







树形结构在数据库的设计过程中是一种比较常见的模型,指的是各元素之间存在‘一对多’的结构模型。在树形结构中,树根结点没有前驱结点,其余每个结点有且只有一个前驱结点。叶子结点没有后续结点,其余每个结点的后续节点数可以是一个也可以是多个。
在实际应用中,树形结构可以用来抽象很多具体问题,比如在‘成绩管理系统’中,班级类的表示,在该类的表示中,最上层应为‘XX学校’,下面依次是‘年级’、‘班级’。这便是一个典型的树形结构模型,最上层的‘XX学校’是树根节点,最下层的‘班级’则为叶子节点。
在设计数据库时,可为班级表设置四个字段:
‘classes_id’:表示对于树形结构中节点的编号;
‘classes_name’:表示节点名称;
‘pid’:表示当前节点父节点的id;
‘leaf’:用于区分当前节点是否为叶子节点。
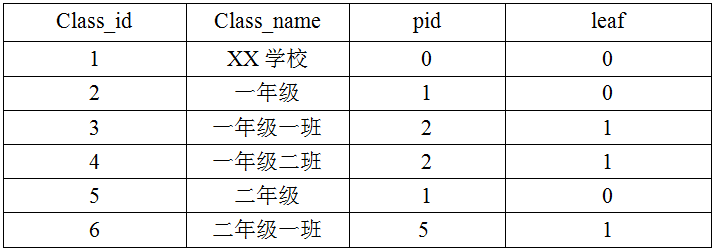
在数据库中建好对应的表’t_classes’后,可以使用Java实现对该表的CRUD操作,下面介绍递归的方法实现对表中元素遍历查询,并将其有层次地显示出来。
对应的Java语句如下所示:
package com.njupt.exam.manager;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import com.njupt.exam.util.DbUtil;
/**
* 班级管理类
* @author hzy
*
*/
public class ClassesManager {
public void dispalyClassesList() {
Connection conn = null;
try {
conn = DbUtil.getConnection();
displayClassesList(conn,0,0);
} catch(Exception e) {
e.printStackTrace();
//此处conn遵循一个原则:在哪里打开就在哪里关闭
} finally {
DbUtil.close(conn);
}
}
//构成方法重载
public void displayClassList(Connection conn,int pid,int level) {
//level表示空格的个数,随节点层数的增加而增加,使显示结果具有层次感
//此处s用于使显示结果更具有层次感
String s = "";
PreparedStatement psta = null;
ResultSet rs = null;
String sql = "use 成绩管理系统 select * from t_class where pid = ?";
for(int i=0;i<level;i++)
s += " ";
try {
psta = conn.prepareStatement(sql);
psta.setInt(1,pid);
rs = psta.executeQuery();
while(rs.next()) {
//打印输出当前节点的信息,当前节点的父节点为参数pid
System.out.println(s + rs.getInt("class_id") + " " + rs.getString("class_name"));
//判断当前节点是否为叶子节点
/*如果不是叶子节点,说明当前节点下还有子节点,需要再次调用自身对子节点进行显示,此时displayClassesList函数中应当传入的参数为conn,由于要对子节点进行显示,故pid应为当前节点的id,level随着节点层数的变化变为level+1*/
if(rs.getInt("leaf") == 0) { displayClassesList(conn,rs.getInt("class_id"),level+1)
}
}
} catch(SQLException e1) {
e1.printStackTrace();
} finally {
DbUtil.close(rs);
DbUtil.close(psta);
}
}
//主函数实现对显示函数的调用
public static void main(String args[]) {
new ClassesManager.displayClassesList();
}
} 执行结果为:
















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









