图有多少个节点?这类问题都可以用并查集解决。图中的每个子图对应并查集中的子集,判断图中的两个节点是否在同一个子图就是判断它们对应的元素是否在并查集的同一个子集中,连通图中的两个子图就是合并并查集中的两个子集。
面试题 116 : 朋友圈
题目:
假设一个班级中有 n 个学生。学生之间有些是朋友,有些不是。朋友关系是可以传递的,例如,A 是 B 的直接朋友,B 是 C 的直接朋友,那么 A 是 C 的间接朋友。定义朋友圈就是一组直接朋友或间接朋友的学生。输入一个 n x n 的矩阵 M 表示班上的朋友关系,如果 M[i][j] = 1,那么学生 i 和 j 是直接朋友。请计算该班级中朋友圈的数目。
例如,输入数组 [[1, 1, 0], [1, 1, 0], [0, 0, 1]],学生 0 和学生 1 是朋友,他们组成一个朋友圈;学生 2 一个人组成一个朋友圈。因此该班级中朋友圈的数目是 2。
分析:
朋友关系是对称的,也就是说,A 和 B 是朋友,那么 B 和 A 自然也是朋友,因此,输入的矩阵 M 是沿着对角线对称的。一个人和他自己是朋友,也就是说矩阵 M 中对角线上的所有数字都是 1。
朋友的关系可以用图表示,每个学生就是图中的一个节点,而直接朋友就是图中的边。如果学生 i 和学生 j 是直接朋友,就在节点 i 和节点 j 之间添加一条边。输入的矩阵是图邻接矩阵。矩阵 [[1, 1, 0], [1, 1, 0], [0, 0, 1]] 转化成图之后如下图所示,不难发现这个图由两个子图组成,每个子图都是一个朋友圈,因此这个班有两个朋友圈。

应用图搜索解决问题:
一个班级可以包含一个或多个朋友圈,对应的图中可能包含一个或多个子图,每个朋友圈对应一个子图。因此,这个问题转化为如何求图中子图的数目。
图的搜索算法(广度优先搜索和深度优先搜索)可以用来计算图中子图的数目。扫描图中所有节点。如果某个节点 v 之前没有访问过,就搜索它所在的子图。当所有节点都访问完之后,就可以知道图中有多少子图。
class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected) {
int n = isConnected.size();
vector<bool> isVisited(n, false);
int result = 0;
for (int i = 0; i < n; ++i)
{
if (!isVisited[i])
{
dfs(isConnected, isVisited, i);
++result;
}
}
return result;
}
private:
void dfs(vector<vector<int>>& isConnected, vector<bool>& isVisited, int i) {
isVisited[i] = true;
for (int j = 0; j < isConnected.size(); ++j)
{
if (isConnected[i][j] == 1 && !isVisited[j])
dfs(isConnected, isVisited, j);
}
}
};应用并查集解决问题:
一个表示 n 个学生的朋友关系的图中有 n 个节点。在初始化时这个图有 n 个子图,每个子图都只包含一个节点。接下来一步步连接彼此是朋友的两个学生对应的节点,逐步形成朋友圈。
朋友关系用矩阵 M 表示。当 M[i][j] = 1 时,学生 i 和学生 j 是直接朋友,因此他们在同一个朋友圈中。这个时候要解决两个问题:
-
如何判断学生 i 和学生 j 是不是在同一个朋友圈(即子图)中,也就是判断节点 i 和节点 j 是否连通;
-
如果学生 i 和学生 j 之前不连通(不在同一个子图中),那么应该如何合并他们所在的两个子图使他们位于同一个子图(即同一个朋友圈)中。
并查集正好能完美地解决这两个问题。接下来介绍如何使用并查集。
并查集的子集和图中的子图对应,并查集中的子集用树形结构表示。子集的节点都有父节点,根节点的父节点就是它自身。同一个子集中不同的节点的根节点一定相同。判断两个节点是不是连通,也就是判断它们是不是属于同一个子集,只需要看它们的根节点是不是相同就可以。
创建长度为 n 的数组 fathers 存储 n 个节点的父节点。有了这个数组 fathers,如果想知道节点 i 所在的子集的根节点,就可以从节点 i 开始沿着指向父节点的指针搜索,时间复杂度看起来是 O(n),但可以将节点 i 到根节点的路径压缩,从而优化时间效率。
我们真正关心的是节点 i 的根节点是谁而不是它的父节点,因此可以在 fathers[i] 中存储它的根节点。当第 1 次找节点 i 的根节点时,还需要沿着指向父节点的边遍历直到找到根节点。一旦找到了它的根节点,就把根节点存放到 fathers[i] 中。不仅如此,还可以一起更新从节点 i 到根节点的路径上所有节点的根节点。以后只需要 O(1) 的时间就能知道这些节点的根节点。这种优化叫作路径压缩,因为从节点 i 到根节点的路径被压缩成若干长度为 1 的路径。
例如,如果查找下图 (a) 中节点 5 的根节点,就沿着指向父节点的指针依次找到节点 3、节点 2 和节点 1,最终发现根节点是节点 1,于是节点 2、节点 3 和节点 5 的根节点都更新为节点 1,如下图 (b) 所示。以后再查找这些节点的根节点,就只需要 O(1) 的时间。

接下来考虑如何合并两个子图。假设第 1 个子图的根节点是 i,第 2 个子图的根节点是 j。如果把 fathers[i] 设为 j,就相当于把整个第 1 个子图挂在节点 j 的下面,让第 1 个子图成为第 2 个子图的一部分,也就是合并两个子图。
class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected) {
int n = isConnected.size();
vector<int> fathers(n);
for (int i = 0; i < n; ++i)
{
fathers[i] = i;
}
int result = n;
for (int i = 0; i < n; ++i)
{
for (int j = i + 1; j < n; ++j)
{
if (isConnected[i][j] == 1 && Union(fathers, i, j))
--result;
}
}
return result;
}
private:
bool Union(vector<int>& fathers, int i, int j) {
int fatherOfI = findFather(fathers, i);
int fatherOfJ = findFather(fathers, j);
if (fatherOfI != fatherOfJ)
{
fathers[fatherOfI] = fatherOfJ;
return true;
}
else
return false;
}
int findFather(vector<int>& fathers, int x) {
if (fathers[x] != x)
fathers[x] = findFather(fathers, fathers[x]);
return fathers[x];
}
};面试题 117 : 相似的字符串
题目:
如果交换字符串 X 中的两个字符就能得到字符串 Y,那么两个字符串 X 和 Y 相似。例如,字符串 "tars" 和 "rats" 相似(交换下标为 0 和 2 的两个字符)、字符串 "rats" 和 "arts" 相似(交换下标为 0 和 1 的字符),但字符串 "star" 和 "tars" 不相似。
输入一个字符串数组,根据字符串的相似性分组,请问能把输入数组分成几组?如果一个字符串至少和一组字符串中的一个相似,那么它就可以放到该组中。假设输入数组中的所有字符串的长度相同并且两两互为变位词。例如,输入数组为 ["tars", "rats", "arts", "star"],可以分为两组,一组为 ["tars", "rats", "arts"],另一组为 ["star"]。
分析:
把输入数组中的每个字符串看成图中的一个节点。如果两个字符串相似,那么它们对应的节点之间有一条边相连,也就属于同一个子图。例如,字符串 ["tars", "rats", "arts", "star"] 根据相似性分别属于两个子图,如下图所示。

实际上,这个题目和面试题 116 非常类似。它们只是问题的背景不一样,一个是关于学生之间的朋友关系,一个是关于字符串的相似关系,但从本质上来看是同一类问题,都是求图中子图的数目。可以用非常相似的思路解决这个问题。
代码实现:
class Solution {
public:
int numSimilarGroups(vector<string>& strs) {
int n = strs.size();
vector<int> fathers(n);
for (int i = 0; i < n; ++i)
{
fathers[i] = i;
}
int result = n;
for (int i = 0; i < n; ++i)
{
for (int j = i + 1; j < n; ++j)
{
if (similar(strs[i], strs[j]) && Union(fathers, i, j))
--result;
}
}
return result;
}
private:
bool similar(string& str1, string& str2) {
int cnt = 0;
for (int i = 0; i < str1.size(); ++i)
{
if (str1[i] != str2[i])
++cnt;
}
return cnt <= 2;
}
bool Union(vector<int>& fathers, int i, int j) {
int fatherOfI = findFather(fathers, i);
int fatherOfJ = findFather(fathers, j);
if (fatherOfI != fatherOfJ)
{
fathers[fatherOfI] = fatherOfJ;
return true;
}
else
return false;
}
int findFather(vector<int>& fathers, int x) {
if (fathers[x] != x)
fathers[x] = findFather(fathers, fathers[x]);
return fathers[x];
}
};函数 similar 用来判断两个字符串是否相似。由于题目假设输入的字符串为一组变位词,因此只要两个字符串之间对应位置不同字符的个数不超过两个(0 个或 2 个),那么它们一定相似。
面试题 118 : 多余的边
题目:
树可以看成无环的无向图。在一个包含 n 个节点(节点标号为从 1 到 n)的树中添加一条边连接任意两个节点,这棵树就会变成一个有环图。给定一个在树中添加了一条边的图,请找出这条多余的边(用这条边连接的两个节点表示)。输入的图用一个二维数组 edges 表示,数组中的每个元素是一条边的两个节点 [u, v](u < v)。如果有多个答案,请输出在数组 edges 中最后出现的边。
例如,如果输入数组 edges 为 [[1, 2], [1, 3], [2, 4], [3, 4], [2, 5]],则它对应的无向图如下图所示。输出为边 [3, 4]。

分析:
如果将树看成图,那么一棵有 n 个节点的树有 n - 1 个条边。如果再在树中添加一条边连接任意两个节点,那么一定会形成一个环。在如上图所示的图中一共有 5 个节点。如果是树,那么它只能有 4 条边。现在图中有 5 条边,所以一定有一条边对于树而言是多余的。
逐步在图中添加 5 条边以便找出形成环的条件。最开始的时候图中的 5 个节点是离散的,任意两个节点都没有边相连。也就是说,图被分割成 5 个子图,每个子图只有一个节点。
先在图中添加一条边 [1, 2],于是将节点 1 和节点 2 所在的子图连接在一起,形成一个有两个节点的子图,如下图 (a) 所示。接下来添加一条边 [1, 3]。由于节点 1 和节点 3 分别属于两个不同的子图,添加这条边就将两个子图连接成一个包含三个节点的子图,如下图 (b) 所示。再在图中添加一条边 [2, 4]。由于节点 2 和节点 4 分别属于两个不同的子图,添加这条边就将两个子图连成一个包含四个节点子图,如下图 (c) 所示。然后在图中添加一条边 [3, 4]。此时节点 3 和节点 4 属于同一个子图,添加边 [3, 4] 导致图中出现了一个环,如下图 (d) 所示。最后添加边 [2, 5]。节点 2 和节点 5 属于不同的子图,这条边将两个子图连在一起形成一个包含五个节点的子图。

通过上面一步步在图中添加边可以发现判断一条边会不会导致环的规律。如果两个节点分别属于两个不同的子图,添加一条边连接着两个节点,会将它们所在的子图连在一起,但不会形成环。如果两个节点属于同一个子图,添加一条边连接这两个节点就会形成一个环。
因此,为了找到多余的边需要解决两个问题:一是如何判断两个节点是否属于同一个子图,二是如何合并两个子图。并查集刚好可以解决问题,由此可见,这是一个适合用并查集解决的问题。
代码实现:
class Solution {
public:
vector<int> findRedundantConnection(vector<vector<int>>& edges) {
int n = 0;
for (vector<int>& edge : edges)
{
n = max(n, edge[0]);
n = max(n, edge[1]);
}
vector<int> fathers(n + 1);
for (int i = 1; i <= n; ++i)
{
fathers[i] = i;
}
for (vector<int>& edge : edges)
{
if (!Union(fathers, edge[0], edge[1]))
return edge;
}
return vector<int>();
}
private:
bool Union(vector<int>& fathers, int i, int j) {
int fatherOfI = findFather(fathers, i);
int fatherOfJ = findFather(fathers, j);
if (fatherOfI != fatherOfJ)
{
fathers[fatherOfI] = fatherOfJ;
return true;
}
else
return false;
}
int findFather(vector<int>& fathers, int x) {
if (fathers[x] != x)
fathers[x] = findFather(fathers, fathers[x]);
return fathers[x];
}
};面试题 119 : 最长连续序列
题目:
输入一个无序的整数数组,请计算最长的连续数值序列的长度。例如,输入数组 [10, 5, 9, 2, 4, 3],则最长的连续数值序列是 [2, 3, 4, 5],因此输出 4。
分析:
这个题目是关于整数的连续性的。如果将每个整数看成图中的一个节点,相邻的(数值大小相差 1)两个整数有一条边相连,那么这些整数将形成若干子图,每个连续数值序列对应一个子图。例如,将数组 [10, 5, 9, 2, 4, 3] 中相邻的整数用边连通后形成的图如下图所示。计算最长连续序列的长度就转变成求最大子图的大小。

class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> us;
for (int num : nums)
{
us.insert(num);
}
int result = 0;
while (!us.empty())
{
auto it = us.begin();
result = max(result, getSize(us, *it));
}
return result;
}
private:
int getSize(unordered_set<int>& us, int num) {
int size = 1;
us.erase(num);
if (us.count(num - 1))
size += getSize(us, num - 1);
if (us.count(num + 1))
size += getSize(us, num + 1);
return size;
}
};














 8606
8606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









