







提示:一直以来,都是查找别人的教程,而且每次都是查找不同的教程作以参考,这显得特别麻烦,所以笔者闲麻烦,尝试自己编写教程。一是为自己提供方便,二是能够为他人提供帮助。当然,读者若有不足之处,可以在评论区提出自己的独特见解。
目录
- 一、python 概述
- 二、环境搭建
- 三、Python 解释器
- 四、数据类型和基本语法
- 五、控制语句与循环语句
- 六、日期和时间
- 七、Python 函数
- 八、Python 3 数据结构
- 九、模块
- 十、 Python 输入和输出
- 十一、Python OS 文件/目录方法
- 十二、Python 异常处理
- 十三、面向对象
- 十四、Python 正则表达式
- 十五、Python CGI编程
- 十六、Python 操作 MySQL 数据库
- 十七、Python 网络编程
- 十八、Python SMTP发送邮件
- 十九、Python 多线程
- 二十、Python XML 解析
- 二十一、Python GUI编程(Tkinter)
- 二十二、Python JSON
- 附录一、内置函数
- 附录二、Python3 标准库概览
- 附录三、Python2.x与3.x版本区别
- 附录四、Python uWSGI 安装配置
- 附录五、Python MongoDB
- 附录六:[命令行与环境](https://docs.python.org/zh-cn/3.13/using/cmdline.html#using-on-general)
- 总结
一、python 概述
1.1 简介
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
Python 是交互式语言: 这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
1.2 特点
-
易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
-
易于阅读:Python代码定义的更清晰。
-
易于维护:Python的成功在于它的源代码是相当容易维护的。
-
一个广泛的标准库:Python的最大的优势之一是丰富的库,跨平台的,在UNIX,Windows和Macintosh兼容很好。
-
互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片断。
-
可移植:基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台。
-
可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
-
数据库:Python提供所有主要的商业数据库的接口。
-
GUI编程:Python支持GUI可以创建和移植到许多系统调用。
-
可嵌入: 你可以将Python嵌入到C/C++程序,让你的程序的用户获得"脚本化"的能力。
二、环境搭建
python 的下载官网:python地址
2.1 Windows 系统安装
-
点击上述地址,进入 python的官网;
-
点击 “Downloads”,在弹出的下拉菜单中点击版本型号;
-
下载完成后,双击安装程序,弹出安装对话框,并勾选“Add Python to PATH”;
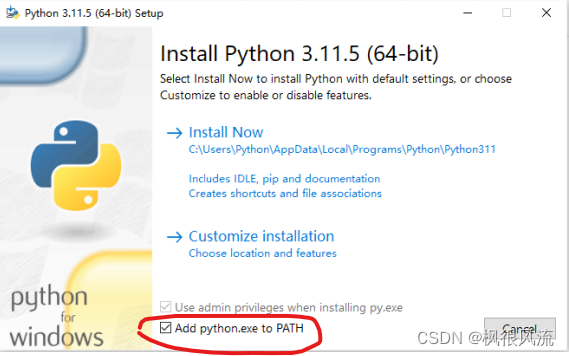
-
然后,点击 “Install Now” 或者 “Customize installation”,进行安装;
-
等待安装完成即可。
三、Python 解释器
3.1 调用解释器
在终端或命令提示符中,若要退出解释器可以使用Ctrl + D(Linux系统) 或 Ctrl + Z(Windows)或 输入这个命令 quit(),退出状态码为 0。
在支持 GNU Readline 库的系统中,解释器的行编辑功能包括交互式编辑、历史替换、代码补全等。检测是否支持命令行编辑最快速的方式是,在首次出现 Python 提示符时,输入 Control-P。听到“哔”提示音,说明支持行编辑;如果没有反应,或回显了 ^P,则说明不支持行编辑;只能用退格键删除当前行的字符。
解释器的操作方式类似 Unix Shell:用与 tty 设备关联的标准输入调用时,可以交互式地读取和执行命令;以文件名参数,或标准输入文件调用时,则读取并执行文件中的 脚本。
另一种启动解释器的方式是 python -c command [arg] …,这将执行 command 中的语句,相当于 shell 的 -c 选项。 由于 Python 语句经常包含空格或其他会被 shell 特殊对待的字符,通常建议用引号将整个 command 括起来。
Python 模块也可以当作脚本使用。输入:python -m module [arg] …,会执行 module 的源文件,这跟在命令行把路径写全了一样。
在交互模式下运行脚本文件,只要在脚本名称参数前,加上选项 -i 就可以了。
3.1.1 传入参数
解释器读取命令行参数,把脚本名与其他参数转化为字符串列表存到 sys 模块的 argv 变量里。执行 import sys,可以导入这个模块,并访问该列表。该列表最少有一个元素;未给定输入参数时,sys.argv[0] 是空字符串。给定脚本名是 ‘-’ (标准输入)时,sys.argv[0] 是 ‘-’。使用 -c command 时,sys.argv[0] 是 ‘-c’。如果使用选项 -m module,sys.argv[0] 就是包含目录的模块全名。解释器不处理 -c command 或 -m module 之后的选项,而是直接留在 sys.argv 中由命令或模块来处理。
3.1.2 交互模式
在终端(tty)输入并执行指令时,解释器在 交互模式(interactive mode) 中运行。在这种模式中,会显示 主提示符,提示输入下一条指令,主提示符通常用三个大于号(>>>)表示;输入连续行时,显示 次要提示符,默认是三个点(…)。进入解释器时,首先显示欢迎信息、版本信息、版权声明,然后才是提示符:
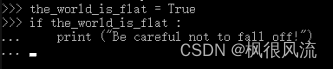
输入多行架构的语句时,要用连续行。以 if 为例:
3.1.3 脚本式编程
通过脚本参数调用解释器开始执行脚本,直到脚本执行完毕。当脚本执行完成后,解释器不再有效。
让我们写一个简单的 Python 脚本程序。所有 Python 文件将以 .py 为扩展名。将以下的源代码拷贝至 test.py 文件中。
print ("Hello, Python!")
这里,假设你已经设置了 Python 解释器 PATH 变量。使用以下命令运行程序:
$ python test.py
让我们尝试另一种方式来执行 Python 脚本。修改 test.py 文件,如下所示:
#!/usr/bin/python
print ("Hello, Python!")
这里,假定您的Python解释器在/usr/bin目录中,使用以下命令执行脚本:
$ chmod +x test.py # 脚本文件添加可执行权限
$ ./test.py
3.2 解释器的运行环境
3.2.1 源文件的字符编码
默认情况下,Python 源码文件的编码是 UTF-8。这种编码支持世界上大多数语言的字符,可以用于字符串字面值、变量、函数名及注释 —— 尽管标准库只用常规的 ASCII 字符作为变量名或函数名,可移植代码都应遵守此约定。要正确显示这些字符,编辑器必须能识别 UTF-8 编码,而且必须使用支持文件中所有字符的字体。
如果不使用默认编码,则要声明文件的编码,文件的 第一 行要写成特殊注释。句法如下:
# -*- coding: encoding -*-
其中,encoding 可以是 Python 支持的任意一种 codecs。
比如,声明使用 Windows-1252 编码,源码文件要写成:
# -*- coding: cp1252 -*-
第一行 的规则也有一种例外情况,源码以 UNIX “shebang” 行 开头。此时,编码声明要写在文件的第二行。例如:
#!/usr/bin/env python3
# -*- coding: cp1252 -*-
四、数据类型和基本语法
4.1 标识符
-
在 Python 里,标识符由字母、数字、下划线组成。
-
在 Python 中,所有标识符可以包括英文、数字以及下划线(_),但不能以数字开头。
-
Python 中的标识符是区分大小写的。
以下划线开头的标识符是有特殊意义的。以单下划线开头 _xxxx 的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用 from xxx import * 而导入。
以双下划线开头的 __xxxx 代表类的私有成员,以双下划线开头和结尾的 __xxx__ 代表 Python 里特殊方法专用的标识,如 __init__() 代表类的构造函数。
Python 可以同一行显示多条语句,方法是用分号 ; 分开。
4.2 数据类型
在内存中存储的数据可以有很多中类型。
python提供了Number(数字)、String(字符串)、List(列表)、Tuple(元组)、Dictionary(字典)、Set(集合)等六种数据类型。
4.3 变量
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。若变量未赋值,使用改变量就会报错。
在 Python 中,变量不需要指定数据类型。我们所说的"类型"是变量所指的内存中对象的类型。
等号(=)用来给变量赋值。等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。
>>> # 赋值后,下一个交互提示符的位置不显示任何结果
>>> width = 20
>>> height = 5 * 9
>>> width * height
900
>>> n # 变量未定义(即,未赋值),使用该变量会提示错误
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'n' is not defined
Python允许你同时为多个变量赋值。例如:
a = b = c = 1
以上实例,创建一个整型对象,值为1,三个变量被分配到相同的内存空间上。
您也可以为多个对象指定多个变量。例如:
a, b, c = 1, 2, "john"
以上实例,两个整型对象 1 和 2 分别分配给变量 a 和 b,字符串对象 “john” 分配给变量 c。
4.3.1 数值型
解释器像一个简单的计算器:你可以输入一个表达式,它将给出结果值。 表达式语法很直观:运算符 +, -, * 和 / 可被用来执行算术运算;圆括号 (()) 可被用来进行分组。 例如:
>>> # 数字
>>> 2 + 2
4
>>> 3 + 3
6
>>> 50 - 3 * 6
32
>>> (50 - 3 *6 ) / 4
8.0
>>> 8 / 5 # division always returns a floating point number
1.6
>>>
数字数据类型用于存储数值。他们是不可改变的数据类型,这意味着改变数字数据类型会分配一个新的对象。Python支持四种不同的数字类型:
- int(有符号整型):通常被称为是整型或整数,是正或负整数,不带小数点。
- long(长整型[也可以代表八进制和十六进制]) :无限大小的整数,整数最后是一个大写或小写的L。
- float(浮点型):浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
- complex(复数):复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
在Python3里,只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
内置的 type() 函数可以用来查询变量所指的对象类型。此外还可以用 isinstance 来判断。
isinstance 和 type 的区别在于:
- type()不会认为子类是一种父类类型。
- isinstance()会认为子类是一种父类类型。
当你指定一个值时,Number对象就会被创建:
var1 = 1
var2 = 10
也可以使用del语句删除一些对象的引用。
del语句的语法是:
del var1[,var2[,var3[....,varN]]]]
您可以通过使用del语句删除单个或多个对象的引用。例如:
del var
del var_a, var_b
注意:
- Python可以同时为多个变量赋值,如a, b = 1, 2。
- 一个变量可以通过赋值指向不同类型的对象。
- 数值的除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数。
- 在混合计算时,Python会把整型转换成为浮点数。
# Python 全面支持浮点数;混合类型运算数的运算会把整数转换为浮点数
>>> 4 * 3.75 - 1
14.0
长整型也可以使用小写 l,但是还是建议您使用大写 L,避免与数字 1 混淆。Python使用 L 来显示长整型。
Python 还支持复数,复数由实数部分和虚数(后缀 j 或 J 用于表示虚数)部分构成,可以用 a + bj,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型。例如 3+5j 。
注意:long 类型只存在于 Python2.X 版本中,在 2.2 以后的版本中,int 类型数据溢出后会自动转为long类型。在 Python3.X 版本中 long 类型被移除,使用 int 替代。
(解释器) 除法运算 (/) 总是返回浮点数。 如果要做 floor division 得到一个整数结果你可以使用 // 运算符;要计算余数你可以使用 % :
>>> 17 / 3 # classic division returns a float
5.666666666666667
>>>
>>> 17 // 3 # floor division discards the fractional part
5
>>>
>>> 17 % 3 # the % operator returns the remainder of the division
2
>>> 5 * 3 + 2 # floored quotient * divisor + remainder
17
>>>
(解释器) Python 用 ** 运算符计算乘方:
>>> 5 ** 2 # 5 squared
25
>>> 2 ** 7 # 2 to the power of 7
128
>>>
>>>
>>># ** 比 - 的优先级更高, 所以 -3**2 会被解释成 -(3**2) ,因此,结果是 -9。要避免这个问题,并且得到 9, 可以用 (-3)**2。
(解释器) 交互模式下,上次输出的表达式会赋给变量 _。把 Python 当作计算器时,用该变量实现下一步计算更简单,例如:
>>> tax = 12.5 / 100
>>> price = 100.50
>>> price * tax
12.5625
>>> price + _
113.0625
>>> round(_, 2)
113.06
>>>
最好把该变量当作只读类型。不要为它显式赋值,否则会创建一个同名独立局部变量,该变量会用它的魔法行为屏蔽内置变量。
数字函数:
| 函数 | 返回值 ( 描述 ) |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。 Python 3 已废弃,使用 (x>y)-(x<y) 替换。 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,…) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,…) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x, y) | x**y 运算后的值。 |
| round(x [,n]) | 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 |
| sqrt(x) | 返回数字x的平方根。 |
随机函数:
| 函数 | 描述 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
| randrange ([start,] stop [,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| random() | 随机生成下一个实数,它在[0,1)范围内。 |
| seed([x]) | 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成下一个实数,它在[x,y]范围内。 |
三角函数
| 函数 | 描述 |
|---|---|
| acos(x) | 返回x的反余弦弧度值。 |
| asin(x) | 返回x的反正弦弧度值 。 |
| atan(x) | 返回x的反正切弧度值。 |
| atan2(y, x) | 返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) | 返回x的弧度的余弦值。 |
| hypot(x, y) | 返回欧几里德范数 sqrt(xx + yy)。 |
| sin(x) | 返回的x弧度的正弦值。 |
| tan(x) | 返回x弧度的正切值。 |
| degrees(x) | 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 |
| radians(x) | 将角度转换为弧度 |
数学常量
| 常量 | 描述 |
|---|---|
| pi | 数学常量 pi(圆周率,一般以π来表示) |
| e | 数学常量 pi(圆周率,一般以π来表示) |
4.3.2 布尔型
在 Python2 中是没有布尔型的,它用数字 0 表示 False,用 1 表示 True。到 Python3 中,把 True 和 False 定义成关键字了,但它们的值还是 1 和 0,它们可以和数字相加。
4.3.3 字符串
Python中的字符串是用单引号 ’ 或双引号 " 括起来的数字、字母、下划线组成的一串字符,同时使用反斜杠 \ 转义特殊字符。
一般记为 :
s="a1a2···an"(n>=0)
它是编程语言中表示文本的数据类型。
python的字串列表有2种取值顺序:
- 从左到右索引默认0开始的,最大范围是字符串长度少1
- 从右到左索引默认-1开始的,最大范围是字符串开头
字符串的截取的语法格式如下:
变量[头下标:尾下标:步长]
如果你要实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标] 来截取相应的字符串,其中下标索引值以 0 为开始值或 -1 为从末尾的开始位置。可以是正数或负数,下标可以为空表示取到头或尾。[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符。比如:
# 声明一个字符串变量 b
b = "我不是迪迦奥特曼"
# 打印 b 的值
# 字符串的下标是从0开始的,最大范围是 “字符串长度 减 1”
print (b)
# 打印变量b的长度
print (len (b))
# 打印第一个到倒数第二个的所有字符
print (b[0: -1])
# 打印第一个到最后一个的所有字符,以下两种方式和 print (b) 效果是一样的,
print (b[0: 8])
print (b[0:])
# 打印第一个字符
print (b[0])
# 打印从第二个开始到第七个字符的字符
print (b[1:7])
# 打印字符串两次
print (b * 2)
# 连接字符串
print (b + ", 他才是")
当使用以冒号分隔的字符串,python 返回一个新的对象,结果包含了以这对偏移标识的连续的内容,左边的开始是包含了下边界。加号(+)是字符串连接运算符,星号(*)是重复操作。
Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
print (b[1:4:2])
Python 使用反斜杠(\)转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串:
# 反斜杠转义字符
print ("我不是\n迪迦奥特曼")
另外,反斜杠(\)可以作为续行符,表示下一行是上一行的延续。也可以使用 """...""" 或者'''...'''跨越多行。
# 可以使用 反斜杠 (\) 换行
print(
"我不是\
迪迦奥特曼"
)
# 可以使用 """...""" 跨越多行
print(
"""
黄鹤楼送孟浩然之广陵
[作者] 李白 [朝代] 唐
故人西辞黄鹤楼,烟花三月下扬州。
孤帆远影碧空尽,唯见长江天际流。
"""
)
# 可以使用 '''...''' 跨越多行
print(
'''
黄鹤楼送孟浩然之广陵
[作者] 李白 [朝代] 唐
故人西辞黄鹤楼,烟花三月下扬州。
孤帆远影碧空尽,唯见长江天际流。
'''
)
注意,Python 没有单独的字符类型,一个字符就是长度为1的字符串。
与 C语言 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如 word[0] = 'm' 会导致错误。
注意:
- 反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
- 字符串可以用+运算符连接在一起,用*运算符重复。
- Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。
- Python中的字符串不能改变。
Python转义字符
在需要在字符中使用特殊字符时,python用反斜杠()转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| (在行尾时) | 续行符 |
| \ | 反斜杠符号 |
| ’ | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy 代表的字符,例如:\o12 代表换行,其中 o 是字母,不是数字 0。 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
Python字符串运算符
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0,2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | ‘H’ in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | ‘M’ not in a 输出结果 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print( r'\n' ) print( R'\n' ) |
| % | 格式字符串 |
Python字符串格式化
Python 支持格式化字符串的输出 。最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 printf 函数一样的语法。
print ("我叫 %s 今年 %d 岁!" % ('小明', 10))
python字符串格式化符号:
| 符号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| <sp> | 在正数前面显示空格 |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ‘%%‘输出一个单一的’%’ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
f-string
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
# 格式化 使用 %
name = 'Runoob'
print ( 'Hello %s' % name )
# f-string 格式话字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,
# 它会将变量或表达式计算后的值替换进去
print (f'Hello {name}')
# 在 Python 3.8 的版本中可以使用 = 符号来拼接运算表达式与结果
x = 1
print(f'{x+1=}')
Unicode 字符串
Python 中定义一个 Unicode 字符串和定义一个普通字符串一样简单。普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。引号前小写的"u"表示这里创建的是一个 Unicode 字符串。如果你想加入一个特殊字符,可以使用 Python 的 Unicode-Escape 编码。
u'Hello\u0020World !'
字符串内建函数
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding=‘UTF-8’, errors=‘strict’) | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 ‘ignore’ 或 者’replace’ |
| string.encode(encoding=‘UTF-8’, errors=‘strict’) | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回 False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab]) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string)) | 类似于 find()函数,不过是从右边开始查找. |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是从右边开始. |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str=“”, num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+ 个子字符串 |
| string.splitlines([keepends]) | 按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
| string.strip([obj]) | 在 string 上执行 lstrip()和 rstrip() |
| string.swapcase() | 翻转 string 中的大小写 |
| string.title() | 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.translate(str, del=“”) | 根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 del 参数中 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
4.3.4 列表
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。Python有6个序列的内置类型,但最常见的是列表和元组。序列都可以进行的操作包括索引,切片,加,乘,检查成员。此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
List(列表) 是 Python 中使用最频繁的数据类型。列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表用 [ ] 标识,写在方括号 [] 之间、用逗号分隔开的元素列表,是 python 最通用的复合数据类型。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。列表被截取后返回一个包含所需元素的新列表。
列表截取的语法格式如下:
- 变量[头下标:尾下标]
- 变量[头下标:尾下标:步长]
- 索引值以 0 为开始值,-1 为从末尾的开始位置。
加号 + 是列表连接运算符,星号 * 是重复操作。如下实例:
# 声明一个列表 list,并赋值
list = [123, "我不是迪迦奥特曼", "他才是", [2345, "内嵌列表"]]
# 声明一个列表 t_list,并赋值
t_list = ["我要", "拼接", "列表"]
# 打印列表
print(list)
# 打印列表第一个元素
print(list[0])
# 打印从第二个开始输出到第三个元素
print(list[1:3])
# 打印从第三个元素开始的所有元素
print(list[2:])
# 打印两次列表
print (list * 2)
# 打印拼接后的列表
print (list + t_list)
与Python字符串不一样的是,列表中的元素是可以改变的:
# 更改列表中元素的值
list[0] = "我要更改值"
print (list)
List 内置了有很多方法,例如 append()、pop() 等等。
注意:
- List写在方括号之间,元素用逗号隔开。
- 和字符串一样,list可以被索引和切片。
- List可以使用+操作符进行拼接。
- List中的元素是可以改变的。
Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
# 设置步长
print (list[1:4:2])
如果第三个参数为负数表示逆向读取,以下实例用于翻转字符串:
print (list[::-2])
列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代 |
列表函数&方法
| 函数 | 描述 |
|---|---|
| len(list) | 列表元素个数 |
| max(list) | 返回列表元素最大值 |
| min(list) | 返回列表元素最小值 |
| list(seq) | 将元组转换为列表 |
| 方法 | 描述 |
|---|---|
| list.append(obj) | 在列表末尾添加新的对象 |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index, obj) | 将对象插入列表 |
| list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
| list.reverse() | 反向列表中元素 |
| list.sort( key=None, reverse=False) | 对原列表进行排序 |
| list.clear() | 清空列表 |
| list.copy() | 复制列表 |
4.3.5 元组
元组是另一个数据类型,类似于 List(列表)。不同之处在于元组的元素不能修改。元组写在小括号 () 里,内部元素之间用逗号隔开。
元组中的元素类型也可以不相同:
# 声明一个元组 tuple,并赋值
tuple = (123, "我不是迪迦奥特曼", "他才是", [2345, "内嵌列表"])
# 声明一个元组 t_tuple,并赋值
t_tuple = ("我要", "拼接", "元组")
# 打印元组
print(tuple)
# 打印元组第一个元素
print(tuple[0])
# 打印从第二个开始输出到第三个元素
print(tuple[1:3])
# 打印从第三个元素开始的所有元素
print(tuple[2:])
# 打印两次元组
print (tuple * 2)
# 打印拼接后的元组
print (tuple + t_tuple)
元组与字符串类似,可以被索引且下标索引从0开始,-1 为从末尾开始的位置。也可以进行截取(看上面,这里不再赘述)。其实,可以把字符串看作一种特殊的元组。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
# 空元组
tuple = ()
print(tuple)
# 一个元素,需要在元素后添加逗号
tuple = (20,)
print(tuple)
string、list 和 tuple 都属于 sequence(序列)。
注意:
- 与字符串一样,元组的元素不能修改。
- 元组也可以被索引和切片,方法一样。
- 注意构造包含 0 或 1 个元素的元组的特殊语法规则。
- 元组也可以使用+操作符进行拼接。
元组运算符
元组对 + 和 * 的操作符与字符串相似。+ 号用于组合元组,* 号用于重复元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 长度 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 组合 |
| (‘Hi!’) * 4 | (‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’) | 重复 |
| 3 in (1, 2, 3) | True | 元素是否存在于列表中 |
| for x in (1, 2, 3): print(x, end=" ") | 1 2 3 | 迭代 |
无关闭分隔符
任意无符号的对象,以逗号隔开,默认为元组。
元组内置函数
| 方法 | 描述 |
|---|---|
| cmp(tuple1, tuple2) | 比较两个元组元素。 |
| len(tuple) | 计算元组元素个数。 |
| max(tuple) | 返回元组中元素最大值。 |
| min(tuple) | 返回元组中元素最小值。 |
| tuple(seq) | 将列表转换为元组。 |
4.3.6 字典
字典(dictionary) 是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。在同一个字典中,键(key)必须是唯一的。
# 定义一个空的字典
dictionary_0 = {}
# 为字典dictionary_0 赋值
dictionary_0["first"] = "first"
dictionary_0[21] = 21
# 打印字典dictionary_0
print(dictionary_0)
# 声明一个字典 dictionary ,并赋值
dictionary = {"dict1": 123, "dict2": "我不是迪迦奥特曼", "dict3": "他才是", "dict4": [2345, "内嵌列表"]}
# 声明一个字典 t_dictionary ,并赋值
t_dictionary = {"dict0":"我要", "dict1":"拼接", "dict2": "字典"}
# 打印字典
print(dictionary)
# 打印字典 key为 dict1
print(dictionary["dict1"])
# 打印字典 key为 dict2
print(dictionary["dict2"])
# 打印字典 key为 dict3
print(dictionary["dict3"])
# 打印字典 key为 dict4
print(dictionary["dict4"])
# 打印所有的key
print (t_dictionary.keys())
# 打印所有的value
print (t_dictionary.values())
构造函数 dict() 可以直接从键值对序列中构建字典如下:
# 构造函数构建字典
dictionary = dict([("1", "123"), ("2","234")])
print (dictionary)
另外,字典类型也有一些内置的函数,例如clear()、keys()、values()等。
注意:
- 字典是一种映射类型,它的元素是键值对。
- 字典的关键字必须为不可变类型,且不能重复。所以可以用数字,字符串或元组充当,而用列表就不行。
- 创建空字典使用 { }。
字典内置函数&方法
| 函数 | 描述 |
|---|---|
| len(dict) | 计算字典元素个数,即键的总数。 |
| str(dict) | 输出字典,以可打印的字符串表示。 |
| type(variable) | 返回输入的变量类型,如果变量是字典就返回字典类型。 |
| 函数 | 描述 |
|---|---|
| radiansdict.clear() | 删除字典内所有元素 |
| radiansdict.copy() | 返回一个字典的浅复制 |
| radiansdict.fromkeys() | 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| radiansdict.get(key, default=None) | 返回指定键的值,如果值不在字典中返回default值 |
| key in dict | 如果键在字典dict里返回true,否则返回false |
| radiansdict.items() | 以列表返回可遍历的(键, 值) 元组数组 |
| radiansdict.keys() | 返回一个迭代器,可以使用 list() 来转换为列表 |
| radiansdict.setdefault(key, default=None) | 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| radiansdict.update(dict2) | 把字典dict2的键/值对更新到dict里 |
| radiansdict.values() | 返回一个迭代器,可以使用 list() 来转换为列表 |
| pop(key[,default]) | 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| popitem() | 随机返回并删除字典中的最后一对键和值。 |
4.3.7 Set集合
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
set(value)
实例:
# 声明一个集合 sets ,并赋值
sets = {'Tom', 'Jim', 'Mary', 'Tom', 'Jack', 'Rose'}
print(sets)
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
c = set(['Tom', 'Jim', 'Mary', 'Tom', 'Jack', 'Rose'])
# 使用set()时,根据打印结果: {'d', 'a', 'b', 'c', 'r'},可以判断出,Set集合会去重,但不会排序
print ("a = " , a)
print ("b = " , b)
print ("c = " , c)
# a 和 b 的差集
print(a - b)
# a 和 b 的并集
print(a | b)
# a 和 b 的交集
print(a & b)
# a 和 b 中不同时存在的元素
print(a ^ b)
集合的基本操作
1、添加元素
s.add( x )
还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式如下:
s.update( x )
2、移除元素
s.remove( x )
此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示:
s.discard( x )
也可以设置随机删除集合中的一个元素,语法格式如下:
s.pop()
set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除
3、计算集合元素个数
语法格式如下:
len(s)
4、清空集合
语法格式如下:
s.clear()
5、判断元素是否在集合中存在
语法格式如下:
x in s
集合内置方法完整列表
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
4.4 运算符
4.4.1 算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 31 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -11 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 210 |
| / | 除 - x 除以 y | b / a 输出结果 2.1 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 1 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的21次方 |
| // | 取整除 - 向下取接近除数的整数 | >>> 9//2 的结果 4 ,>>> -9//2 的结果 -5 |
实例:
a = 21
b = 10
c = 0
c = a + b
print (" c 的值为:", c)
c = a - b
print (" c 的值为:", c)
c = a * b
print (" c 的值为:", c)
c = a / b
print (" c 的值为:", c)
c = a % b
print (" c 的值为:", c)
# 修改变量 a 、b 、c
a = 2
b = 3
c = a**b
print (" c 的值为:", c)
a = 10
b = 5
c = a//b
print (" c 的值为:", c)
注意:Python2.x 里,整数除整数,只能得出整数。如果要得到小数部分,把其中一个数改成浮点数即可。
4.4.2 比较(关系)运算符
| 运算符 | 运算符 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 true |
| <> | 不等于 - 比较两个对象是否不相等。python3 已废弃。这个运算符类似 !=。 | (a <> b) 返回 true。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。 | (a < b) 返回 true |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 true |
实例:
a = 21
b = 10
c = 0
if a == b :
print "1 : a 等于 b"
else:
print "1 :a 不等于 b"
if a != b :
print "2 :a 不等于 b"
else:
print "2 :a 等于 b"
if a <> b :
print "3 :a 不等于 b"
else:
print "3 :a 等于 b"
if a < b :
print "4 :a 小于 b"
else:
print "4 :a 大于等于 b"
if a > b :
print "5 :a 大于 b"
else:
print "5 :a 小于等于 b"
# 修改变量 a 和 b 的值
a = 5
b = 20
if a <= b :
print "6 :a 小于等于 b"
else:
print "6 :a 大于 b"
if b >= a :
print "7 :b 大于等于 a"
else:
print "7 :b 小于 a"
4.4.3 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| := | 海象运算符,可在表达式内部为变量赋值。Python3.8 版本新增运算符。 | 在这个示例中,赋值表达式可以避免调用 len() 两次: if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)") |
实例:
a = 21
b = 10
c = 0
c = a + b
print ("a + b 的值为:", c)
c += a
print ("c += a 的值为:", c)
c *= a
print ("c *= a 的值为:", c)
c /= a
print ("c /= a 的值为:", c)
c = 2
c %= a
print ("c %= a 的值为:", c)
c **= a
print ("c **= a 的值为:", c)
c //= a
print ("c //= a 的值为:", c)
4.4.4 逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20 |
| or | x or y | 布尔"或" - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
实例:
a = 10
b = 20
if ( a and b ):
print (" a and b : 变量 a 和 b 都为 true")
else:
print ("a and b : 变量 a 和 b 有一个不为 true")
if ( a or b ):
print ("a or b : 变量 a 和 b 都为 true,或其中一个变量为 true")
else:
print ("a or b : 变量 a 和 b 都不为 true")
# 修改变量 a 的值
a = 0
if ( a and b ):
print ("a and b :变量 a 和 b 都为 true")
else:
print ("a and b : 变量 a 和 b 有一个不为 true")
if ( a or b ):
print ("a or b : 变量 a 和 b 都为 true,或其中一个变量为 true")
else:
print ("a or b : 变量 a 和 b 都不为 true")
if not( a and b ):
print ("not( a and b ) 变量 a 和 b 都为 false,或其中一个变量为 false")
else:
print ("not( a and b ) 变量 a 和 b 都为 true")
4.4.5 位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1。 | ~x 类似于 -x-1 (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把">>“左边的运算数的各二进位全部右移若干位,”>>"右边的数指定移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
实例:
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
print ("a & b 的值为:", c)
c = a | b; # 61 = 0011 1101
print ("a | b 的值为:", c)
c = a ^ b; # 49 = 0011 0001
print ("a ^ b 的值为:", c)
c = ~a; # -61 = 1100 0011
print ("~a 的值为:", c)
c = a << 2; # 240 = 1111 0000
print ("a << 2 的值为:", c)
c = a >> 2; # 15 = 0000 1111
print ("a >> 2 的值为:", c)
4.4.6 成员运算符
Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True |
实例:
a = 10
b = 20
list = [1, 2, 3, 4, 5 ];
if ( a in list ):
print ("list 变量 a 在给定的列表中 list 中")
else:
print ("list 变量 a 不在给定的列表中 list 中")
if ( b not in list ):
print ("list 变量 b 不在给定的列表中 list 中")
else:
print ("list 变量 b 在给定的列表中 list 中")
# 修改变量 a 的值
a = 2
if ( a in list ):
print ("list 变量 a 在给定的列表中 list 中")
else:
print ("list 变量 a 不在给定的列表中 list 中")
4.4.7 身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
注: id() 函数用于获取对象内存地址。
实例:
a = 20
b = 20
if ( a is b ):
print "a is b 有相同的标识"
else:
print "a is b 没有相同的标识"
if ( a is not b ):
print "a is not b 没有相同的标识"
else:
print "a is not b 有相同的标识"
# 修改变量 b 的值
b = 30
if ( a is b ):
print "a is b 有相同的标识"
else:
print "a is b 没有相同的标识"
if ( a is not b ):
print "a is not b 没有相同的标识"
else:
print "a is not b 有相同的标识"
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
4.4.8 运算符优先级
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
实例:
a = 20
b = 10
c = 15
d = 5
e = 0
e = (a + b) * c / d #( 30 * 15 ) / 5
print "(a + b) * c / d 运算结果为:", e
e = ((a + b) * c) / d # (30 * 15 ) / 5
print "((a + b) * c) / d 运算结果为:", e
e = (a + b) * (c / d); # (30) * (15/5)
print "(a + b) * (c / d) 运算结果为:", e
e = a + (b * c) / d; # 20 + (150/5)
print "a + (b * c) / d 运算结果为:", e
4.5 类型转换
有时候,需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
| 函数 | 描述 |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
4.6 基本语法
4.6.1 行和缩进
学习 Python 与其他语言最大的区别就是,Python 的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断。python 最具特色的就是用缩进来写模块。
缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
IndentationError: unindent does not match any outer indentation level错误表明,你使用的缩进方式不一致,有的是 tab 键缩进,有的是空格缩进,改为一致即可。
如果是 IndentationError: unexpected indent 错误, 则 python 编译器是在告诉你"Hi,老兄,你的文件里格式不对了,可能是tab和空格没对齐的问题",所有 python 对格式要求非常严格。
因此,在 Python 的代码块中必须使用相同数目的行首缩进空格数。
建议你在每个缩进层次使用 单个制表符 或 两个空格 或 四个空格 , 切记不能混用
4.6.2 多行语句
Python语句中一般以新行作为语句的结束符。
但是我们可以使用斜杠( \)将一行的语句分为多行显示,如下所示:
total = item_one + \
item_two + \
item_three
语句中包含 [], {} 或 () 括号就不需要使用多行连接符。如下实例:
days = ['Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday']
4.6.3 Python 引号
Python 可以使用引号( ’ )、双引号( " )、三引号( ‘’’ 或 “”" ) 来表示字符串,引号的开始与结束必须的相同类型的。
其中三引号可以由多行组成,编写多行文本的快捷语法,常用于文档字符串,在文件的特定地点,被当做注释。
word = 'word'
sentence = "这是一个句子。"
paragraph = """这是一个段落。
包含了多个语句"""
4.6.4 Python注释
- python中单行注释采用 # 开头。
- python 中多行注释使用三个单引号(‘’')或三个双引号(“”")。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:test.py
'''
这是多行注释,使用单引号。
这是多行注释,使用单引号。
这是多行注释,使用单引号。
'''
"""
这是多行注释,使用双引号。
这是多行注释,使用双引号。
这是多行注释,使用双引号。
"""
4.6.5 Python空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是Python语法的一部分。书写时不插入空行,Python解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
记住:空行也是程序代码的一部分。
4.6.6 同一行显示多条语句
Python可以在同一行中使用多条语句,语句之间使用分号(;)分割,以下是一个简单的实例:
#!/usr/bin/python
import sys; x = 'runoob'; sys.stdout.write(x + '\n')
4.6.7 多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。
我们将首行及后面的代码组称为一个子句(clause)。
如下实例:
if expression :
suite
elif expression :
suite
else :
suite
4.6.8 命令行参数
很多程序可以执行一些操作来查看一些基本信息,Python 可以使用 -h 参数查看各参数帮助信息:
$ python -h
usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
-c cmd : program passed in as string (terminates option list)
-d : debug output from parser (also PYTHONDEBUG=x)
-E : ignore environment variables (such as PYTHONPATH)
-h : print this help message and exit
[ etc. ]
4.7 保留字
五、控制语句与循环语句
5.1 控制语句
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。Python程序语言指定任何非0和非空(null)值为 True,0 或者 null为 False。
Python 编程中 if 语句用于控制程序的执行,基本形式为:
if 判断条件:
执行语句……
else:
执行语句……
其中"判断条件"成立时(非零),则执行后面的语句,而执行内容可以多行,以缩进来区分表示同一范围。else 为可选语句,当需要在条件不成立时执行内容则可以执行相关语句。
实例:
# if ... else ...
condition = 20
if condition == 21:
print("你家孩子已经21岁了")
else:
print("我家孩子才20岁")
当判断条件为多个值时,可以使用以下形式:
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
如果 “condition_1” 为 True 将执行 “statement_block_1” 块语句
如果 “condition_1” 为False,将判断 “condition_2”
如果"condition_2" 为 True 将执行 “statement_block_2” 块语句
如果 “condition_2” 为False,将执行"statement_block_3"块语句
Python 中用 elif 代替了 else if,所以if语句的关键字为:if – elif – else。
实例:
# if ... elif ... else ...
condition = 20
if condition == 21:
print("你家孩子已经21岁了")
elif condition != 20:
print("我家孩子22岁")
elif condition < 20:
print("他家孩子18岁")
elif condition > 22:
print("他家孩子23岁")
else:
print("他家孩子才20岁")
注意:
- 每个条件后面要使用冒号 :,表示接下来是满足条件后要执行的语句块。
- 使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
- 在Python中没有switch – case语句。
if 语句的判断条件可以用>(大于)、<(小于)、==(等于)、>=(大于等于)、<=(小于等于)来表示其关系。
由于 python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现,如果判断需要多个条件需同时判断时,可以使用 or (或),表示两个条件有一个成立时判断条件成功;使用 and (与)时,表示只有两个条件同时成立的情况下,判断条件才成功。
当if有多个条件时可使用括号来区分判断的先后顺序,括号中的判断优先执行,此外 and 和 or 的优先级低于>(大于)、<(小于)等判断符号,即大于和小于在没有括号的情况下会比与或要优先判断。
if 嵌套
在嵌套 if 语句中,可以把 if…elif…else 结构放在另外一个 if…elif…else 结构中。
if 表达式1:
语句
if 表达式2:
语句
elif 表达式3:
语句
else:
语句
elif 表达式4:
语句
else:
语句
实例:
# if ... else ... 嵌套
condition = int(input("输入一个数字:"))
if condition % 2 == 0:
if condition % 3 == 0:
print("你输入的数字可以整除 2 和 3")
else:
print("你输入的数字可以整除 2,但不能整除 3")
else:
if condition % 3 == 0:
print("你输入的数字可以整除 3,但不能整除 2")
else:
print("你输入的数字不能整除 2 和 3")
5.2 循环语句
Python 中的循环语句有 for 和 while。
5.2.1 while 循环
while 循环是 在给定的判断条件为 true 时执行循环体,否则退出循环体。Python 中 while 语句的一般形式:
while 判断条件(condition):
执行语句(statements)……
while 循环的执行流程如下:
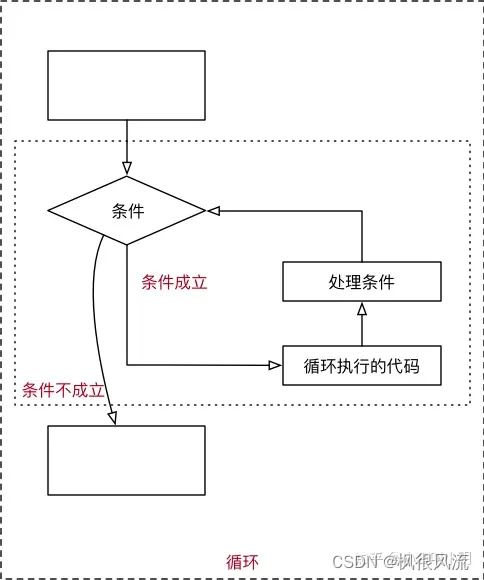
同样需要注意冒号和缩进。另外,在 Python 中没有 do..while 循环。
实例
# 使用了 while 来计算 1 到 100 的总和:
n = 100
sum = 0
counter = 1
while counter <= n:
sum = sum + counter
counter += 1
print("1 到 %d 之和为: %d" % (n,sum))
无限循环
通过设置条件表达式永远不为 false 来实现无限循环,实例如下:
var = 1
while var == 1 : # 表达式永远为 true
num = int(input("输入一个数字 :"))
print ("你输入的数字是: ", num)
print ("Good bye!")
while 循环使用 else 语句
在 while … else 在条件语句为 false 时执行 else 的语句块。语法格式如下:
while <expr>:
<statement(s)>
else:
<additional_statement(s)>
实例:
count = 0
while count < 5:
print (count, " 小于 5")
count = count + 1
else:
print (count, " 大于或等于 5")
5.2.2 for 循环
Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串。for循环的语法格式如下:
for iterating_var in sequence:
statements(s)
执行流程如下:
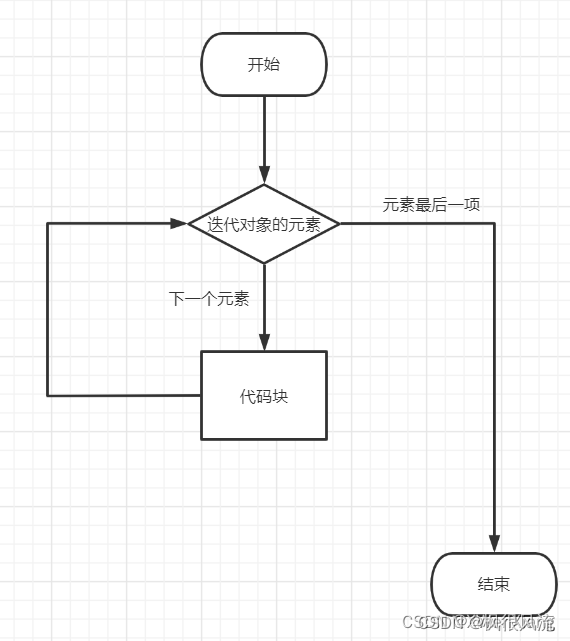
实例:
languages = ["C", "C++", "Perl", "Python"]
for x in languages:
print (x)
通过序列索引迭代
另外一种执行循环的遍历方式是通过索引,如下实例:
fruits = ["banana", "apple", "mango"]
for index in range(len(fruits)):
print("当前水果 :", fruits[index])
print("Good bye!")
for 循环使用 else 语句
在 python 中,for … else 表示这样的意思,for 中的语句和普通的没有区别,else 中的语句会在循环正常执行完(即 for 不是通过 break 跳出而中断的)的情况下执行,while … else 也是一样。
实例:
for num in range(10, 20): # 迭代 10 到 20 之间的数字
for i in range(2, num): # 根据因子迭代
if num % i == 0: # 确定第一个因子
j = num / i # 计算第二个因子
print("%d 等于 %d * %d" % (num, i, j))
break # 跳出当前循环
else: # 循环的 else 部分
print(num, "是一个质数")
5.2.3 Python 循环嵌套
Python 语言允许在一个循环体里面嵌入另一个循环。
Python for 循环嵌套语法:
for iterating_var in sequence:
for iterating_var in sequence:
statements(s)
statements(s)
Python while 循环嵌套语法:
while expression:
while expression:
statement(s)
statement(s)
你可以在循环体内嵌入其他的循环体,如在while循环中可以嵌入for循环, 反之,你可以在for循环中嵌入while循环。
5.2.4 range()函数
如果你需要遍历数字序列,可以使用内置range()函数。它会生成等差数列,例如:
for index in range(5):
print(index)
for index in range(5, 10):
print(index)
# 你也可以使用range指定区间的值:
for index in range(0, 10, 3):
print(index)
# 负数:
for index in range(-10, -100, -30):
print(index)
# 您可以结合range()和len()函数以遍历一个序列的索引,如下所示:
a = ['Google', 'Baidu', 'Runoob', 'Taobao', 'QQ']
for index in range(len(a)):
print(index, a[index])
# 还可以使用range()函数来创建一个列表:
a = list(range(5))
5.2.5 break语句 和 continue语句
1. break 语句
Python break语句,就像在C语言中,打破了最小封闭for或while循环。break语句用来终止循环语句,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。break语句用在while和for循环中。如果您使用嵌套循环,break语句将停止执行最深层的循环,并开始执行下一行代码。Python语言 break 语句语法:
break
实例:
for letter in "Python": # 第一个实例
if letter == "h":
break
print("当前字母 :", letter)
var = 10 # 第二个实例
while var > 0:
print("当前变量值 :", var)
var = var - 1
if var == 5: # 当变量 var 等于 5 时退出循环
break
print("Good bye!")
循环语句可以有 else 子句,它在穷尽列表(以for循环)或条件变为 false (以while循环)导致循环终止时被执行,但循环被 break 终止时不执行。
2. continue 语句
Python continue 语句跳出本次循环,而break跳出整个循环。continue 语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。continue语句用在while和for循环中。Python 语言 continue 语句语法格式如下:
continue
实例:
for letter in "Python": # 第一个实例
if letter == "h":
continue
print("当前字母 :", letter)
var = 10 # 第二个实例
while var > 0:
var = var - 1
if var == 5:
continue
print("当前变量值 :", var)
print("Good bye!")
5.2.6 pass 语句
Python pass 是空语句,是为了保持程序结构的完整性。pass 不做任何事情,一般用做占位语句。Python 语言 pass 语句语法格式如下:
pass
实例:
# 输出 Python 的每个字母
for letter in "Python":
if letter == "h":
pass
print("这是 pass 块")
print("当前字母 :", letter)
print("Good bye!")
5.2.7 match 语句
match 语句接受一个表达式并把它的值与一个或多个 case 块给出的一系列模式进行比较。这表面上像 C、Java 或 JavaScript(以及许多其他程序设计语言)中的 switch 语句,但其实它更像 Rust 或 Haskell 中的模式匹配。只有第一个匹配的模式会被执行,并且它还可以提取值的组成部分(序列的元素或对象的属性)赋给变量。
最简单的形式是将一个主语值与一个或多个字面值进行比较:
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something's wrong with the internet"
注意最后一个代码块:“变量名” _ 被作为 通配符 并必定会匹配成功。如果没有 case 匹配成功,则不会执行任何分支。
你可以用 | (“或”)将多个字面值组合到一个模式中:
case 401 | 403 | 404:
return "Not allowed"
形如解包赋值的模式可被用于绑定变量:
# point is an (x, y) tuple
match point:
case (0, 0):
print("Origin")
case (0, y):
print(f"Y={y}")
case (x, 0):
print(f"X={x}")
case (x, y):
print(f"X={x}, Y={y}")
case _:
raise ValueError("Not a point")
第一个模式有两个字面值,可视为前述字面值模式的扩展。接下来的两个模式结合了一个字面值和一个变量,变量 绑定 了来自主语(point)的一个值。第四个模式捕获了两个值,使其在概念上与解包赋值 (x, y) = point 类似。
如果用类组织数据,可以用“类名后接一个参数列表”这种很像构造器的形式,把属性捕获到变量里:
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def where_is(point):
match point:
case Point(x=0, y=0):
print("Origin")
case Point(x=0, y=y):
print(f"Y={y}")
case Point(x=x, y=0):
print(f"X={x}")
case Point():
print("Somewhere else")
case _:
print("Not a point")
一些内置类(如 dataclass)为属性提供了一个顺序,此时,可以使用位置参数。自定义类可通过在类中设置特殊属性 __match_args__,为属性指定其在模式中对应的位置。若设为 (“x”, “y”),则以下模式相互等价(且都把属性 y 绑定到变量 var):
Point(1, var)
Point(1, y=var)
Point(x=1, y=var)
Point(y=var, x=1)
建议这样来阅读一个模式——通过将其视为赋值语句等号左边的一种扩展形式,来理解各个变量被设为何值。match 语句只会为单一的名称(如上面的 var)赋值,而不会赋值给带点号的名称(如 foo.bar)、属性名(如上面的 x= 和 y=)和类名(是通过其后的 “(…)” 来识别的,如上面的 Point)。
模式可以任意嵌套。举例来说,如果我们有一个由 Point 组成的列表,且 Point 添加了 __match_args__ 时,我们可以这样来匹配它:
class Point:
__match_args__ = ('x', 'y')
def __init__(self, x, y):
self.x = x
self.y = y
match points:
case []:
print("No points")
case [Point(0, 0)]:
print("The origin")
case [Point(x, y)]:
print(f"Single point {x}, {y}")
case [Point(0, y1), Point(0, y2)]:
print(f"Two on the Y axis at {y1}, {y2}")
case _:
print("Something else")
我们可以为模式添加 if 作为守卫子句。如果守卫子句的值为假,那么 match 会继续尝试匹配下一个 case 块。注意是先将值捕获,再对守卫子句求值:
match point:
case Point(x, y) if x == y:
print(f"Y=X at {x}")
case Point(x, y):
print(f"Not on the diagonal")
该语句的一些其它关键特性:
-
与解包赋值类似,元组和列表模式具有完全相同的含义并且实际上都能匹配任意序列,区别是它们不能匹配迭代器或字符串。
-
序列模式支持扩展解包:[x, y, *rest] 和 (x, y, *rest) 和相应的解包赋值做的事是一样的。接在 * 后的名称也可以为 ,所以 (x, y, *) 匹配含至少两项的序列,而不必绑定剩余的项。
-
映射模式:{“bandwidth”: b, “latency”: l} 从字典中捕获 “bandwidth” 和 “latency” 的值。额外的键会被忽略,这一点与序列模式不同。**rest 这样的解包也支持。(但 **_ 将会是冗余的,故不允许使用。)
-
使用 as 关键字可以捕获子模式:
case (Point(x1, y1), Point(x2, y2) as p2): ...
将把输入中的第二个元素捕获为 p2 (只要输入是包含两个点的序列)
-
大多数字面值是按相等性比较的,但是单例对象 True、False 和 None 则是按 id 比较的。
-
模式可以使用具名常量。它们必须作为带点号的名称出现,以防止它们被解释为用于捕获的变量:
from enum import Enum
class Color(Enum):
RED = 'red'
GREEN = 'green'
BLUE = 'blue'
color = Color(input("Enter your choice of 'red', 'blue' or 'green': "))
match color:
case Color.RED:
print("I see red!")
case Color.GREEN:
print("Grass is green")
case Color.BLUE:
print("I'm feeling the blues :(")
更详细的说明和更多示例,可参阅以教程格式撰写的 PEP 636。
5.3 Python3 迭代器与生成器
迭代是Python最强大的功能之一,是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。迭代器有两个基本的方法:iter() 和 next()。字符串,列表或元组对象都可用于创建迭代器:
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
print (next(it)) # 输出迭代器的下一个元素
print (next(it))
5.3.1 创建一个迭代器
把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__() 。类都有一个构造函数,Python 的构造函数为 __init__(), 它会在对象初始化的时候执行。
__iter__() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 __next__() 方法并通过 StopIteration 异常标识迭代的完成。
__next__() 方法(Python 2 里是 next())会返回下一个迭代器对象。
创建一个返回数字的迭代器,初始值为 1,逐步递增 1:
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
5.3.2 StopIteration
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 next() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
在 20 次迭代后停止执行:
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
if self.a <= 20:
x = self.a
self.a += 1
return x
else:
raise StopIteration
myclass = MyNumbers()
myiter = iter(myclass)
for x in myiter:
print(x)
5.3.3 生成器
在 Python 中, 就是保存当前程序执行状态。你用 for 循环的时候,每次取一个元素的时候就会计算一次。使用了 yield 的函数被称为生成器(generator)。跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。调用一个生成器函数,返回的是一个迭代器对象。
当有多个返回值时,用 return 全部一起返回了,需要单个逐一返回时可以用 yield。
以下实例使用 yield 实现斐波那契数列:
import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()
六、日期和时间
Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能。Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。时间间隔是以秒为单位的浮点小数。
每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
Python 的 time 模块下有很多函数可以转换常见日期格式。如函数time.time()用于获取当前时间戳,时间戳单位最适于做日期运算。但是1970年之前的日期就无法以此表示了。太遥远的日期也不行,UNIX和Windows只支持到2038年。
6.1 时间元组
| 字段 | 值 |
|---|---|
| 4位数年 | 2008 |
| 月 | 1 到 12 |
| 日 | 1到31 |
| 小时 | 0到23 |
| 分钟 | 0到59 |
| 秒 | 0到61 (60或61 是闰秒) |
| 一周的第几日 | 0到6 (0是周一) |
| 一年的第几日 | 1到366 (儒略历) |
| 夏令时 | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
上述是struct_time元组。这种结构具有如下属性:
| 属性 | 值 |
|---|---|
| tm_year | 2008 |
| tm_mon | 1 到 12 |
| tm_mday | 1 到 31 |
| tm_hour | 0 到 23 |
| tm_min | 0 到 59 |
| tm_sec | 0 到 61 (60或61 是闰秒) |
| tm_wday | 0到6 (0是周一) |
| tm_yday | 1 到 366(儒略历) |
| tm_isdst | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
6.2 获取当前时间
从返回浮点数的时间戳方式向时间元组转换,只要将浮点数传递给如localtime之类的函数。
import time
localtime = time.localtime(time.time())
print ("当前时间:", localtime)
6.3 时间格式化
最简单的获取可读的时间模式的函数是asctime()
import time
localtime = time.localtime(time.time())
print ("当前时间:", time.asctime (localtime))
6.4 日期格式化
使用 time 模块的 strftime 方法来格式化日期
import time
# 格式化成2016-03-20 11:45:39形式
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# 格式化成Sat Mar 28 22:24:24 2016形式
print time.strftime("%a %b %d %H:%M:%S %Y", time.localtime())
# 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2016"
print time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y"))
python中时间日期格式化符号:
| 符号 | 说明 |
|---|---|
| %y | 两位数的年份表示(00-99) |
| %Y | 四位数的年份表示(000-9999) |
| %m | 月份(01-12) |
| %d | 月内中的一天(0-31) |
| %H | 24小时制小时数(0-23) |
| %I | 12小时制小时数(01-12) |
| %M | 分钟数(00=59) |
| %S | 秒(00-59) |
| %a | 本地简化星期名称 |
| %A | 本地完整星期名称 |
| %b | 本地简化的月份名称 |
| %B | 本地完整的月份名称 |
| %c | 本地相应的日期表示和时间表示 |
| %j | 年内的一天(001-366) |
| %p | 本地A.M.或P.M.的等价符 |
| %U | 一年中的星期数(00-53)星期天为星期的开始 |
| %w | 星期(0-6),星期天为星期的开始 |
| %W | 一年中的星期数(00-53)星期一为星期的开始 |
| %x | 本地相应的日期表示 |
| %X | 本地相应的时间表示 |
| %Z | 当前时区的名称 |
| %% | %号本身 |
6.5 日历
Calendar模块有很广泛的方法用来处理年历和月历
import calendar
cal = calendar.month(2016, 1)
print( "以下输出2016年1月份的日历:")
print( cal)
6.6 Time 模块
| 函数 | 描述 |
|---|---|
| time.altzone | 返回格林威治西部的夏令时地区的偏移秒数。如果该地区在格林威治东部会返回负值(如西欧,包括英国)。对夏令时启用地区才能使用。 |
| time.asctime([tupletime]) | 接受时间元组并返回一个可读的形式为"Tue Dec 11 18:07:14 2008"(2008年12月11日 周二18时07分14秒)的24个字符的字符串。 |
| time.clock( ) | 用以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更有用。 |
| time.ctime([secs]) | 作用相当于asctime(localtime(secs)),未给参数相当于asctime() |
| time.gmtime([secs]) | 接收时间戳(1970纪元后经过的浮点秒数)并返回格林威治天文时间下的时间元组t。注:t.tm_isdst始终为0 |
| time.localtime([secs]) | 接收时间戳(1970纪元后经过的浮点秒数)并返回当地时间下的时间元组t(t.tm_isdst可取0或1,取决于当地当时是不是夏令时)。 |
| time.mktime(tupletime) | 接受时间元组并返回时间戳(1970纪元后经过的浮点秒数)。 |
| time.sleep(secs) | 推迟调用线程的运行,secs指秒数。 |
| time.strftime(fmt[,tupletime]) | 接收以时间元组,并返回以可读字符串表示的当地时间,格式由fmt决定。 |
| time.strptime(str,fmt=‘%a %b %d %H:%M:%S %Y’) | 根据fmt的格式把一个时间字符串解析为时间元组。 |
| time.time( ) | 返回当前时间的时间戳(1970纪元后经过的浮点秒数)。 |
| time.time.tzset() | 根据环境变量TZ重新初始化时间相关设置。 |
Time模块包含了以下2个非常重要的属性:
| 属性 | 描述 |
|---|---|
| time.timezone | 属性time.timezone是当地时区(未启动夏令时)距离格林威治的偏移秒数(>0,美洲;<=0大部分欧洲,亚洲,非洲)。 |
| time.tzname | 属性time.tzname包含一对根据情况的不同而不同的字符串,分别是带夏令时的本地时区名称,和不带的。 |
6.7 日历(Calendar)模块
星期一是默认的每周第一天,星期天是默认的最后一天。更改设置需调用calendar.setfirstweekday()函数。模块包含了以下内置函数:
| 函数 | 描述 |
|---|---|
| calendar.calendar(year,w=2,l=1,c=6) | 返回一个多行字符串格式的year年年历,3个月一行,间隔距离为c。 每日宽度间隔为w字符。每行长度为21* W+18+2* C。l是每星期行数。 |
| calendar.firstweekday( ) | 返回当前每周起始日期的设置。默认情况下,首次载入 calendar 模块时返回 0,即星期一。 |
| calendar.isleap(year) | 是闰年返回 True,否则为 False。 import calendar print(calendar.isleap(2000)) True print(calendar.isleap(1900)) False |
| calendar.leapdays(y1,y2) | 返回在Y1,Y2两年之间的闰年总数。 |
| calendar.month(year,month,w=2,l=1) | 返回一个多行字符串格式的year年month月日历,两行标题,一周一行。每日宽度间隔为w字符。每行的长度为7* w+6。l是每星期的行数。 |
| calendar.monthcalendar(year,month) | 返回一个整数的单层嵌套列表。每个子列表装载代表一个星期的整数。Year年month月外的日期都设为0;范围内的日子都由该月第几日表示,从1开始。 |
| calendar.monthrange(year,month) | 返回两个整数。第一个是该月的星期几的日期码,第二个是该月的日期码。日从0(星期一)到6(星期日);月从1到12。 |
| calendar.prcal(year,w=2,l=1,c=6) | 相当于 print calendar.calendar(year,w=2,l=1,c=6)。 |
| calendar.prmonth(year,month,w=2,l=1) | 相当于 print calendar.month(year,month,w=2,l=1) 。 |
| calendar.setfirstweekday(weekday) | 设置每周的起始日期码。0(星期一)到6(星期日)。 |
| calendar.timegm(tupletime) | 和time.gmtime相反:接受一个时间元组形式,返回该时刻的时间戳(1970纪元后经过的浮点秒数)。 |
| calendar.weekday(year,month,day) | 返回给定日期的日期码。0(星期一)到6(星期日)。月份为 1(一月) 到 12(12月)。 |
6.8 其他相关模块和函数
在Python中,其他处理日期和时间的模块还有:
- datetime模块
- pytz模块
- dateutil模块
七、Python 函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
7.1 定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以
def关键词开头,后接函数标识符名称和圆括号()内的形参列表。 - 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。该字符串就是文档字符串,也称为 docstring。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
语法
Python 定义函数使用 def 关键字,一般格式如下:
def 函数名( 参数列表 ):
函数体
默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的。
实例
将一个字符串作为传入参数,再打印到标准显示设备上。
def printStr (str) :
print ("打印这个字符串: ", str)
printStr("你好")
函数在 执行 时使用函数局部变量符号表,所有函数变量赋值都存在局部符号表中;引用变量时,首先,在局部符号表里查找变量,然后,是外层函数局部符号表,再是全局符号表,最后是内置名称符号表。因此,尽管可以引用全局变量和外层函数的变量,但最好不要在函数内直接赋值(除非是 global 语句定义的全局变量,或 nonlocal 语句定义的外层函数变量)。
函数定义在当前符号表中把函数名与函数对象关联在一起。解释器把函数名指向的对象作为用户自定义函数。还可以使用其他名称指向同一个函数对象,并访问访该函数:
>>>fib
<function fib at 10042ed0>
>>>f = fib
>>>f(100)
0 1 1 2 3 5 8 13 21 34 55 89
fib 不返回值,因此,其他语言不把它当作函数,而是当作过程。事实上,没有 return 语句的函数也返回值,只不过这个值比较是 None (是一个内置名称)。一般来说,解释器不会输出单独的返回值 None ,如需查看该值,可以使用 print():
>>>fib(0)
>>>print(fib(0))
None
编写不直接输出斐波那契数列运算结果,而是返回运算结果列表的函数也非常简单:
>>>def fib2(n): # return Fibonacci series up to n
... """Return a list containing the Fibonacci series up to n."""
... result = []
... a, b = 0, 1
... while a < n:
... result.append(a) # see below
... a, b = b, a+b
... return result
...
>>>f100 = fib2(100) # call it
>>>f100 # write the result
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
本例也新引入了一些 Python 功能:
-
return 语句返回函数的值。return 语句不带表达式参数时,返回 None。函数执行完毕退出也返回 None。
-
语句 result.append(a) 调用了列表对象 result 的 方法。 方法是‘从属于’对象的函数,其名称为 obj.methodname,其中 obj
是某个对象(可以是一个表达式),methodname 是由对象的类型定义的方法名称。 不同的类型定义了不同的方法。 不同的类型的方法可以使用相同的名称而不会产生歧义。 (使用 类 可以定义自己的对象类型和方法,参见 类。) 在示例中显示的方法 append() 是由列表对象定义的;它会在列表的末尾添加一个新元素。 在本例中它等同于 result = result + [a],但效率更高。
7.2 函数调用
定义一个函数只给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行。
# 定义函数
def printStr (str) :
print ("打印这个字符串: ", str)
# 调用函数
printStr("你好")
7.3 参数传递
在 python 中,类型属于对象,变量是没有类型的:
a=[1,2,3]
a="我是谁"
以上代码中,[1,2,3] 是 List 类型,“我是谁” 是 String 类型,而变量 a 是没有类型,仅仅是一个对象的引用(一个指针),可以是 List 类型对象,也可以指向 String 类型对象。
在调用函数时会将实际参数(实参)引入到被调用函数的局部符号表中;因此,实参是使用 按值调用 来传递的(其中的 值 始终是对象的 引用 而不是对象的值)。 当一个函数调用另外一个函数时,会为该调用创建一个新的局部符号表。
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
-
不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
-
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
-
不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
-
可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
# 传入不可变类型
def ChangeInt( a ):
a = 10
b = 2
ChangeInt(b)
print( b ) # 结果是 2
# 实例中有 int 对象 2,指向它的变量是 b,在传递给 ChangeInt 函数时,按传值的方式复制了变量 b,a 和 b 都指向了同一个 Int 对象,在 a=10 时,则新生成一个 int 值对象 10,并让 a 指向它。
# 传入可变类型
# 可写函数说明
def changeme( mylist ):
"修改传入的列表"
mylist.append([1,2,3,4])
print ("函数内取值: ", mylist)
return
# 调用changeme函数
mylist = [10,20,30]
changeme( mylist )
print ("函数外取值: ", mylist)
7.4 参数
以下是调用函数时可使用的正式参数类型:
- 必备参数
- 关键字参数
- 默认参数
- 不定长参数
7.4.1. 必备参数
必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。否则,就会报错。
# 定义函数
def printStr (str) :
print ("打印这个字符串: ", str)
# 调用函数
printStr()
调用结果:
Traceback (most recent call last):
File "c:\Users\Python\vscodeProjects\python\pyt\first.py", line 6, in <module>
printStr()
TypeError: printStr() missing 1 required positional argument: 'str'
7.4.2 关键字参数
关键字参数和函数调用关系紧密,函数调用使用 kwarg=value 形式的 关键字参数 来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
以下实例在函数 printStr () 调用时使用参数名:
def parrot(voltage, state='a stiff', action='voom', type='Norwegian Blue'):
print("-- This parrot wouldn't", action, end=' ')
print("if you put", voltage, "volts through it.")
print("-- Lovely plumage, the", type)
print("-- It's", state, "!")
# 该函数接受一个必选参数(voltage)和三个可选参数(state, action 和 type)
parrot(1000) # 1 positional argument
parrot(voltage=1000) # 1 keyword argument
parrot(voltage=1000000, action='VOOOOOM') # 2 keyword arguments
parrot(action='VOOOOOM', voltage=1000000) # 2 keyword arguments
parrot('a million', 'bereft of life', 'jump') # 3 positional arguments
parrot('a thousand', state='pushing up the daisies') # 1 positional, 1 keyword
# 以下调用函数的方式都无效
parrot() # required argument missing
parrot(voltage=5.0, 'dead') # non-keyword argument after a keyword argument
parrot(110, voltage=220) # duplicate value for the same argument
parrot(actor='John Cleese') # unknown keyword argument
函数调用时,关键字参数必须跟在位置参数后面。所有传递的关键字参数都必须匹配一个函数接受的参数(比如,actor 不是函数 parrot 的有效参数),关键字参数的顺序并不重要。这也包括必选参数,(比如,parrot(voltage=1000) 也有效)。不能对同一个参数多次赋值,下面就是一个因此限制而失败的例子:
>>>def function(a):
... pass
...
>>>function(0, a=0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: function() got multiple values for argument 'a'
7.4.3 默认参数
调用函数时,默认参数的值如果没有传入,则被认为是默认值。调用函数时,可以使用比定义时更少的参数,例如:
def ask_ok(prompt, retries=4, reminder='Please try again!'):
while True:
ok = input(prompt)
if ok in ('y', 'ye', 'yes'):
return True
if ok in ('n', 'no', 'nop', 'nope'):
return False
retries = retries - 1
if retries < 0:
raise ValueError('invalid user response')
print(reminder)
该函数可以用以下方式调用:
-
只给出必选实参:ask_ok(‘Do you really want to quit?’)
-
给出一个可选实参:ask_ok(‘OK to overwrite the file?’, 2)
-
给出所有实参:ask_ok(‘OK to overwrite the file?’, 2, ‘Come on, only yes or no!’)
本例还使用了关键字 in ,用于确认序列中是否包含某个值。
默认值在 定义 作用域里的函数定义中求值,所以:
i = 5
def f(arg=i):
print(arg)
i = 6
f()
上例输出的是 5。
重要警告: 默认值只计算一次。默认值为列表、字典或类实例等可变对象时,会产生与该规则不同的结果。例如,下面的函数会累积后续调用时传递的参数:
def f(a, L=[]):
L.append(a)
return L
print(f(1))
print(f(2))
print(f(3))
输出结果如下:
[1]
[1, 2]
[1, 2, 3]
不想在后续调用之间共享默认值时,应以如下方式编写函数:
def f(a, L=None):
if L is None:
L = []
L.append(a)
return L
7.4.4 不定长参数
可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。基本语法如下:
def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]
加了星号(*)的变量名会存放所有未命名的变量参数。*name 形参接收一个 元组,该元组包含形参列表之外的位置参数。不定长参数实例如下:
# 定义函数
def printStr (str, *var) :
"--------------------"
print ("str :" , str)
print ("var : " , var )
printStr("你好", ["世界","Python"])
还有一种就是参数带两个星号 **基本语法如下:
def functionname([formal_args,] **var_args_dict ):
"函数_文档字符串"
function_suite
return [expression]
加了两个星号 ** 的参数会以字典的形式导入。该字典包含与函数中已定义形参对应之外的所有关键字参数。**name 形参可以与 *name 形参(下一小节介绍)组合使用(*name 必须在 **name 前面)。
# 定义函数
def printStr (str, **var) :
"--------------------"
print ("str :" , str)
print ("var : " , var )
printStr("你好", a = "世界",b ="Python")
声明函数时,参数中星号 * 可以单独出现,例如:
def f(a,b,*,c):
return a+b+c
如果单独出现星号 * 后的参数必须用关键字传入。
# 调用函数
f(1,2,c=3)
7.5 特殊参数
默认情况下,参数可以按位置或显式关键字传递给 Python 函数。为了让代码易读、高效,最好限制参数的传递方式,这样,开发者只需查看函数定义,即可确定参数项是仅按位置、按位置或关键字,还是仅按关键字传递。
函数定义如下:
def f(pos1, pos2, /, pos_or_kwd, *, kwd1, kwd2):
----------- ---------- ----------
| | |
| Positional or keyword |
| - Keyword only
-- Positional only
/ 和 * 是可选的。这些符号表明形参如何把参数值传递给函数:位置、位置或关键字、关键字。关键字形参也叫作命名形参。
7.5.1 位置或关键字参数
函数定义中未使用 / 和 * 时,参数可以按位置或关键字传递给函数。
7.5.2 仅位置参数
此处再介绍一些细节,特定形参可以标记为 仅限位置。仅限位置 时,形参的顺序很重要,且这些形参不能用关键字传递。仅限位置形参应放在 / (正斜杠)前。/ 用于在逻辑上分割仅限位置形参与其它形参。如果函数定义中没有 /,则表示没有仅限位置形参。
/ 后可以是 位置或关键字 或 仅限关键字 形参。
7.5.3 仅限关键字参数
把形参标记为 仅限关键字,表明必须以关键字参数形式传递该形参,应在参数列表中第一个 仅限关键字 形参前添加 *。
7.5.4 函数示例
下面的函数定义示例,注意 / 和 * 标记
>>>def standard_arg(arg):
... print(arg)
>>>def pos_only_arg(arg, /):
... print(arg)
>>>def kwd_only_arg(*, arg):
... print(arg)
>>>def combined_example(pos_only, /, standard, *, kwd_only):
... print(pos_only, standard, kwd_only)
第一个函数定义 standard_arg 是最常见的形式,对调用方式没有任何限制,可以按位置也可以按关键字传递参数:
>>>standard_arg(2)
2
>>>standard_arg(arg=2)
2
第二个函数 pos_only_arg 的函数定义中有 /,仅限使用位置形参:
>>>pos_only_arg(1)
1
>>>pos_only_arg(arg=1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: pos_only_arg() got some positional-only arguments passed as keyword arguments: 'arg'
第三个函数 kwd_only_args 的函数定义通过 * 表明仅限关键字参数:
>>>kwd_only_arg(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: kwd_only_arg() takes 0 positional arguments but 1 was given
>>>kwd_only_arg(arg=3)
3
最后一个函数在同一个函数定义中,使用了全部三种调用惯例:
>>>combined_example(1, 2, 3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: combined_example() takes 2 positional arguments but 3 were given
>>>combined_example(1, 2, kwd_only=3)
1 2 3
>>>combined_example(1, standard=2, kwd_only=3)
1 2 3
>>>combined_example(pos_only=1, standard=2, kwd_only=3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: combined_example() got some positional-only arguments passed as keyword arguments: 'pos_only'
下面的函数定义中,kwds 把 name 当作键,因此,可能与位置参数 name 产生潜在冲突:
def foo(name, **kwds):
return 'name' in kwds
调用该函数不可能返回 True,因为关键字 ‘name’ 总与第一个形参绑定。例如:
>>>foo(1, **{'name': 2})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: foo() got multiple values for argument 'name'
加上 / (仅限位置参数)后,就可以了。此时,函数定义把 name 当作位置参数,‘name’ 也可以作为关键字参数的键:
>>>def foo(name, /, **kwds):
... return 'name' in kwds
...
>>>foo(1, **{'name': 2})
True
换句话说,仅限位置形参的名称可以在 **kwds 中使用,而不产生歧义。
7.6 任意实参列表
调用函数时,使用任意数量的实参是最少见的选项。这些实参包含在元组中(详见 元组和序列 )。在可变数量的实参之前,可能有若干个普通参数:
def write_multiple_items(file, separator, *args):
file.write(separator.join(args))
variadic 参数用于采集传递给函数的所有剩余参数,因此,它们通常在形参列表的末尾。*args 形参后的任何形式参数只能是仅限关键字参数,即只能用作关键字参数,不能用作位置参数:
>>>def concat(*args, sep="/"):
... return sep.join(args)
...
>>>concat("earth", "mars", "venus")
'earth/mars/venus'
>>>concat("earth", "mars", "venus", sep=".")
'earth.mars.venus'
7.7 解包实参列表
函数调用要求独立的位置参数,但实参在列表或元组里时,要执行相反的操作。例如,内置的 range() 函数要求独立的 start 和 stop 实参。如果这些参数不是独立的,则要在调用函数时,用 * 操作符把实参从列表或元组解包出来:
>>>list(range(3, 6)) # normal call with separate arguments
[3, 4, 5]
>>>args = [3, 6]
>>>list(range(*args)) # call with arguments unpacked from a list
[3, 4, 5]
同样,字典可以用 ** 操作符传递关键字参数:
>>>def parrot(voltage, state='a stiff', action='voom'):
... print("-- This parrot wouldn't", action, end=' ')
... print("if you put", voltage, "volts through it.", end=' ')
... print("E's", state, "!")
>>>d = {"voltage": "four million", "state": "bleedin' demised", "action": "VOOM"}
>>>parrot(**d)
-- This parrot wouldn't VOOM if you put four million volts through it. E's bleedin' demised !
7.8 匿名函数(Lambda 表达式)
python 使用 lambda 关键字用于创建小巧的匿名函数。lambda a, b: a+b 函数返回两个参数的和。Lambda 函数可用于任何需要函数对象的地方。在语法上,匿名函数只能是单个表达式。在语义上,它只是常规函数定义的语法糖。与嵌套函数定义一样,lambda 函数可以引用包含作用域中的变量。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
实例:
>>>def make_incrementor(n):
... return lambda x: x + n
>>>f = make_incrementor(42)
>>>f(0)
42
>>>f(1)
43
上例用 lambda 表达式返回函数。还可以把匿名函数用作传递的实参:
>>>pairs = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]
>>>pairs.sort(key=lambda pair: pair[1])
>>>pairs
[(4, 'four'), (1, 'one'), (3, 'three'), (2, 'two')]
7.9 文档字符串
以下是文档字符串内容和格式的约定。
第一行应为对象用途的简短摘要。为保持简洁,不要在这里显式说明对象名或类型,因为可通过其他方式获取这些信息(除非该名称碰巧是描述函数操作的动词)。这一行应以大写字母开头,以句点结尾。
文档字符串为多行时,第二行应为空白行,在视觉上将摘要与其余描述分开。后面的行可包含若干段落,描述对象的调用约定、副作用等。
Python 解析器不会删除 Python 中多行字符串字面值的缩进,因此,文档处理工具应在必要时删除缩进。这项操作遵循以下约定:文档字符串第一行 之后 的第一个非空行决定了整个文档字符串的缩进量(第一行通常与字符串开头的引号相邻,其缩进在字符串中并不明显,因此,不能用第一行的缩进),然后,删除字符串中所有行开头处与此缩进“等价”的空白符。不能有比此缩进更少的行,但如果出现了缩进更少的行,应删除这些行的所有前导空白符。转化制表符后(通常为 8 个空格),应测试空白符的等效性。
下面是多行文档字符串的一个例子:
>>>def my_function():
... """Do nothing, but document it.
...
... No, really, it doesn't do anything.
... """
... pass
...
>>>print(my_function.__doc__)
Do nothing, but document it.
No, really, it doesn't do anything.
7.10 函数注解
函数注解 是可选的用户自定义函数类型的元数据完整信息(详见 PEP 3107 和 PEP 484 )。
标注 以字典的形式存放在函数的 annotations 属性中而对函数的其他部分没有影响。 形参标注的定义方式是在形参名后加冒号,后面跟一个会被求值为标注的值的表达式。 返回值标注的定义方式是加组合符号 ->,后面跟一个表达式,这样的校注位于形参列表和表示 def 语句结束的冒号。 下面的示例有一个必须的参数、一个可选的关键字参数以及返回值都带有相应的标注:
>>>def f(ham: str, eggs: str = 'eggs') -> str:
... print("Annotations:", f.__annotations__)
... print("Arguments:", ham, eggs)
... return ham + ' and ' + eggs
...
>>>f('spam')
Annotations: {'ham': <class 'str'>, 'return': <class 'str'>, 'eggs': <class 'str'>}
Arguments: spam eggs
'spam and eggs'
7.11 return 语句
return语句[表达式]退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。之前的例子都没有示范如何返回数值,下例便告诉你怎么做:
# 可写函数说明
def sum( arg1, arg2 ):
# 返回2个参数的和."
total = arg1 + arg2
print ("函数内 : ", total)
return total
# 调用sum函数
total = sum( 10, 20 )
print ("函数外 : ", total)
7.7 变量作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序你可以访问哪个特定的变量名称。两种最基本的变量作用域如下:
- 全局变量
- 局部变量
全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。如下实例:
total = 0 # 这是一个全局变量
# 可写函数说明
def sum( arg1, arg2 ):
#返回2个参数的和."
total = arg1 + arg2 # total在这里是局部变量.
print "函数内是局部变量 : ", total
return total
#调用sum函数
sum( 10, 20 )
print "函数外是全局变量 : ", total
八、Python 3 数据结构
8.1 列表
Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。
以下是 Python 中列表的方法:
| 方法 | 描述 |
|---|---|
| list.append(x) | 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 |
| list.extend(iterable) | 通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = iterable。 |
| list.insert(i, x) | 在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。 |
| list.remove(x) | 删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。 |
| list.pop([i]) | 从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。) |
| list.clear() | 移除列表中的所有项,等于del a[:]。 |
| list.index(x) | 返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。 |
| list.count(x) | 返回 x 在列表中出现的次数。 |
| list.sort() | 对列表中的元素进行排序。 |
| list.reverse() | 倒排列表中的元素。 |
| list.copy() | 返回列表的浅复制,等于a[:]。 |
8.2 将列表当做堆栈使用
列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。
>>>stack = [3, 4, 5]
>>>stack.append(6)
>>>stack.append(7)
>>>stack
[3, 4, 5, 6, 7]
>>>stack.pop()
7
>>>stack
[3, 4, 5, 6]
>>>stack.pop()
6
>>>stack.pop()
5
>>>stack
[3, 4]
8.3 将列表当作队列使用
列表也可以用作队列,最先加入的元素,最先取出(“先进先出”);然而,列表作为队列的效率很低。因为,在列表末尾添加和删除元素非常快,但在列表开头插入或移除元素却很慢(因为所有其他元素都必须移动一位)。
实现队列最好用 collections.deque,可以快速从两端添加或删除元素。例如:
>>>from collections import deque
>>>queue = deque(["Eric", "John", "Michael"])
>>>queue.append("Terry") # Terry arrives
>>>queue.append("Graham") # Graham arrives
>>>queue.popleft() # The first to arrive now leaves
'Eric'
>>>queue.popleft() # The second to arrive now leaves
'John'
>>>queue # Remaining queue in order of arrival
deque(['Michael', 'Terry', 'Graham'])
8.4 列表推导式
列表推导式创建列表的方式更简洁。常见的用法为,对序列或可迭代对象中的每个元素应用某种操作,用生成的结果创建新的列表;或用满足特定条件的元素创建子序列。
例如,创建平方值的列表:
>>>squares = []
>>>for x in range(10):
... squares.append(x**2)
>>>squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
注意,这段代码创建(或覆盖)变量 x,该变量在循环结束后仍然存在。下述方法可以无副作用地计算平方列表:
squares = list(map(lambda x: x**2, range(10)))
# 或等价于:
squares = [x**2 for x in range(10)]
上面这种写法更简洁、易读。
列表推导式的方括号内包含以下内容:一个表达式,后面为一个 for 子句,然后,是零个或多个 for 或 if 子句。结果是由表达式依据 for 和 if 子句求值计算而得出一个新列表。 举例来说,以下列表推导式将两个列表中不相等的元素组合起来:
>>>[(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
# 等价于:
>>>combs = []
>>>for x in [1,2,3]:
... for y in [3,1,4]:
... if x != y:
... combs.append((x, y))
...
>>>combs
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
注意,上面两段代码中,for 和 if 的顺序相同。
表达式是元组(例如上例的 (x, y))时,必须加上括号:
>>>vec = [-4, -2, 0, 2, 4]
>>># create a new list with the values doubled
>>>[x*2 for x in vec]
>>>[-8, -4, 0, 4, 8]
>>># filter the list to exclude negative numbers
>>>[x for x in vec if x >= 0]
>>>[0, 2, 4]
>>># apply a function to all the elements
>>>[abs(x) for x in vec]
>>>[4, 2, 0, 2, 4]
>>># call a method on each element
>>>freshfruit = [' banana', ' loganberry ', 'passion fruit ']
>>>[weapon.strip() for weapon in freshfruit]
>>>['banana', 'loganberry', 'passion fruit']
>>># create a list of 2-tuples like (number, square)
>>>[(x, x**2) for x in range(6)]
>>>[(0, 0), (1, 1), (2, 4), (3, 9), (4, 16), (5, 25)]
>>># the tuple must be parenthesized, otherwise an error is raised
>>>[x, x**2 for x in range(6)]
File "<stdin>", line 1
[x, x**2 for x in range(6)]
^^^^^^^
SyntaxError: did you forget parentheses around the comprehension target?
>>># flatten a list using a listcomp with two 'for'
>>>vec = [[1,2,3], [4,5,6], [7,8,9]]
>>>[num for elem in vec for num in elem]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
列表推导式可以使用复杂的表达式和嵌套函数:
>>>from math import pi
>>>[str(round(pi, i)) for i in range(1, 6)]
['3.1', '3.14', '3.142', '3.1416', '3.14159']
8.5 嵌套的列表推导式
列表推导式中的初始表达式可以是任何表达式,甚至可以是另一个列表推导式。
下面这个 3x4 矩阵,由 3 个长度为 4 的列表组成:
>>>matrix = [
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12],
...]
下面的列表推导式可以转置行列:
>>>[[row[i] for row in matrix] for i in range(4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
如我们在之前小节中看到的,内部的列表推导式是在它之后的 for 的上下文中被求值的,所以这个例子等价于:
>>>transposed = []
>>>for i in range(4):
... transposed.append([row[i] for row in matrix])
...
>>>transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
# 反过来说,也等价于:
>>>transposed = []
>>>for i in range(4):
... # the following 3 lines implement the nested listcomp
... transposed_row = []
... for row in matrix:
... transposed_row.append(row[i])
... transposed.append(transposed_row)
...
>>>transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
实际应用中,最好用内置函数替代复杂的流程语句。此时,zip() 函数更好用:
>>>list(zip(*matrix))
[(1, 5, 9), (2, 6, 10), (3, 7, 11), (4, 8, 12)]
九、模块
python可以用解释器来编程,如果你从 Python 解释器退出再进入,那么你定义的所有的方法和变量就都消失了。为此 Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
模块让你能够有逻辑地组织你的 Python 代码段。
把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
9.1 import 语句
9.1.1 模块的引入
模块定义好后,我们可以使用 import 语句来引入模块,语法如下:
import module1[, module2[,... moduleN]]
比如要引用模块 math,就可以在文件最开始的地方用 import math 来引入。在调用 math 模块中的函数时,必须这样引用:
模块名.函数名
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support.py,需要把命令放在脚本的顶端:
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?
这就涉及到Python的搜索路径,搜索路径是由一系列目录名组成的,Python解释器就依次从这些目录中去寻找所引入的模块。
这看起来很像环境变量,事实上,也可以通过定义环境变量的方式来确定搜索路径。
搜索路径是在Python编译或安装的时候确定的,安装新的库应该也会修改。搜索路径被存储在sys模块中的path变量,做一个简单的实验,在交互式解释器中,输入以下代码:
>>> import sys
>>> sys.path
['', '/usr/lib/python3.4', '/usr/lib/python3.4/plat-x86_64-linux-gnu', '/usr/lib/python3.4/lib-dynload', '/usr/local/lib/python3.4/dist-packages', '/usr/lib/python3/dist-packages']
>>>
sys.path 输出是一个列表,其中第一项是空串’',代表当前目录(若是从一个脚本中打印出来的话,可以更清楚地看出是哪个目录),亦即我们执行python解释器的目录(对于脚本的话就是运行的脚本所在的目录)。
因此若像我一样在当前目录下存在与要引入模块同名的文件,就会把要引入的模块屏蔽掉。
了解了搜索路径的概念,就可以在脚本中修改sys.path来引入一些不在搜索路径中的模块。
现在,在解释器的当前目录或者 sys.path 中的一个目录里面来创建一个fibo.py的文件,代码如下:
# 斐波那契(fibonacci)数列模块
def fib(n): # 定义到 n 的斐波那契数列
a, b = 0, 1
while b < n:
print(b, end=' ')
a, b = b, a+b
print()
def fib2(n): # 返回到 n 的斐波那契数列
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a+b
return result
然后进入Python解释器,使用下面的命令导入这个模块:
>>> import fibo
这样做并没有把直接定义在fibo中的函数名称写入到当前符号表里,只是把模块fibo的名字写到了那里。
可以使用模块名称来访问函数:
实例
>>>fibo.fib(1000)
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
>>> fibo.fib2(100)
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
>>> fibo.__name__
'fibo'
如果你打算经常使用一个函数,你可以把它赋给一个本地的名称:
>>> fib = fibo.fib
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
模块名后使用 as 时,直接把 as 后的名称与导入模块绑定。
>>>import fibo as fib
>>>fib.fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
与 import fibo 一样,这种方式也可以有效地导入模块,唯一的区别是,导入的名称是 fib。
9.1.2 from…import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中。语法如下:
from modname import name1[, name2[, ... nameN]]
例如,要导入模块 fib 的 fibonacci 函数,使用如下语句:
from fib import fibonacci
这个声明不会把整个 fib 模块导入到当前的命名空间中,它只会将 fib 里的 fibonacci 单个引入到执行这个声明的模块的全局符号表。
9.1.3 from…import* 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
例如我们想一次性引入 math 模块中所有的东西,语句如下:
from math import *
from 中也可以使用as这种方式,效果类似:
>>>from fibo import fib as fibonacci
>>>fibonacci(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
备注: 为了保证运行效率,每次解释器会话只导入一次模块。如果更改了模块内容,必须重启解释器;仅交互测试一个模块时,也可以使用 importlib.reload(),例如 import importlib; importlib.reload(modulename)。
9.2 深入模块
模块除了方法定义,还可以包括可执行的代码。这些代码一般用来初始化这个模块。这些代码只有在第一次被导入时才会被执行。
每个模块有各自独立的符号表,在模块内部为所有的函数当作全局符号表来使用。
所以,模块的作者可以放心大胆的在模块内部使用这些全局变量,而不用担心把其他用户的全局变量搞混。
从另一个方面,当你确实知道你在做什么的话,你也可以通过 modname.itemname 这样的表示法来访问模块内的函数。
模块是可以导入其他模块的。在一个模块(或者脚本,或者其他地方)的最前面使用 import 来导入一个模块,当然这只是一个惯例,而不是强制的。被导入的模块的名称将被放入当前操作的模块的符号表中。
还有一种导入的方法,可以使用 import 直接把模块内(函数,变量的)名称导入到当前操作模块。比如:
>>> from fibo import fib, fib2
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
这种导入的方法不会把被导入的模块的名称放在当前的字符表中(所以在这个例子里面,fibo 这个名称是没有定义的)。
这还有一种方法,可以一次性的把模块中的所有(函数,变量)名称都导入到当前模块的字符表:
>>> from fibo import *
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
这将把所有的名字都导入进来,但是那些由单一下划线(_)开头的名字不在此例。大多数情况, Python程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。
9.3 全局变量 __name__属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
# Filename: using_name.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')
运行输出如下:
$ python using_name.py
程序自身在运行
$ python
>>> import using_name
我来自另一模块
>>>
说明: 每个模块都有一个__name__属性,当其值是’__main__'时,表明该模块自身在运行,否则是被引入。
说明:__name__ 与 __main__ 底下是双下划线, _ _ 是这样去掉中间的那个空格。
9.4 搜索路径
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
9.5 PYTHONPATH 变量
作为环境变量,PYTHONPATH 由装在一个列表里的许多目录组成。PYTHONPATH 的语法和 shell 变量 PATH 的一样。
在 Windows 系统,典型的 PYTHONPATH 如下:
set PYTHONPATH=c:\python27\lib;
在 UNIX 系统,典型的 PYTHONPATH 如下:
set PYTHONPATH=/usr/local/lib/python
9.6 命名空间和作用域
9.6.1 命名空间
变量是拥有匹配对象的名字(标识符)。命名空间是一个包含了变量名称们(键)和它们各自相应的对象们(值)的字典。
一个 Python 表达式可以访问局部命名空间和全局命名空间里的变量。如果一个局部变量和一个全局变量重名,则局部变量会覆盖全局变量。
命名空间提供了在项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何关系的,所以一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响。
每个函数都有自己的命名空间。类的方法的作用域规则和通常函数的一样。
Python 会智能地猜测一个变量是局部的还是全局的,它假设任何在函数内赋值的变量都是局部的。
因此,如果要给函数内的全局变量赋值,必须使用 global 语句。
global VarName 的表达式会告诉 Python, VarName 是一个全局变量,这样 Python 就不会在局部命名空间里寻找这个变量了。
一般有三种命名空间:
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
命名空间查找顺序: 要使用变量,Python 的查找顺序为:局部的命名空间去 -> 全局命名空间 -> 内置命名空间。 如果找不到变量 。它将放弃查找并引发一个 NameError 异常:
NameError: name 'runoob' is not defined。
命名空间的生命周期:
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。
因此,我们无法从外部命名空间访问内部命名空间的对象。
9.6.2 作用域
作用域就是一个 Python 程序可以直接访问命名空间的正文区域。
在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python的作用域一共有4种,分别是:
- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等。,最后被搜索
规则顺序: L –> E –> G –>gt; B。
在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。
g_count = 0 # 全局作用域
def outer():
o_count = 1 # 闭包函数外的函数中
def inner():
i_count = 2 # 局部作用域
内置作用域是通过一个名为 builtin 的标准模块来实现的,但是这个变量名自身并没有放入内置作用域内,所以必须导入这个文件才能够使用它。在Python3.0中,可以使用以下的代码来查看到底预定义了哪些变量:
>>> import builtins
>>> dir(builtins)
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问,如下代码:
>>> if True:
... msg = 'I am from Runoob'
...
>>> msg
'I am from Runoob'
>>>
实例中 msg 变量定义在 if 语句块中,但外部还是可以访问的。
如果将 msg 定义在函数中,则它就是局部变量,外部不能访问:
>>> def test():
... msg_inner = 'I am from Runoob'
...
>>> msg_inner
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'msg_inner' is not defined
>>>
从报错的信息上看,说明了 msg_inner 未定义,无法使用,因为它是局部变量,只有在函数内可以使用。
9.6.3 全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。如下实例:
实例(Python 3.0+)
total = 0 # 这是一个全局变量
# 可写函数说明
def sum( arg1, arg2 ):
#返回2个参数的和."
total = arg1 + arg2 # total在这里是局部变量.
print ("函数内是局部变量 : ", total)
return total
#调用sum函数
sum( 10, 20 )
print ("函数外是全局变量 : ", total)
以上实例输出结果:
函数内是局部变量 : 30
函数外是全局变量 : 0
9.6.4 global 和 nonlocal关键字
当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal关键字了。
以下实例修改全局变量 num:
实例(Python 3.0+)
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)
以上实例输出结果:
1
123
123
如果要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字了,如下实例:
实例(Python 3.0+)
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
以上实例输出结果:
100
100
另外有一种特殊情况,假设下面这段代码被运行:
实例(Python 3.0+)
a = 10
def test():
a = a + 1
print(a)
test()
以上程序执行,报错信息如下:
Traceback (most recent call last):
File "test.py", line 7, in <module>
test()
File "test.py", line 5, in test
a = a + 1
UnboundLocalError: local variable 'a' referenced before assignment
错误信息为局部作用域引用错误,因为 test 函数中的 a 使用的是局部,未定义,无法修改。
修改 a 为全局变量,通过函数参数传递,可以正常执行输出结果为:
实例(Python 3.0+)
a = 10
def test(a):
a = a + 1
print(a)
test(a)
执行输出结果为:
11
9.7 dir()函数
dir() 函数一个排好序的字符串列表,内容是一个模块里定义过的名字。
返回的列表容纳了在一个模块里定义的所有模块,变量和函数。如果没有给定参数,那么 dir() 函数会罗列出当前定义的所有名称
如下一个简单的实例:
# -*- coding: UTF-8 -*-
# 导入内置math模块
import math
content = dir(math)
print content;
以上实例输出结果:
['__doc__', '__file__', '__name__', 'acos', 'asin', 'atan',
'atan2', 'ceil', 'cos', 'cosh', 'degrees', 'e', 'exp',
'fabs', 'floor', 'fmod', 'frexp', 'hypot', 'ldexp', 'log',
'log10', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh',
'sqrt', 'tan', 'tanh']
在这里,特殊字符串变量__name__指向模块的名字,__file__指向该模块的导入文件名。
如果没有给定参数,那么 dir() 函数会罗列出当前定义的所有名称:
9.8 globals() 和 locals() 函数
根据调用地方的不同,globals() 和 locals() 函数可被用来返回全局和局部命名空间里的名字。
如果在函数内部调用 locals(),返回的是所有能在该函数里访问的命名。
如果在函数内部调用 globals(),返回的是所有在该函数里能访问的全局名字。
两个函数的返回类型都是字典。所以名字们能用 keys() 函数摘取。
9.9 reload() 函数
当一个模块被导入到一个脚本,模块顶层部分的代码只会被执行一次。
因此,如果你想重新执行模块里顶层部分的代码,可以用 reload() 函数。该函数会重新导入之前导入过的模块。语法如下:
reload(module_name)
在这里,module_name要直接放模块的名字,而不是一个字符串形式。比如想重载 hello 模块,如下:
reload(hello)
9.10 标准模块
Python 本身带着一些标准的模块库,在 Python 库参考文档中将会介绍到(就是后面的"库参考文档")。
有些模块直接被构建在解析器里,这些虽然不是一些语言内置的功能,但是他却能很高效的使用,甚至是系统级调用也没问题。
这些组件会根据不同的操作系统进行不同形式的配置,比如 winreg 这个模块就只会提供给 Windows 系统。
应该注意到这有一个特别的模块 sys ,它内置在每一个 Python 解析器中。变量 sys.ps1 和 sys.ps2 定义了主提示符和副提示符所对应的字符串:
>>> import sys
>>> sys.ps1
'>>> '
>>> sys.ps2
'... '
>>> sys.ps1 = 'C> '
C> print('Runoob!')
Runoob!
C>
9.11 Python中的包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
简单来说,包就是文件夹,但该文件夹下必须存在 __init__.py 文件, 该文件的内容可以为空。 __init__.py 用于标识当前文件夹是一个包。
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。
比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
最简单的情况,放一个空的 :file:__init__.py就可以了。当然这个文件中也可以包含一些初始化代码或者为(将在后面介绍的) __all__变量赋值。
用户可以每次只导入一个包里面的特定模块,比如:
import sound.effects.echo
这将会导入子模块:sound.effects.echo。 他必须使用全名去访问:
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
还有一种导入子模块的方法是:
from sound.effects import echo
这同样会导入子模块: echo,并且他不需要那些冗长的前缀,所以他可以这样使用:
echo.echofilter(input, output, delay=0.7, atten=4)
还有一种变化就是直接导入一个函数或者变量:
from sound.effects.echo import echofilter
同样的,这种方法会导入子模块: echo,并且可以直接使用他的 echofilter() 函数:
echofilter(input, output, delay=0.7, atten=4)
注意当使用from package import item这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import 语法会首先把item当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,抛出一个 :exc:ImportError 异常。
反之,如果使用形如 import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
9.12 从一个包中导入*
设想一下,如果我们使用 from sound.effects import *会发生什么?
Python 会进入文件系统,找到这个包里面所有的子模块,一个一个的把它们都导入进来。
但是很不幸,这个方法在 Windows平台上工作的就不是非常好,因为Windows是一个大小写不区分的系统。
在这类平台上,没有人敢担保一个叫做 ECHO.py 的文件导入为模块 echo 还是 Echo 甚至 ECHO。
(例如,Windows 95就很讨厌的把每一个文件的首字母大写显示)而且 DOS 的 8+3 命名规则对长模块名称的处理会把问题搞得更纠结。
为了解决这个问题,只能烦劳包作者提供一个精确的包的索引了。
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 __all__ 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
作为包的作者,可别忘了在更新包之后保证 __all__ 也更新了啊。你说我就不这么做,我就不使用导入*这种用法,好吧,没问题,谁让你是老板呢。这里有一个例子,在:file:sounds/effects/ __init__.py中包含如下代码:
\_\_all__ = ["echo", "surround", "reverse"]
这表示当你使用from sound.effects import *这种用法时,你只会导入包里面这三个子模块。
如果 __all__ 真的没有定义,那么使用from sound.effects import *这种语法的时候,就不会导入包 sound.effects 里的任何子模块。他只是把包sound.effects和它里面定义的所有内容导入进来(可能运行 __init__.py里定义的初始化代码)。
这会把 __init__.py 里面定义的所有名字导入进来。并且他不会破坏掉我们在这句话之前导入的所有明确指定的模块。看下这部分代码:
import sound.effects.echo
import sound.effects.surround
from sound.effects import *
这个例子中,在执行 from…import 前,包 sound.effects 中的 echo 和 surround 模块都被导入到当前的命名空间中了。(当然如果定义了 __all__ 就更没问题了)
通常我们并不主张使用 * 这种方法来导入模块,因为这种方法经常会导致代码的可读性降低。不过这样倒的确是可以省去不少敲键的功夫,而且一些模块都设计成了只能通过特定的方法导入。
记住,使用 from Package import specific_submodule 这种方法永远不会有错。事实上,这也是推荐的方法。除非是你要导入的子模块有可能和其他包的子模块重名。
相对导入:
如果在结构中包是一个子包(比如这个例子中对于包sound来说),而你又想导入兄弟包(同级别的包)你就得使用导入绝对的路径来导入。比如,如果模块sound.filters.vocoder 要使用包 sound.effects 中的模块 echo,你就要写成 from sound.effects import echo。
from . import echo
from .. import formats
from ..filters import equalizer
无论是隐式的还是显式的相对导入都是从当前模块开始的。主模块的名字永远是" __main__",一个Python应用程序的主模块,应当总是使用绝对路径引用。
多目录中的包:
包还提供一个额外的属性 __path__。这是一个目录列表,里面每一个包含的目录都有为这个包服务的 __init__.py,你得在其他 __init__.py被执行前定义哦。可以修改这个变量,用来影响包含在包里面的模块和子包。
这个功能并不常用,一般用来扩展包里面的模块。
十、 Python 输入和输出
10.1 print 输出
最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式。此函数把你传递的表达式转换成一个字符串表达式,并将结果写到标准输出如下:
print "Python 是一个非常棒的语言,不是吗?"
但在python3中,不再支持这种写法,而是支持使用 print ("")
标准输出文件可以用 sys.stdout 引用。
如果你希望输出的形式更加多样,可以使用 str.format() 函数来格式化输出值。
如果你希望将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现。
s = 'Hello, Runoob'
print(str(s))
print(repr(s))
print(str(1/7))
x = 10 * 3.25
y = 200 * 200
s = 'x 的值为: ' + repr(x) + ', y 的值为:' + repr(y) + '...'
print(s)
# repr() 函数可以转义字符串中的特殊字符
hello = 'hello, runoob\n'
hellos = repr(hello)
print(hellos)
# repr() 的参数可以是 Python 的任何对象
print(repr((x, y, ('Google', 'Runoob'))))
for x in range(1, 11):
print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ') # rjust它可以将字符串靠右, 并在左边填充空格。
# 注意前一行 'end' 的使用
print(repr(x*x*x).rjust(4))
for x in range(1, 11):
print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
# zfill(), 它会在数字的左边填充 0
'12'.zfill(5)
str.format() 的基本使用如下:
print('{}网址: "{}!"'.format('菜鸟教程', 'www.runoob.com'))
# 打印结果为:菜鸟教程网址: "www.runoob.com!"
# 括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换。
# 在括号中的数字用于指向传入对象在 format() 中的位置,如下所示:
print('{1} 和 {0}'.format('Google', 'Runoob'))
# 打印结果为: Runoob 和 Google
如果在 format() 中使用了关键字参数, 那么它们的值会指向使用该名字的参数。
!a (使用 ascii()), !s (使用 str()) 和 !r (使用 repr()) 可以用于在格式化某个值之前对其进行转化
可选项 : 和格式标识符可以跟着字段名。 这就允许对值进行更好的格式化。
在 : 后传入一个整数, 可以保证该域至少有这么多的宽度。 用于美化表格时很有用。
旧式字符串格式化
% 操作符也可以实现字符串格式化。 它将左边的参数作为类似 sprintf() 式的格式化字符串, 而将右边的代入, 然后返回格式化后的字符串. 例如:
import math
print('常量 PI 的值近似为:%5.3f。' % math.pi)
# 常量 PI 的值近似为:3.142。
10.2 键盘输入
Python提供了两个内置函数从标准输入读入一行文本,默认的标准输入是键盘。如下:
- raw_input([prompt]) 函数从标准输入读取一个行,并返回一个字符串(去掉结尾的换行符)
- input([prompt]) 函数和 raw_input([prompt]) 函数基本类似,但是 input 可以接收一个Python表达式作为输入,并将运算结果返回。
raw_input函数
str = raw_input("请输入:")
input函数
str = input("请输入:")
10.3 操作文件
Python 提供了必要的函数和方法进行默认情况下的文件基本操作。你可以用 file 对象做大部分的文件操作。
10.3.1 open 函数
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
语法:
file object = open(file[, mode][, buffering])
或
open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener:
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
这几种模式:
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
10.3.2 File对象的属性
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
方法
| 方法 | 描述 |
|---|---|
| file.close() | 关闭文件。关闭后文件不能再进行读写操作。 |
| file.flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| file.fileno() | 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty() | 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| file.next() | Python 3 中的 File 对象不支持 next() 方法。返回文件下一行。 |
| file.read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| file.readline([size]) | 读取整行,包括 “\n” 字符。 |
| file.readlines([sizeint]) | 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| file.seek(offset[, whence]) | 移动文件读取指针到指定位置 |
| file.tell() | 返回文件当前位置。 |
| file.truncate([size]) | 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。 |
| file.write(str) | 将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
以下是和file对象相关的所有属性的列表:
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
| file.softspace | 如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 |
# 打开一个文件
fo = open("foo.txt", "w")
print ("文件名: ", fo.name)
print ("是否已关闭 : ", fo.closed)
print ("访问模式 : ", fo.mode)
print ("末尾是否强制加空格 : ", fo.softspace)
10.3.2.1 close()方法
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
语法:
fileObject.close()
10.3.2.2 write()方法
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符(‘\n’):
语法:
fileObject.write(string)
10.3.2.3 read()方法
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
fileObject.read([count])
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
10.3.2.4 f.readline()
f.readline() 会从文件中读取单独的一行。换行符为 ‘\n’。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
str = f.readline()
10.3.2.5 f.readlines()
f.readlines() 将返回该文件中包含的所有行。
如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
10.3.3 文件定位
tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from]) 方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。
如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
例子:
就用我们上面创建的文件foo.txt。
# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print ("读取的字符串是 : ", str)
# 查找当前位置
position = fo.tell()
print ("当前文件位置 : ", position)
# 把指针再次重新定位到文件开头
position = fo.seek(0, 0)
str = fo.read(10)
print ("重新读取字符串 : ", str)
# 关闭打开的文件
fo.close()
10.3.4 重命名和删除文件
Python的os模块提供了帮你执行文件处理操作的方法,比如重命名和删除文件。
要使用这个模块,你必须先导入它,然后才可以调用相关的各种功能。
10.3.4.1 重命名
rename()方法需要两个参数,当前的文件名和新文件名。
语法:
os.rename(current_file_name, new_file_name)
10.3.4.2 remove()方法
你可以用remove()方法删除文件,需要提供要删除的文件名作为参数。
语法:
os.remove(file_name)
10.3.5 Python里的目录:
所有文件都包含在各个不同的目录下,不过Python也能轻松处理。os模块有许多方法能帮你创建,删除和更改目录。
10.3.5.1 mkdir()方法
可以使用os模块的mkdir()方法在当前目录下创建新的目录们。你需要提供一个包含了要创建的目录名称的参数。
语法:
os.mkdir("newdir")
例子:
下例将在当前目录下创建一个新目录test。
import os
# 创建目录test
os.mkdir("test")
10.3.5.2 chdir()方法
可以用chdir()方法来改变当前的目录。chdir()方法需要的一个参数是你想设成当前目录的目录名称。
语法:
os.chdir("newdir")
例子:
import os
# 将当前目录改为"/home/newdir"
os.chdir("/home/newdir")
10.3.5.3 getcwd()方法:
getcwd()方法显示当前的工作目录。
语法:
os.getcwd()
例子:
下例给出当前目录:
import os
# 给出当前的目录
print os.getcwd()
10.3.5.4 rmdir()方法
rmdir()方法删除目录,目录名称以参数传递。
在删除这个目录之前,它的所有内容应该先被清除。
语法:
os.rmdir('dirname')
例子:
以下是删除" /tmp/test"目录的例子。目录的完全合规的名称必须被给出,否则会在当前目录下搜索该目录。
import os
# 删除”/tmp/test”目录
os.rmdir( "/tmp/test" )
10.4 pickle 模块
python的pickle模块实现了基本的数据序列和反序列化。
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储。
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
基本接口:
pickle.dump(obj, file, [,protocol])
有了 pickle 这个对象, 就能对 file 以读取的形式打开:
x = pickle.load(file)
注解:从 file 中读取一个字符串,并将它重构为原来的python对象。
file: 类文件对象,有read()和readline()接口。
实例 1
import pickle
# 使用pickle模块将数据对象保存到文件
data1 = {'a': [1, 2.0, 3, 4+6j],
'b': ('string', u'Unicode string'),
'c': None}
selfref_list = [1, 2, 3]
selfref_list.append(selfref_list)
output = open('data.pkl', 'wb')
# Pickle dictionary using protocol 0.
pickle.dump(data1, output)
# Pickle the list using the highest protocol available.
pickle.dump(selfref_list, output, -1)
output.close()
实例 2
import pprint, pickle
#使用pickle模块从文件中重构python对象
pkl_file = open('data.pkl', 'rb')
data1 = pickle.load(pkl_file)
pprint.pprint(data1)
data2 = pickle.load(pkl_file)
pprint.pprint(data2)
pkl_file.close()
10.5 文件、目录相关的方法
File 对象和 OS 对象提供了很多文件与目录的操作方法,可以通过点击下面链接查看详情:
- File 对象方法: file 对象提供了操作文件的一系列方法。
- OS 对象方法: 提供了处理文件及目录的一系列方法。
十一、Python OS 文件/目录方法
os 模块提供了非常丰富的方法用来处理文件和目录。常用的方法如下表所示:
| 方法 | 描述 |
|---|---|
| os.access(path, mode) | 检验权限模式 |
| os.chdir(path) | 改变当前工作目录 |
| os.chflags(path, flags) | 设置路径的标记为数字标记。 |
| os.chmod(path, mode) | 更改权限 |
| os.chown(path, uid, gid) | 更改文件所有者 |
| os.chroot(path) | 改变当前进程的根目录 |
| os.close(fd) | 关闭文件描述符 fd |
| os.closerange(fd_low, fd_high) | 关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略 |
| os.dup(fd) | 复制文件描述符 fd |
| os.dup2(fd, fd2) | 将一个文件描述符 fd 复制到另一个 fd2 |
| os.fchdir(fd) | 通过文件描述符改变当前工作目录 |
| os.fchmod(fd, mode) | 改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。 |
| os.fchown(fd, uid, gid) | 修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。 |
| os.fdatasync(fd) | 强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。 |
| os.fdopen(fd[, mode[, bufsize]]) | 通过文件描述符 fd 创建一个文件对象,并返回这个文件对象 |
| os.fpathconf(fd, name) | 返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。 |
| os.fstat(fd) | 返回文件描述符fd的状态,像stat()。 |
| os.fstatvfs(fd) | 返回包含文件描述符fd的文件的文件系统的信息,像 statvfs() |
| os.fsync(fd) | 强制将文件描述符为fd的文件写入硬盘。 |
| os.ftruncate(fd, length) | 裁剪文件描述符fd对应的文件, 所以它最大不能超过文件大小。 |
| os.getcwd() | 返回当前工作目录 |
| os.getcwdu() | 返回一个当前工作目录的Unicode对象 |
| os.isatty(fd) | 如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true, 否则False。 |
| os.lchflags(path, flags) | 设置路径的标记为数字标记,类似 chflags(),但是没有软链接 |
| os.lchmod(path, mode) | 修改连接文件权限 |
| os.lchown(path, uid, gid) | 更改文件所有者,类似 chown,但是不追踪链接。 |
| os.link(src, dst) | 创建硬链接,名为参数 dst,指向参数 src |
| os.listdir(path) | 返回path指定的文件夹包含的文件或文件夹的名字的列表。 |
| os.lseek(fd, pos, how) | 设置文件描述符 fd当前位置为pos, how方式修改: SEEK_SET 或者 0 设置从文件开始的计算的pos; SEEK_CUR或者 1 则从当前位置计算; os.SEEK_END或者2则从文件尾部开始. 在unix,Windows中有效 |
| os.lstat(path) | 像stat(),但是没有软链接 |
| os.major(device) | 从原始的设备号中提取设备major号码 (使用stat中的st_dev或者st_rdev field)。 |
| os.makedev(major, minor) | 以major和minor设备号组成一个原始设备号 |
| os.makedirs(path[, mode]) | 递归文件夹创建函数。像mkdir(), 但创建的所有intermediate-level文件夹需要包含子文件夹。 |
| os.minor(device) | 从原始的设备号中提取设备minor号码 (使用stat中的st_dev或者st_rdev field )。 |
| os.mkdir(path[, mode]) | 以数字mode的mode创建一个名为path的文件夹.默认的 mode 是 0777 (八进制)。 |
| os.mkfifo(path[, mode]) | 创建命名管道,mode 为数字,默认为 0666 (八进制) |
| os.mknod(filename[, mode=0600, device]) | 创建一个名为filename文件系统节点(文件,设备特别文件或者命名pipe)。 |
| os.open(file, flags[, mode]) | 打开一个文件,并且设置需要的打开选项,mode参数是可选的 |
| os.openpty() | 打开一个新的伪终端对。返回 pty 和 tty的文件描述符。 |
| os.pathconf(path, name) | 返回相关文件的系统配置信息。 |
| os.pipe() | 创建一个管道. 返回一对文件描述符(r, w) 分别为读和写 |
| os.popen(command[, mode[, bufsize]]) | 从一个 command 打开一个管道 |
| os.read(fd, n) | 从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。 |
| os.readlink(path) | 返回软链接所指向的文件 |
| os.remove(path) | 删除路径为path的文件。如果path 是一个文件夹,将抛出OSError; 查看下面的rmdir()删除一个 directory。 |
| os.removedirs(path) | 递归删除目录。 |
| os.rename(src, dst) | 重命名文件或目录,从 src 到 dst |
| os.renames(old, new) | 递归地对目录进行更名,也可以对文件进行更名。 |
| os.rmdir(path) | 删除path指定的空目录,如果目录非空,则抛出一个OSError异常。 |
| os.stat(path) | 获取path指定的路径的信息,功能等同于C API中的stat()系统调用。 |
| os.stat_float_times([newvalue]) | 决定stat_result是否以float对象显示时间戳 |
| os.statvfs(path) | 获取指定路径的文件系统统计信息 |
| os.symlink(src, dst) | 创建一个软链接 |
| os.tcgetpgrp(fd) | |
| os.tcsetpgrp(fd, pg) | 设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg。 |
| os.tempnam([dir[, prefix]]) | 返回唯一的路径名用于创建临时文件。 |
| os.tmpfile() | 返回一个打开的模式为(w+b)的文件对象 .这文件对象没有文件夹入口,没有文件描述符,将会自动删除。 |
| os.tmpnam() | 为创建一个临时文件返回一个唯一的路径 |
| os.ttyname(fd) | 返回一个字符串,它表示与文件描述符fd 关联的终端设备。如果fd 没有与终端设备关联,则引发一个异常。 |
| os.unlink(path) | |
| os.utime(path, times) | 返回指定的path文件的访问和修改的时间。 |
| os.walk(top[, topdown=True[, οnerrοr=None[, followlinks=False]]]) | 输出在文件夹中的文件名通过在树中游走,向上或者向下。 |
| os.write(fd, str) | 写入字符串到文件描述符 fd中. 返回实际写入的字符串长度 |
| os.path 模块 | 获取文件的属性信息。 |
十二、Python 异常处理
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。一般情况下,在Python无法正常处理程序时就会发生一个异常。异常是Python对象,表示一个错误。
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
python提供了两个非常重要的功能来处理python程序在运行中出现的异常和错误。你可以使用该功能来调试python程序。
- 异常处理: 本站Python教程会具体介绍。
- 断言(Assertions):本站Python教程会具体介绍。
12.1 python标准异常
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
12.2 异常处理
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
语法:
以下为简单的try…except…else的语法:
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生
try的工作原理是,当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
- 如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
- 如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
- 如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
12.3 使用except而不带任何异常类型
你可以不带任何异常类型使用except,如下实例:
try:
正常的操作
......................
except:
发生异常,执行这块代码
......................
else:
如果没有异常执行这块代码
以上方式try-except语句捕获所有发生的异常。但这不是一个很好的方式,我们不能通过该程序识别出具体的异常信息。因为它捕获所有的异常。
12.4 使用except而带多种异常类型
你也可以使用相同的except语句来处理多个异常信息,如下所示:
try:
正常的操作
......................
except(Exception1[, Exception2[,...ExceptionN]]]):
发生以上多个异常中的一个,执行这块代码
......................
else:
如果没有异常执行这块代码
12.5 try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
try:
<语句>
finally:
<语句> #退出try时总会执行
raise
当在try块中抛出一个异常,立即执行finally块代码。finally块中的所有语句执行后,异常被再次触发,并执行except块代码。参数的内容不同于异常。
12.6 异常的参数
一个异常可以带上参数,可作为输出的异常信息参数。
你可以通过except语句来捕获异常的参数,如下所示:
try:
正常的操作
......................
except ExceptionType, Argument:
你可以在这输出 Argument 的值...
变量接收的异常值通常包含在异常的语句中。在元组的表单中变量可以接收一个或者多个值。
元组通常包含错误字符串,错误数字,错误位置。
12.7 触发异常
我们可以使用raise语句自己触发异常
raise语法格式如下:
raise [Exception [, args [, traceback]]]
语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,args 是自已提供的异常参数。
最后一个参数是可选的(在实践中很少使用),如果存在,是跟踪异常对象。
12.8 用户自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
以下为与RuntimeError相关的实例,实例中创建了一个类,基类为RuntimeError,用于在异常触发时输出更多的信息。
在try语句块中,用户自定义的异常后执行except块语句,变量 e 是用于创建Networkerror类的实例。
class Networkerror(RuntimeError):
def __init__(self, arg):
self.args = arg
在你定义以上类后,你可以触发该异常,如下所示:
try:
raise Networkerror("Bad hostname")
except Networkerror,e:
print e.args
12.9 预定义的清理行为
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行。
这面这个例子展示了尝试打开一个文件,然后把内容打印到屏幕上:
for line in open("myfile.txt"):
print(line, end="")
以上这段代码的问题是,当执行完毕后,文件会保持打开状态,并没有被关闭。
关键词 with 语句就可以保证诸如文件之类的对象在使用完之后一定会正确的执行他的清理方法:
with open("myfile.txt") as f:
for line in f:
print(line, end="")
以上这段代码执行完毕后,就算在处理过程中出问题了,文件 f 总是会关闭。
十三、面向对象
python 是一门面向对象的语言。
13.1 面向对象技术简介
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
数据成员:类变量或者实例变量, 用于处理类及其实例对象的相关的数据。
方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
局部变量:定义在方法中的变量,只作用于当前实例的类。
实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
实例化:创建一个类的实例,类的具体对象。
方法:类中定义的函数。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
Python中的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。
13.2 定义类
语法格式如下:
class ClassName:
<statement-1>
.
.
.
<statement-N>
实例:
class Employee:
'所有员工的基类'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
13.3 实例化对象
类对象支持两种操作:属性引用和实例化。
属性引用使用和 Python 中所有的属性引用一样的标准语法:obj.name。
类对象创建后,类命名空间中所有的命名都是有效属性名。所以如果类定义是这样:
class MyClass:
"""一个简单的类实例"""
i = 12345
def f(self):
return 'hello world'
# 实例化类
x = MyClass()
# 访问类的属性和方法
print("MyClass 类的属性 i 为:", x.i)
print("MyClass 类的方法 f 输出为:", x.f())
类有一个名为 __init__() 的特殊方法(构造方法),该方法在类实例化时会自动调用。当然,__init__() 方法可以有参数,参数通过 __init__() 传递到类的实例化操作上。
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
13.4 Python内置类属性
__dict__ : 类的属性(包含一个字典,由类的数据属性组成)
__doc__ :类的文档字符串
__name__: 类名
__module__: 类定义所在的模块(类的全名是’__main__.className’,如果类位于一个导入模块mymod中,那么className.__module__ 等于 mymod)
__bases__ : 类的所有父类构成元素(包含了一个由所有父类组成的元组)
13.5 python对象销毁(垃圾回收)
Python 使用了引用计数这一简单技术来跟踪和回收垃圾。
在 Python 内部记录着所有使用中的对象各有多少引用。
一个内部跟踪变量,称为一个引用计数器。
当对象被创建时, 就创建了一个引用计数, 当这个对象不再需要时, 也就是说, 这个对象的引用计数变为0 时, 它被垃圾回收。但是回收不是"立即"的, 由解释器在适当的时机,将垃圾对象占用的内存空间回收。
垃圾回收机制不仅针对引用计数为0的对象,同样也可以处理循环引用的情况。循环引用指的是,两个对象相互引用,但是没有其他变量引用他们。这种情况下,仅使用引用计数是不够的。Python 的垃圾收集器实际上是一个引用计数器和一个循环垃圾收集器。作为引用计数的补充, 垃圾收集器也会留心被分配的总量很大(及未通过引用计数销毁的那些)的对象。 在这种情况下, 解释器会暂停下来, 试图清理所有未引用的循环。
13.6 类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self, 且为第一个参数,self 代表的是类的实例。
13.7 类的继承
继承语法
class 派生类名(基类名)
...
在python中继承中的一些特点:
- 如果在子类中需要父类的构造方法就需要显示的调用父类的构造方法,或者不重写父类的构造方法。
- 在调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别在于类中调用普通函数时并不需要带上 self 参数
- Python 总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。
语法:
派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
class SubClassName (ParentClass1[, ParentClass2, ...]):
...
BaseClassName(示例中的基类名)必须与派生类定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:
class DerivedClassName(modname.BaseClassName):
你可以使用issubclass()或者isinstance()方法来检测。
- issubclass() - 布尔函数判断一个类是另一个类的子类或者子孙类,语法:issubclass(sub,sup)
- isinstance(obj, Class) 布尔函数如果obj是Class类的实例对象或者是一个Class子类的实例对象则返回true。
13.8 方法重写
13.8.1 基础重载方法
| 方法 | 描述 | 简单的调用 |
|---|---|---|
| __init__ ( self [,args…] ) | 构造函数 | 简单的调用方法: obj = className(args) |
| __del__( self ) | 析构方法, 删除一个对象 | 简单的调用方法 : del obj |
| __repr__( self ) | 转化为供解释器读取的形式 | 简单的调用方法 : repr(obj) |
| __str__( self ) | 用于将值转化为适于人阅读的形式 | 简单的调用方法 : str(obj) |
| __cmp__ ( self, x ) | 对象比较 | 简单的调用方法 : cmp(obj, x) |
13.8.2 运算符重载
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print v1 + v2
结果:
Vector(7,8)
13.9 类属性与方法
13.9.1 类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
13.9.2 类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。
self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定是用 self。
13.9.3 类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
Python不允许实例化的类访问私有数据,但你可以使用 object._className__attrName( 对象名._类名__私有属性名 )访问属性,
类的专有方法:
__init__ : 构造函数,在生成对象时调用
__del__ : 析构函数,释放对象时使用
__repr__ : 打印,转换
__setitem__ : 按照索引赋值
__getitem__: 按照索引获取值
__len__: 获得长度
__cmp__: 比较运算
__call__: 函数调用
__add__: 加运算
__sub__: 减运算
__mul__: 乘运算
__truediv__: 除运算
__mod__: 求余运算
__pow__: 乘方
单下划线、双下划线、头尾双下划线说明:
__foo__: 定义的是特殊方法,一般是系统定义名字 ,类似 __init__() 之类的。
_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *
__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。
十四、Python 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
本章节主要介绍 Python 中常用的正则表达式处理函数,如果你对正则表达式不了解。
14.1 re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
14.2 re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
14.3 re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
14.4 检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。
compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
re.compile(pattern[, flags])
参数:
pattern : 一个字符串形式的正则表达式
flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为' . '并且包括换行符在内的任意字符(' . '不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和' # '后面的注释
findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
语法格式为:
re.findall(string[, pos[, endpos]])
参数:
string 待匹配的字符串。
pos 可选参数,指定字符串的起始位置,默认为 0。
endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。
re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| maxsplit | 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
14.5 正则表达式对象
re.RegexObject
re.compile() 返回 RegexObject 对象。
re.MatchObject
group() 返回被 RE 匹配的字符串。
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
14.6 正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
十五、Python CGI编程
CGI(Common Gateway Interface),通用网关接口,它是一段程序,运行在服务器上如:HTTP服务器,提供同客户端HTML页面的接口。
15.1 Web服务器支持及配置
进行CGI编程前,确保您的Web服务器支持CGI及已经配置了CGI的处理程序。
Apache 支持CGI 配置:
设置好CGI目录:
ScriptAlias /cgi-bin/ /var/www/cgi-bin/
所有的HTTP服务器执行CGI程序都保存在一个预先配置的目录。这个目录被称为CGI目录,并按照惯例,它被命名为/var/www/cgi-bin目录。
CGI文件的扩展名为.cgi,python也可以使用.py扩展名。
默认情况下,Linux服务器配置运行的cgi-bin目录中为/var/www。
如果你想指定其他运行CGI脚本的目录,可以修改httpd.conf配置文件,如下所示:
<Directory "/var/www/cgi-bin">
AllowOverride None
Options +ExecCGI
Order allow,deny
Allow from all
</Directory>
在 AddHandler 中添加 .py 后缀,这样我们就可以访问 .py 结尾的 python 脚本文件:
AddHandler cgi-script .cgi .pl .py
15.2 CGI程序
print ("Content-type:text/html")
print () # 空行,告诉服务器结束头部
print ('<html>')
print ('<head>')
print ('<meta charset="utf-8">')
print ('<title>Hello Word - 我的第一个 CGI 程序!</title>')
print ('</head>')
print ('<body>')
print ('<h2>Hello Word! </h2>')
print ('</body>')
print ('</html>')
HTTP头部
HTTP头部的格式如下:
HTTP 字段名: 字段内容
例如:
Content-type: text/html
| 头 | 描述 |
|---|---|
| Content-type: | 请求的与实体对应的MIME信息。例如: Content-type:text/html |
| Expires: Date | 响应过期的日期和时间 |
| Location: URL | 用来重定向接收方到非请求URL的位置来完成请求或标识新的资源 |
| Last-modified: Date | 请求资源的最后修改时间 |
| Content-length: N | 请求的内容长度 |
| Set-Cookie: String | 设置Http Cookie |
15.3 CGI环境变量
| 变量名 | 描述 |
|---|---|
| CONTENT_TYPE | 这个环境变量的值指示所传递来的信息的MIME类型。目前,环境变量CONTENT_TYPE一般都是:application/x-www-form-urlencoded,他表示数据来自于HTML表单。 |
| CONTENT_LENGTH | 如果服务器与CGI程序信息的传递方式是POST,这个环境变量即使从标准输入STDIN中可以读到的有效数据的字节数。这个环境变量在读取所输入的数据时必须使用。 |
| HTTP_COOKIE | 客户机内的 COOKIE 内容。 |
| HTTP_USER_AGENT | 提供包含了版本数或其他专有数据的客户浏览器信息。 |
| PATH_INFO | 这个环境变量的值表示紧接在CGI程序名之后的其他路径信息。它常常作为CGI程序的参数出现。 |
| QUERY_STRING | 如果服务器与CGI程序信息的传递方式是GET,这个环境变量的值即使所传递的信息。这个信息经跟在CGI程序名的后面,两者中间用一个问号’?'分隔。 |
| REMOTE_ADDR | 这个环境变量的值是发送请求的客户机的IP地址,例如上面的192.168.1.67。这个值总是存在的。而且它是Web客户机需要提供给Web服务器的唯一标识,可以在CGI程序中用它来区分不同的Web客户机。 |
| REMOTE_HOST | 这个环境变量的值包含发送CGI请求的客户机的主机名。如果不支持你想查询,则无需定义此环境变量。 |
| REQUEST_METHOD | 提供脚本被调用的方法。对于使用 HTTP/1.0 协议的脚本,仅 GET 和 POST 有意义。 |
| SCRIPT_FILENAME | CGI脚本的完整路径 |
| SCRIPT_NAME | CGI脚本的的名称 |
| SERVER_NAME | 这是你的 WEB 服务器的主机名、别名或IP地址。 |
| SERVER_SOFTWARE | 这个环境变量的值包含了调用CGI程序的HTTP服务器的名称和版本号。例如,上面的值为Apache/2.2.14(Unix) |
15.4 GET和POST方法
15.4.1 使用GET方法传输数据
有关 GET 请求的其他一些注释:
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
实例:
# CGI处理模块
import cgi, cgitb
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title> CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2>%s官网:%s</h2>" % (site_name, site_url))
print ("</body>")
print ("</html>")
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
</head>
<body>
<form action="/cgi-bin/hello_get.py" method="get">
名称: <input type="text" name="name"> <br />
URL: <input type="text" name="url" />
<input type="submit" value="提交" />
</form>
</body>
</html>
15.4.2 使用POST方法传递数据
# CGI处理模块
import cgi, cgitb
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title> CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2>%s官网:%s</h2>" % (site_name, site_url))
print ("</body>")
print ("</html>")
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title> </title>
</head>
<body>
<form action="/cgi-bin/hello_get.py" method="post">
名称: <input type="text" name="name"> <br />
URL: <input type="text" name="url" />
<input type="submit" value="提交" />
</form>
</body>
</html>
</form>
15.4.3 通过CGI程序传递checkbox数据
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title> </title>
</head>
<body>
<form action="/cgi-bin/checkbox.py" method="POST" target="_blank">
<input type="checkbox" name="runoob" value="on" />
<input type="checkbox" name="google" value="on" />
<input type="submit" value="选择 " />
</form>
</body>
</html>
# 引入 CGI 处理模块
import cgi, cgitb
# 创建 FieldStorage的实例
form = cgi.FieldStorage()
# 接收字段数据
if form.getvalue('google'):
google_flag = "是"
else:
google_flag = "否"
if form.getvalue('runoob'):
runoob_flag = "是"
else:
runoob_flag = "否"
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title> CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2> 是否选择了 : %s</h2>" % flag)
print ("<h2> 是否选择了 : %s</h2>" % google_flag)
print ("</body>")
print ("</html>")
15.4.4 通过CGI程序传递Radio数据
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title> </title>
</head>
<body>
<form action="/cgi-bin/radiobutton.py" method="post" target="_blank">
<input type="radio" name="site" value="runoob" />
<input type="radio" name="site" value="google" />
<input type="submit" value="提交" />
</form>
</body>
</html>
# 引入 CGI 处理模块
import cgi, cgitb
# 创建 FieldStorage的实例
form = cgi.FieldStorage()
# 接收字段数据
if form.getvalue('site'):
site = form.getvalue('site')
else:
site = "提交数据为空"
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title> CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2> 选中的网站是 %s</h2>" % site)
print ("</body>")
print ("</html>")
15.4.5 通过CGI程序传递 Textarea 数据
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title> </title>
</head>
<body>
<form action="/cgi-bin/textarea.py" method="post" target="_blank">
<textarea name="textcontent" cols="40" rows="4">
在这里输入内容...
</textarea>
<input type="submit" value="提交" />
</form>
</body>
</html>
# 引入 CGI 处理模块
import cgi, cgitb
# 创建 FieldStorage的实例
form = cgi.FieldStorage()
# 接收字段数据
if form.getvalue('textcontent'):
text_content = form.getvalue('textcontent')
else:
text_content = "没有内容"
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title> CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2> 输入的内容是:%s</h2>" % text_content)
print ("</body>")
print ("</html>")
15.4.6 通过CGI程序传递下拉数据。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title> </title>
</head>
<body>
<form action="/cgi-bin/textarea.py" method="post" target="_blank">
<select name="dropdown">
<option value="runoob" selected></option>
<option value="google"></option>
</select>
<input type="submit" value="提交" />
</form>
</body>
</html>
# 引入 CGI 处理模块
import cgi, cgitb
# 创建 FieldStorage的实例
form = cgi.FieldStorage()
# 接收字段数据
if form.getvalue('dropdown'):
text_content = form.getvalue('dropdown')
else:
text_content = "没有内容"
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title> CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2> 输入的内容是:%s</h2>" % text_content)
print ("</body>")
print ("</html>")
15.5 CGI中使用Cookie
15.5.1 cookie的语法
http cookie的发送是通过http头部来实现的,他早于文件的传递,头部set-cookie的语法如下:
Set-cookie:name=name;expires=date;path=path;domain=domain;secure
- name=name: 需要设置cookie的值(name不能使用";“和”,"号),有多个name值时用 “;” 分隔,例如:name1=name1;name2=name2;name3=name3。
- expires=date: cookie的有效期限,格式: expires=“Wdy,DD-Mon-YYYY HH:MM:SS”
- path=path: 设置cookie支持的路径,如果path是一个路径,则cookie对这个目录下的所有文件及子目录生效,例如: path=“/cgi-bin/”,如果path是一个文件,则cookie指对这个文件生效,例如:path=“/cgi-bin/cookie.cgi”。
- domain=domain: 对cookie生效的域名,例如:domain=“www.runoob.com”
- secure: 如果给出此标志,表示cookie只能通过SSL协议的https服务器来传递。
- cookie的接收是通过设置环境变量HTTP_COOKIE来实现的,CGI程序可以通过检索该变量获取cookie信息。
15.5.2 Cookie设置
print ('Content-Type: text/html')
print ('Set-Cookie: name="";expires=Wed, 28 Aug 2016 18:30:00 GMT')
print ()
print ("""
<html>
<head>
<meta charset="utf-8">
<title></title>
</head>
<body>
<h1>Cookie set OK!</h1>
</body>
</html>
""")
15.5.3 检索Cookie信息
Cookie信息检索页非常简单,Cookie信息存储在CGI的环境变量HTTP_COOKIE中,存储格式如下:
key1=value1;key2=value2;key3=value3....
# 导入模块
import os
import http.cookies
print ("Content-type: text/html")
print ()
print ("""
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<h1>读取cookie信息</h1>
""")
if 'HTTP_COOKIE' in os.environ:
cookie_string=os.environ.get('HTTP_COOKIE')
c= http.cookies.SimpleCookie()
# c=Cookie.SimpleCookie()
c.load(cookie_string)
try:
data=c['name'].value
print ("cookie data: "+data+"<br>")
except KeyError:
print ("cookie 没有设置或者已过去<br>")
print ("""
</body>
</html>
""")
15.6 文件上传下载
15.6.1 上传
HTML设置上传文件的表单需要设置 enctype 属性为 multipart/form-data,代码如下所示:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
</head>
<body>
<form enctype="multipart/form-data"
action="/cgi-bin/save_file.py" method="post">
<p>选中文件: <input type="file" name="filename" /></p>
<p><input type="submit" value="上传" /></p>
</form>
</body>
</html>
import cgi, os
import cgitb; cgitb.enable()
form = cgi.FieldStorage()
# 获取文件名
fileitem = form['filename']
# 检测文件是否上传
if fileitem.filename:
# 设置文件路径
fn = os.path.basename(fileitem.filename)
open('/tmp/' + fn, 'wb').write(fileitem.file.read())
message = '文件 "' + fn + '" 上传成功'
else:
message = '文件没有上传'
print ("""\
Content-Type: text/html\n
<html>
<head>
<meta charset="utf-8">
<title></title>
</head>
<body>
<p>%s</p>
</body>
</html>
""" % (message,))
15.6.2 下载
# HTTP 头部
print ("Content-Disposition: attachment; filename=\"foo.txt\"")
print ()
# 打开文件
fo = open("foo.txt", "rb")
str = fo.read();
print (str)
# 关闭文件
fo.close()
十六、Python 操作 MySQL 数据库
16.1 mysql-connector 驱动
可以使用 pip 命令来安装 mysql-connector:
python -m pip install mysql-connector
注意:如果你的 MySQL 是 8.0 版本,密码插件验证方式发生了变化,早期版本为 mysql_native_password,8.0 版本为 caching_sha2_password,所以需要做些改变:
先修改 my.ini 配置:
[mysqld]
default_authentication_plugin=mysql_native_password
然后在 mysql 下执行以下命令来修改密码:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '新密码';
16.1.1 创建数据库连接
import mysql.connector
mydb = mysql.connector.connect(
host="localhost", # 数据库主机地址
user="yourusername", # 数据库用户名
passwd="yourpassword" # 数据库密码
)
print(mydb)
16.1.2 创建数据库
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456"
)
mycursor = mydb.cursor()
mycursor.execute("CREATE DATABASE runoob_db")
16.1.3 创建数据表
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database=""
)
mycursor = mydb.cursor()
mycursor.execute("CREATE TABLE sites (name VARCHAR(255), url VARCHAR(255))")
16.1.4 主键设置
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database=""
)
mycursor = mydb.cursor()
mycursor.execute("ALTER TABLE sites ADD COLUMN id INT AUTO_INCREMENT PRIMARY KEY")
16.1.5 插入数据
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database=""
)
mycursor = mydb.cursor()
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = ("", "")
mycursor.execute(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
print(mycursor.rowcount, "记录插入成功。")
16.1.6 批量插入
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database=""
)
mycursor = mydb.cursor()
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = [
('Google', 'https://www.google.com'),
('Github', 'https://www.github.com'),
('Taobao', 'https://www.taobao.com'),
('stackoverflow', 'https://www.stackoverflow.com/')
]
mycursor.executemany(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
print(mycursor.rowcount, "记录插入成功。")
mycursor.lastrowid: 数据记录插入后,获取该记录的 ID
16.1.7 查询数据
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database=""
)
mycursor = mydb.cursor()
mycursor.execute("SELECT * FROM sites")
myresult = mycursor.fetchall() # fetchall() 获取所有记录
for x in myresult:
print(x)
想读取一条数据,可以使用 fetchone() 方法
为了防止数据库查询发生 SQL 注入的攻击,我们可以使用 %s 占位符来转义查询的条件
16.1.8 删除记录
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database=""
)
mycursor = mydb.cursor()
sql = "DELETE FROM sites WHERE name = 'stackoverflow'"
mycursor.execute(sql)
mydb.commit()
print(mycursor.rowcount, " 条记录删除")
16.1.9 更新表数据
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database=""
)
mycursor = mydb.cursor()
sql = "UPDATE sites SET name = 'ZH' WHERE name = 'Zhihu'"
mycursor.execute(sql)
mydb.commit()
print(mycursor.rowcount, " 条记录被修改")
16.1.10 删除表
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database=""
)
mycursor = mydb.cursor()
sql = "DROP TABLE IF EXISTS sites" # 删除数据表 sites
mycursor.execute(sql)
16.2 pymysql驱动
PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中则使用mysqldb。
PyMySQL 遵循 Python 数据库 API v2.0 规范,并包含了 pure-Python MySQL 客户端库。
16.2.1 PyMySQL 安装
在使用 PyMySQL 之前,我们需要确保 PyMySQL 已安装。
PyMySQL 下载地址:https://github.com/PyMySQL/PyMySQL。
如果还未安装,我们可以使用以下命令安装最新版的 PyMySQL:
pip3 install PyMySQL
如果你的系统不支持 pip 命令,可以使用以下方式安装:
1、使用 git 命令下载安装包安装(你也可以手动下载):
$ git clone https://github.com/PyMySQL/PyMySQL
$ cd PyMySQL/
$ python3 setup.py install
2、如果需要制定版本号,可以使用 curl 命令来安装:
$ # X.X 为 PyMySQL 的版本号
$ curl -L https://github.com/PyMySQL/PyMySQL/tarball/pymysql-X.X | tar xz
$ cd PyMySQL*
$ python3 setup.py install
$ # 现在你可以删除 PyMySQL* 目录
Linux 系统安装实例:
$ wget https://bootstrap.pypa.io/ez_setup.py
$ python3 ez_setup.py
16.2.2 数据库连接
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost","testuser","test123","TESTDB" )
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 使用 execute() 方法执行 SQL 查询
cursor.execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print ("Database version : %s " % data)
# 关闭数据库连接
db.close()
16.2.3 创建数据库表
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost","testuser","test123","TESTDB" )
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
# 使用预处理语句创建表
sql = """CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )"""
cursor.execute(sql)
# 关闭数据库连接
db.close()
16.2.4 数据库插入操作
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost","testuser","test123","TESTDB" )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 插入语句
sql = """INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)"""
try:
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except:
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
16.2.5 数据库查询操作
Python查询Mysql使用 fetchone() 方法获取单条数据, 使用fetchall() 方法获取多条数据。
fetchone(): 该方法获取下一个查询结果集。结果集是一个对象
fetchall(): 接收全部的返回结果行.
rowcount: 这是一个只读属性,并返回执行execute()方法后影响的行数。
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost","testuser","test123","TESTDB" )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 查询语句
sql = "SELECT * FROM EMPLOYEE \
WHERE INCOME > %s" % (1000)
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
for row in results:
fname = row[0]
lname = row[1]
age = row[2]
sex = row[3]
income = row[4]
# 打印结果
print ("fname=%s,lname=%s,age=%s,sex=%s,income=%s" % \
(fname, lname, age, sex, income ))
except:
print ("Error: unable to fetch data")
# 关闭数据库连接
db.close()
16.2.6 数据库更新操作
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost","testuser","test123","TESTDB" )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 更新语句
sql = "UPDATE EMPLOYEE SET AGE = AGE + 1 WHERE SEX = '%c'" % ('M')
try:
# 执行SQL语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except:
# 发生错误时回滚
db.rollback()
# 关闭数据库连接
db.close()
16.2.7 删除操作
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost","testuser","test123","TESTDB" )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 删除语句
sql = "DELETE FROM EMPLOYEE WHERE AGE > %s" % (20)
try:
# 执行SQL语句
cursor.execute(sql)
# 提交修改
db.commit()
except:
# 发生错误时回滚
db.rollback()
# 关闭连接
db.close()
16.3 错误处理
| 异常 | 描述 |
|---|---|
| Warning | 当有严重警告时触发,例如插入数据是被截断等等。必须是 StandardError 的子类。 |
| Error | 警告以外所有其他错误类。必须是 StandardError 的子类。 |
| InterfaceError | 当有数据库接口模块本身的错误(而不是数据库的错误)发生时触发。 必须是Error的子类。 |
| DatabaseError | 和数据库有关的错误发生时触发。 必须是Error的子类。 |
| DataError | 当有数据处理时的错误发生时触发,例如:除零错误,数据超范围等等。 必须是DatabaseError的子类。 |
| OperationalError | 指非用户控制的,而是操作数据库时发生的错误。例如:连接意外断开、 数据库名未找到、事务处理失败、内存分配错误等等操作数据库是发生的错误。 必须是DatabaseError的子类。 |
| IntegrityError | 完整性相关的错误,例如外键检查失败等。必须是DatabaseError子类。 |
| InternalError | 数据库的内部错误,例如游标(cursor)失效了、事务同步失败等等。 必须是DatabaseError子类。 |
| ProgrammingError | 程序错误,例如数据表(table)没找到或已存在、SQL语句语法错误、 参数数量错误等等。必须是DatabaseError的子类。 |
| NotSupportedError | 不支持错误,指使用了数据库不支持的函数或API等。例如在连接对象上 使用.rollback()函数,然而数据库并不支持事务或者事务已关闭。 必须是DatabaseError的子类。 |
十七、Python 网络编程
Python 提供了两个级别访问的网络服务。:
- 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法。
- 高级别的网络服务模块 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。
17.1 什么是 Socket?
Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。
17.2 socket()函数
Python 中,我们用 socket()函数来创建套接字,语法格式如下:
socket.socket([family[, type[, proto]]])
参数
- family: 套接字家族可以使AF_UNIX或者AF_INET
- type: 套接字类型可以根据是面向连接的还是非连接分为SOCK_STREAM或SOCK_DGRAM
- protocol: 一般不填默认为0.
Socket 对象(内建)方法
| 函数 | 描述 |
|---|---|
服务器端套接字 | |
| s.bind() | 绑定地址(host,port)到套接字, 在AF_INET下,以元组(host,port)的形式表示地址。 |
| s.listen() | 开始TCP监听。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为1,大部分应用程序设为5就可以了。 |
| s.accept() | 被动接受TCP客户端连接,(阻塞式)等待连接的到来 |
客户端套接字 | |
| s.connect() | 主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。 |
| s.connect_ex() | connect()函数的扩展版本,出错时返回出错码,而不是抛出异常 |
公共用途的套接字函数 | |
| s.recv() | 接收TCP数据,数据以字符串形式返回,bufsize指定要接收的最大数据量。flag提供有关消息的其他信息,通常可以忽略。 |
| s.send() | 发送TCP数据,将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。 |
| s.sendall() | 完整发送TCP数据,完整发送TCP数据。将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。 |
| s.recvfrom() | 接收UDP数据,与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。 |
| s.sendto() | 发送UDP数据,将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。 |
| s.close() | 关闭套接字 |
| s.getpeername() | 返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。 |
| s.getsockname() | 返回套接字自己的地址。通常是一个元组(ipaddr,port) |
| s.setsockopt(level,optname,value) | 设置给定套接字选项的值。 |
| s.getsockopt(level,optname[.buflen]) | 返回套接字选项的值。 |
| s.settimeout(timeout) | 设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect()) |
| s.gettimeout() | 返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None。 |
| s.fileno() | 返回套接字的文件描述符。 |
| s.setblocking(flag) | 如果flag为0,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用recv()没有发现任何数据,或send()调用无法立即发送数据,那么将引起socket.error异常。 |
| s.makefile() | 创建一个与该套接字相关连的文件 |
服务端
我们使用 socket 模块的 socket 函数来创建一个 socket 对象。socket 对象可以通过调用其他函数来设置一个 socket 服务。
现在我们可以通过调用 bind(hostname, port) 函数来指定服务的 port(端口)。
接着,我们调用 socket 对象的 accept 方法。该方法等待客户端的连接,并返回 connection 对象,表示已连接到客户端。
完整代码如下:
# 导入 socket、sys 模块
import socket
import sys
# 创建 socket 对象
serversocket = socket.socket(
socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
port = 9999
# 绑定端口号
serversocket.bind((host, port))
# 设置最大连接数,超过后排队
serversocket.listen(5)
while True:
# 建立客户端连接
clientsocket,addr = serversocket.accept()
print("连接地址: %s" % str(addr))
msg='欢迎访问 !'+ "\r\n"
clientsocket.send(msg.encode('utf-8'))
clientsocket.close()
客户端
接下来我们写一个简单的客户端实例连接到以上创建的服务。端口号为 9999。
socket.connect(hosname, port ) 方法打开一个 TCP 连接到主机为 hostname 端口为 port 的服务商。连接后我们就可以从服务端获取数据,记住,操作完成后需要关闭连接。
完整代码如下:
# 导入 socket、sys 模块
import socket
import sys
# 创建 socket 对象
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
# 设置端口号
port = 9999
# 连接服务,指定主机和端口
s.connect((host, port))
# 接收小于 1024 字节的数据
msg = s.recv(1024)
s.close()
print (msg.decode('utf-8'))
17.3 Python Internet 模块
| 协议 | 功能用处 | 端口号 | Python 模块 |
|---|---|---|---|
| HTTP | 网页访问 | 80 | httplib, urllib, xmlrpclib |
| NNTP | 阅读和张贴新闻文章,俗称为"帖子" | 119 | nntplib |
| FTP | 文件传输 | 20 | |
| SMTP | 发送邮件 | 25 | smtplib |
| POP3 | 接收邮件 | 110 | poplib |
| IMAP4 | 获取邮件 | 143 | imaplib |
| Telnet | 命令行 | 23 | telnetlib |
| Gopher | 信息查找 | 70 | gopherlib, urllib |
十八、Python SMTP发送邮件
18.1 发送邮件介绍
SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。
python的smtplib提供了一种很方便的途径发送电子邮件。它对smtp协议进行了简单的封装。
Python创建 SMTP 对象语法如下:
import smtplib
smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )
参数说明:
- host: SMTP 服务器主机。 你可以指定主机的ip地址或者域名如:runoob.com,这个是可选参数。
- port: 如果你提供了 host 参数, 你需要指定 SMTP 服务使用的端口号,一般情况下SMTP端口号为25。
- local_hostname: 如果SMTP在你的本机上,你只需要指定服务器地址为 localhost 即可。
Python SMTP对象使用sendmail方法发送邮件,语法如下:
SMTP.sendmail(from_addr, to_addrs, msg[, mail_options, rcpt_options]
参数说明:
- from_addr: 邮件发送者地址。
- to_addrs: 字符串列表,邮件发送地址。
- msg: 发送消息
这里要注意一下第三个参数,msg是字符串,表示邮件。我们知道邮件一般由标题,发信人,收件人,邮件内容,附件等构成,发送邮件的时候,要注意msg的格式。这个格式就是smtp协议中定义的格式。
实例
import smtplib
from email.mime.text import MIMEText
from email.header import Header
sender = ''
receivers = [''] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 三个参数:第一个为文本内容,第二个 plain 设置文本格式,第三个 utf-8 设置编码
message = MIMEText('Python 邮件发送测试...', 'plain', 'utf-8')
message['From'] = Header("", 'utf-8') # 发送者
message['To'] = Header("测试", 'utf-8') # 接收者
subject = 'Python SMTP 邮件测试'
message['Subject'] = Header(subject, 'utf-8')
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message.as_string())
print ("邮件发送成功")
except smtplib.SMTPException:
print ("Error: 无法发送邮件")
本机没有 sendmail 访问,也可以使用其他服务商的 SMTP 访问(QQ、网易、Google等)。
import smtplib
from email.mime.text import MIMEText
from email.header import Header
# 第三方 SMTP 服务
mail_host="smtp.XXX.com" #设置服务器
mail_user="XXXX" #用户名
mail_pass="XXXXXX" #口令
sender = ' '
receivers = [' '] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
message = MIMEText('Python 邮件发送测试...', 'plain', 'utf-8')
message['From'] = Header(" ", 'utf-8')
message['To'] = Header("测试", 'utf-8')
subject = 'Python SMTP 邮件测试'
message['Subject'] = Header(subject, 'utf-8')
try:
smtpObj = smtplib.SMTP()
smtpObj.connect(mail_host, 25) # 25 为 SMTP 端口号
smtpObj.login(mail_user,mail_pass)
smtpObj.sendmail(sender, receivers, message.as_string())
print ("邮件发送成功")
except smtplib.SMTPException:
print ("Error: 无法发送邮件")
18.2 使用Python发送HTML格式的邮件
import smtplib
from email.mime.text import MIMEText
from email.header import Header
sender = ' '
receivers = [' '] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
mail_msg = """
<p>Python 邮件发送测试...</p>
<p><a href="http://www.runoob.com">这是一个链接</a></p>
"""
message = MIMEText(mail_msg, 'html', 'utf-8')
message['From'] = Header("", 'utf-8')
message['To'] = Header("测试", 'utf-8')
subject = 'Python SMTP 邮件测试'
message['Subject'] = Header(subject, 'utf-8')
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message.as_string())
print ("邮件发送成功")
except smtplib.SMTPException:
print ("Error: 无法发送邮件")
18.3 Python 发送带附件的邮件
发送带附件的邮件,首先要创建MIMEMultipart()实例,然后构造附件,如果有多个附件,可依次构造,最后利用smtplib.smtp发送。
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
sender = ' '
receivers = [' '] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
#创建一个带附件的实例
message = MIMEMultipart()
message['From'] = Header(" ", 'utf-8')
message['To'] = Header("测试", 'utf-8')
subject = 'Python SMTP 邮件测试'
message['Subject'] = Header(subject, 'utf-8')
#邮件正文内容
message.attach(MIMEText('这是 Python 邮件发送测试……', 'plain', 'utf-8'))
# 构造附件1,传送当前目录下的 test.txt 文件
att1 = MIMEText(open('test.txt', 'rb').read(), 'base64', 'utf-8')
att1["Content-Type"] = 'application/octet-stream'
# 这里的filename可以任意写,写什么名字,邮件中显示什么名字
att1["Content-Disposition"] = 'attachment; filename="test.txt"'
message.attach(att1)
# 构造附件2,传送当前目录下的 runoob.txt 文件
att2 = MIMEText(open('runoob.txt', 'rb').read(), 'base64', 'utf-8')
att2["Content-Type"] = 'application/octet-stream'
att2["Content-Disposition"] = 'attachment; filename="runoob.txt"'
message.attach(att2)
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message.as_string())
print ("邮件发送成功")
except smtplib.SMTPException:
print ("Error: 无法发送邮件")
18.4 在 HTML 文本中添加图片
import smtplib
from email.mime.image import MIMEImage
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.header import Header
sender = ' '
receivers = [' '] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
msgRoot = MIMEMultipart('related')
msgRoot['From'] = Header(" ", 'utf-8')
msgRoot['To'] = Header("测试", 'utf-8')
subject = 'Python SMTP 邮件测试'
msgRoot['Subject'] = Header(subject, 'utf-8')
msgAlternative = MIMEMultipart('alternative')
msgRoot.attach(msgAlternative)
mail_msg = """
<p>Python 邮件发送测试...</p>
<p><a href="http://www..com"> </a></p>
<p>图片演示:</p>
<p><img src="cid:image1"></p>
"""
msgAlternative.attach(MIMEText(mail_msg, 'html', 'utf-8'))
# 指定图片为当前目录
fp = open('test.png', 'rb')
msgImage = MIMEImage(fp.read())
fp.close()
# 定义图片 ID,在 HTML 文本中引用
msgImage.add_header('Content-ID', '<image1>')
msgRoot.attach(msgImage)
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, msgRoot.as_string())
print ("邮件发送成功")
except smtplib.SMTPException:
print ("Error: 无法发送邮件")
18.5 使用第三方 SMTP 服务发送
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
my_sender=' @qq.com' # 发件人邮箱账号
my_pass = 'xxxxxxxxxx' # 发件人邮箱密码
my_user=' @qq.com' # 收件人邮箱账号,我这边发送给自己
def mail():
ret=True
try:
msg=MIMEText('填写邮件内容','plain','utf-8')
msg['From']=formataddr(["From ",my_sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号
msg['To']=formataddr(["FK",my_user]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号
msg['Subject']=" 发送邮件测试" # 邮件的主题,也可以说是标题
server=smtplib.SMTP_SSL("smtp.qq.com", 465) # 发件人邮箱中的SMTP服务器,端口是25
server.login(my_sender, my_pass) # 括号中对应的是发件人邮箱账号、邮箱密码
server.sendmail(my_sender,[my_user,],msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件
server.quit() # 关闭连接
except Exception: # 如果 try 中的语句没有执行,则会执行下面的 ret=False
ret=False
return ret
ret=mail()
if ret:
print("邮件发送成功")
else:
print("邮件发送失败")
十九、Python 多线程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
- 程序的运行速度可能加快。
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
- 线程可以被抢占(中断)。
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) – 这就是线程的退让。
线程可以分为:
- 内核线程:由操作系统内核创建和撤销。
- 用户线程:不需要内核支持而在用户程序中实现的线程。
Python3 线程中常用的两个模块为:
- _thread
- threading(推荐使用)
thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 “_thread”。
19.1 Python线程
Python中使用线程有两种方式:函数或者用类来包装线程对象。
函数式:调用 _thread 模块中的start_new_thread()函数来产生新线程。语法如下:
_thread.start_new_thread ( function, args[, kwargs] )
参数说明:
- function - 线程函数。
- args - 传递给线程函数的参数,他必须是个tuple类型。
- kwargs - 可选参数。
实例:
import _thread
import time
# 为线程定义一个函数
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# 创建两个线程
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: 无法启动线程")
while 1:
pass
19.2 线程模块
Python3 通过两个标准库 _thread 和 threading 提供对线程的支持。
_thread 提供了低级别的、原始的线程以及一个简单的锁,它相比于 threading 模块的功能还是比较有限的。
threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
19.3 使用 threading 模块创建线程
通过直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程,即它调用了线程的 run() 方法:
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.counter, 5)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程")
19.4 线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
考虑这样一种情况:一个列表里所有元素都是0,线程"set"从后向前把所有元素改成1,而线程"print"负责从前往后读取列表并打印。
那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态——锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。
经过这样的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.counter, 3)
# 释放锁,开启下一个线程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
# 添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
19.5 线程优先级队列( Queue)
Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。
这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
Queue 模块中的常用方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
import queue
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print ("开启线程:" + self.name)
process_data(self.name, self.q)
print ("退出线程:" + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print ("%s processing %s" % (threadName, data))
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
# 创建新线程
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充队列
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# 等待队列清空
while not workQueue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
二十、Python XML 解析
20.1 什么是 XML?
XML 指可扩展标记语言(eXtensible Markup Language)。 你可以通过本站学习 XML 教程
XML 被设计用来传输和存储数据。
XML 是一套定义语义标记的规则,这些标记将文档分成许多部件并对这些部件加以标识。
它也是元标记语言,即定义了用于定义其他与特定领域有关的、语义的、结构化的标记语言的句法语言。
20.2 Python 对 XML 的解析
常见的 XML 编程接口有 DOM 和 SAX,这两种接口处理 XML 文件的方式不同,当然使用场合也不同。
Python 有三种方法解析 XML,SAX,DOM,以及 ElementTree:
- SAX (simple API for XML ) :Python 标准库包含 SAX 解析器,SAX 用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件。
- DOM(Document Object Model) :将 XML 数据在内存中解析成一个树,通过对树的操作来操作XML。
- ElementTree(元素树) :ElementTree就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度快,消耗内存少。
注:因DOM需要将XML数据映射到内存中的树,一是比较慢,二是比较耗内存,而SAX流式读取XML文件,比较快,占用内存少,但需要用户实现回调函数(handler)。
<collection shelf="New Arrivals">
<movie title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title="Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title="Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title="Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>
20.3 python使用SAX解析xml
SAX是一种基于事件驱动的 API。
利用SAX解析XML文档牵涉到两个部分: 解析器和事件处理器。
解析器负责读取XML文档,并向事件处理器发送事件,如元素开始跟元素结束事件。
而事件处理器则负责对事件作出响应,对传递的XML数据进行处理。
- 对大型文件进行处理;
- 只需要文件的部分内容,或者只需从文件中得到特定信息。
- 想建立自己的对象模型的时候。
在python中使用sax方式处理xml要先引入xml.sax中的parse函数,还有xml.sax.handler中的ContentHandler。
20.4 ContentHandler类方法介绍
characters(content)方法
调用时机:
从行开始,遇到标签之前,存在字符,content 的值为这些字符串。
从一个标签,遇到下一个标签之前, 存在字符,content 的值为这些字符串。
从一个标签,遇到行结束符之前,存在字符,content 的值为这些字符串。
标签可以是开始标签,也可以是结束标签。
startDocument() 方法
文档启动的时候调用。
endDocument() 方法
解析器到达文档结尾时调用。
startElement(name, attrs)方法
遇到XML开始标签时调用,name是标签的名字,attrs是标签的属性值字典。
endElement(name) 方法
遇到XML结束标签时调用。
20.5 make_parser方法
以下方法创建一个新的解析器对象并返回。
xml.sax.make_parser( [parser_list] )
参数说明:
- parser_list - 可选参数,解析器列表
20.6 parser方法
以下方法创建一个 SAX 解析器并解析xml文档:
xml.sax.parse( xmlfile, contenthandler[, errorhandler])
参数说明:
- xmlfile - xml文件名
- contenthandler - 必须是一个ContentHandler的对象
- errorhandler - 如果指定该参数,errorhandler必须是一个SAX ErrorHandler对象
20.7 parseString方法
parseString方法创建一个XML解析器并解析xml字符串:
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])
参数说明:
- xmlstring - xml字符串
- contenthandler - 必须是一个ContentHandler的对象
- errorhandler - 如果指定该参数,errorhandler必须是一个SAX ErrorHandler对象
实例:
import xml.sax
class MovieHandler( xml.sax.ContentHandler ):
def __init__(self):
self.CurrentData = ""
self.type = ""
self.format = ""
self.year = ""
self.rating = ""
self.stars = ""
self.description = ""
# 元素开始事件处理
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "movie":
print ("*****Movie*****")
title = attributes["title"]
print ("Title:", title)
# 元素结束事件处理
def endElement(self, tag):
if self.CurrentData == "type":
print ("Type:", self.type)
elif self.CurrentData == "format":
print ("Format:", self.format)
elif self.CurrentData == "year":
print ("Year:", self.year)
elif self.CurrentData == "rating":
print ("Rating:", self.rating)
elif self.CurrentData == "stars":
print ("Stars:", self.stars)
elif self.CurrentData == "description":
print ("Description:", self.description)
self.CurrentData = ""
# 内容事件处理
def characters(self, content):
if self.CurrentData == "type":
self.type = content
elif self.CurrentData == "format":
self.format = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "rating":
self.rating = content
elif self.CurrentData == "stars":
self.stars = content
elif self.CurrentData == "description":
self.description = content
if ( __name__ == "__main__"):
# 创建一个 XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# 重写 ContextHandler
Handler = MovieHandler()
parser.setContentHandler( Handler )
parser.parse("movies.xml")
20.8 使用xml.dom解析xml
文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。
一个 DOM 的解析器在解析一个 XML 文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后你可以利用DOM 提供的不同的函数来读取或修改文档的内容和结构,也可以把修改过的内容写入xml文件。
python中用xml.dom.minidom来解析xml文件,实例如下:
from xml.dom.minidom import parse
import xml.dom.minidom
# 使用minidom解析器打开 XML 文档
DOMTree = xml.dom.minidom.parse("movies.xml")
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print ("Root element : %s" % collection.getAttribute("shelf"))
# 在集合中获取所有电影
movies = collection.getElementsByTagName("movie")
# 打印每部电影的详细信息
for movie in movies:
print ("*****Movie*****")
if movie.hasAttribute("title"):
print ("Title: %s" % movie.getAttribute("title"))
type = movie.getElementsByTagName('type')[0]
print ("Type: %s" % type.childNodes[0].data)
format = movie.getElementsByTagName('format')[0]
print ("Format: %s" % format.childNodes[0].data)
rating = movie.getElementsByTagName('rating')[0]
print ("Rating: %s" % rating.childNodes[0].data)
description = movie.getElementsByTagName('description')[0]
print ("Description: %s" % description.childNodes[0].data)
二十一、Python GUI编程(Tkinter)
Python 提供了多个图形开发界面的库,几个常用 Python GUI 库如下:
-
Tkinter: Tkinter 模块(Tk 接口)是 Python 的标准 Tk GUI 工具包的接口 .Tk 和 Tkinter 可以在大多数的 Unix 平台下使用,同样可以应用在 Windows 和 Macintosh 系统里。Tk8.0 的后续版本可以实现本地窗口风格,并良好地运行在绝大多数平台中。
-
wxPython:wxPython 是一款开源软件,是 Python 语言的一套优秀的 GUI 图形库,允许 Python 程序员很方便的创建完整的、功能健全的 GUI 用户界面。
-
Jython:Jython 程序可以和 Java 无缝集成。除了一些标准模块,Jython 使用 Java 的模块。Jython 几乎拥有标准的Python 中不依赖于 C 语言的全部模块。比如,Jython 的用户界面将使用 Swing,AWT或者 SWT。Jython 可以被动态或静态地编译成 Java 字节码。
21.1 Tkinter 编程
Tkinter 是 Python 的标准 GUI 库。Python 使用 Tkinter 可以快速的创建 GUI 应用程序。
由于 Tkinter 是内置到 python 的安装包中、只要安装好 Python 之后就能 import Tkinter 库、而且 IDLE 也是用 Tkinter 编写而成、对于简单的图形界面 Tkinter 还是能应付自如。
注意:Python3.x 版本使用的库名为 tkinter,即首写字母 T 为小写。
import tkinter
创建一个GUI程序
- 导入 Tkinter 模块
- 创建控件
- 指定这个控件的 master, 即这个控件属于哪一个
- 告诉 GM(geometry manager) 有一个控件产生了。
import Tkinter
top = Tkinter.Tk()
# 进入消息循环
top.mainloop()
# -------------------------------------------
from Tkinter import * # 导入 Tkinter 库
root = Tk() # 创建窗口对象的背景色
# 创建两个列表
li = ['C','python','php','html','SQL','java']
movie = ['CSS','jQuery','Bootstrap']
listb = Listbox(root) # 创建两个列表组件
listb2 = Listbox(root)
for item in li: # 第一个小部件插入数据
listb.insert(0,item)
for item in movie: # 第二个小部件插入数据
listb2.insert(0,item)
listb.pack() # 将小部件放置到主窗口中
listb2.pack()
root.mainloop() # 进入消息循环
21.2 Tkinter 组件
Tkinter的提供各种控件,如按钮,标签和文本框,一个GUI应用程序中使用。这些控件通常被称为控件或者部件。
目前有15种Tkinter的部件。我们提出这些部件以及一个简短的介绍,在下面的表:
| 控件 | 描述 |
|---|---|
| Button | 按钮控件;在程序中显示按钮。 |
| Canvas | 画布控件;显示图形元素如线条或文本 |
| Checkbutton | 多选框控件;用于在程序中提供多项选择框 |
| Entry | 输入控件;用于显示简单的文本内容 |
| Frame | 框架控件;在屏幕上显示一个矩形区域,多用来作为容器 |
| Label | 标签控件;可以显示文本和位图 |
| Listbox | 列表框控件;在Listbox窗口小部件是用来显示一个字符串列表给用户 |
| Menubutton | 菜单按钮控件,用于显示菜单项。 |
| Menu | 菜单控件;显示菜单栏,下拉菜单和弹出菜单 |
| Message | 消息控件;用来显示多行文本,与label比较类似 |
| Radiobutton | 单选按钮控件;显示一个单选的按钮状态 |
| Scale | 范围控件;显示一个数值刻度,为输出限定范围的数字区间 |
| Scrollbar | 滚动条控件,当内容超过可视化区域时使用,如列表框。. |
| Text | 文本控件;用于显示多行文本 |
| Toplevel | 容器控件;用来提供一个单独的对话框,和Frame比较类似 |
| Spinbox | 输入控件;与Entry类似,但是可以指定输入范围值 |
| PanedWindow | PanedWindow是一个窗口布局管理的插件,可以包含一个或者多个子控件。 |
| LabelFrame | labelframe 是一个简单的容器控件。常用与复杂的窗口布局。 |
| tkMessageBox | 用于显示你应用程序的消息框。 |
21.4 标准属性
标准属性也就是所有控件的共同属性,如大小,字体和颜色等等。
| 属性 | 描述 |
|---|---|
| Dimension | 控件大小; |
| Color | 控件颜色; |
| Font | 控件字体; |
| Anchor | 锚点; |
| Relief | 控件样式; |
| Bitmap | 位图; |
| Cursor | 光标; |
21.5 几何管理
Tkinter控件有特定的几何状态管理方法,管理整个控件区域组织,一下是Tkinter公开的几何管理类:包、网格、位置
| 几何方法 | 描述 |
|---|---|
| pack() | 包装; |
| grid() | 网格; |
| place() | 位置; |
二十二、Python JSON
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。
22.1 JSON 函数
使用 JSON 函数需要导入 json 库:import json。
| 函数 | 描述 |
|---|---|
| json.dumps | 将 Python 对象编码成 JSON 字符串 |
| json.loads | 将已编码的 JSON 字符串解码为 Python 对象 |
json.dumps 用于将 Python 对象编码成 JSON 字符串。
语法
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)
python 原始类型向 json 类型的转化对照表:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str, unicode | string |
| int, long, float | number |
| True | true |
| False | false |
| None | null |
json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型。
语法
json.loads(s[, encoding[, cls[, object_hook[, parse_float[, parse_int[, parse_constant[, object_pairs_hook[, **kw]]]]]]]])
json 类型转换到 python 的类型对照表:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | unicode |
| number (int) | int, long |
| number (real) | float |
| true | True |
| false | False |
| null | None |
22.2 使用第三方库:Demjson
Demjson 是 python 的第三方模块库,可用于编码和解码 JSON 数据,包含了 JSONLint 的格式化及校验功能。
Github 地址:https://github.com/dmeranda/demjson
官方地址:http://deron.meranda.us/python/demjson/
环境配置
在使用 Demjson 编码或解码 JSON 数据前,我们需要先安装 Demjson 模块。本教程我们会下载 Demjson 并安装:
tar -xvzf demjson-2.2.3.tar.gz
cd demjson-2.2.3
python setup.py install
22.3 JSON 函数
| 函数 | 描述 |
|---|---|
| encode | 将 Python 对象编码成 JSON 字符串 |
| decode | 将已编码的 JSON 字符串解码为 Python 对象 |
encode
Python encode() 函数用于将 Python 对象编码成 JSON 字符串。
语法
demjson.encode(self, obj, nest_level=0)
import demjson
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
json = demjson.encode(data)
print (json )
decode
Python 可以使用 demjson.decode() 函数解码 JSON 数据。该函数返回 Python 字段的数据类型。
语法
demjson.decode(self, txt)
import demjson
json = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = demjson.decode(json)
print (text)
附录一、内置函数
| 内置函数 | ||||
|---|---|---|---|---|
| abs() | divmod() | input() | open() | staticmethod() |
| all() | enumerate() | int() | ord() | str() |
| any() | eval() | isinstance() | pow() | sum() |
| basestring() | execfile() | issubclass() | print() | super() |
| bin() | file() | iter() | property() | tuple() |
| bool() | filter() | len() | range() | type() |
| bytearray() | float() | list() | raw_input() | unichr() |
| callable() | format() | locals() | reduce() | unicode() |
| chr() | frozenset() | long() | reload() | vars() |
| classmethod() | getattr() | map() | repr() | xrange() |
| cmp() | globals() | max() | reverse() | zip() |
| compile() | hasattr() | memoryview() | round() | __import__() |
| complex() | hash() | min() | set() | |
| delattr() | help() | next() | setattr() | |
| dict() | hex() | object() | slice() | |
| dir() | id() | oct() | sorted() | exec 内置表达式 |
附录二、Python3 标准库概览
错误输出重定向和程序终止
sys 还有 stdin,stdout 和 stderr 属性,即使在 stdout 被重定向时,后者也可以用于显示警告和错误信息。
sys.stderr.write('Warning, log file not found starting a new one\n')
访问 互联网
有几个模块用于访问互联网以及处理网络通信协议。其中最简单的两个是用于处理从 urls 接收的数据的 urllib.request 以及用于发送电子邮件的 smtplib:
from urllib.request import urlopen
for line in urlopen('http://tycho.usno.navy.mil/cgi-bin/timer.pl'):
line = line.decode('utf-8') # Decoding the binary data to text.
if 'EST' in line or 'EDT' in line: # look for Eastern Time
print(line)
import smtplib
server = smtplib.SMTP('localhost')
server.sendmail('soothsayer@example.org', 'jcaesar@example.org',
"""To: jcaesar@example.org
From: soothsayer@example.org
Beware the Ides of March.
""")
server.quit()
数据压缩
以下模块直接支持通用的数据打包和压缩格式:zlib,gzip,bz2,zipfile,以及 tarfile。
import zlib
s = b'witch which has which witches wrist watch'
len(s)
t = zlib.compress(s)
len(t)
zlib.decompress(t)
zlib.crc32(s)
附录三、Python2.x与3.x版本区别
Python的3.0版本,常被称为Python 3000,或简称Py3k。相对于Python的早期版本,这是一个较大的升级。
为了不带入过多的累赘,Python 3.0在设计的时候没有考虑向下相容。
许多针对早期Python版本设计的程式都无法在Python 3.0上正常执行。
为了照顾现有程式,Python 2.6作为一个过渡版本,基本使用了Python 2.x的语法和库,同时考虑了向Python 3.0的迁移,允许使用部分Python 3.0的语法与函数。
新的Python程式建议使用Python 3.0版本的语法。
除非执行环境无法安装Python 3.0或者程式本身使用了不支援Python 3.0的第三方库。目前不支援Python 3.0的第三方库有Twisted, py2exe, PIL等。
大多数第三方库都正在努力地相容Python 3.0版本。即使无法立即使用Python 3.0,也建议编写相容Python 3.0版本的程式,然后使用Python 2.6, Python 2.7来执行。
Python 3.0的变化主要在以下几个方面:
print 函数
print语句没有了,取而代之的是print()函数。 Python 2.6与Python 2.7部分地支持这种形式的print语法。在Python 2.6与Python 2.7里面,以下三种形式是等价的:
print "fish"
print ("fish") #注意print后面有个空格
print("fish") #print()不能带有任何其它参数
然而,Python 2.6实际已经支持新的print()语法:
from __future__ import print_function
print("fish", "panda", sep=', ')
Unicode
Python 2 有 ASCII str() 类型,unicode() 是单独的,不是 byte 类型。
现在, 在 Python 3,我们最终有了 Unicode (utf-8) 字符串,以及一个字节类:byte 和 bytearrays。
由于 Python3.X 源码文件默认使用utf-8编码,这就使得以下代码是合法的:
中国 = 'china'
print(中国)
Python 2.x
>>> str = "我爱北京天安门"
>>> str
'\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8'
>>> str = u"我爱北京天安门"
>>> str
u'\u6211\u7231\u5317\u4eac\u5929\u5b89\u95e8'
Python 3.x
>>> str = "我爱北京天安门"
>>> str
'我爱北京天安门'
除法运算
Python中的除法较其它语言显得非常高端,有套很复杂的规则。Python中的除法有两个运算符,/和//
首先来说/除法:
在python 2.x中/除法就跟我们熟悉的大多数语言,比如Java啊C啊差不多,整数相除的结果是一个整数,把小数部分完全忽略掉,浮点数除法会保留小数点的部分得到一个浮点数的结果。
在python 3.x中/除法不再这么做了,对于整数之间的相除,结果也会是浮点数。
Python 2.x:
>>> 1 / 2
0
>>> 1.0 / 2.0
0.5
Python 3.x:
>>> 1/2
0.5
而对于//除法,这种除法叫做floor除法,会对除法的结果自动进行一个floor操作,在python 2.x和python 3.x中是一致的。
python 2.x:
>>> -1 // 2
-1
python 3.x:
>>> -1 // 2
-1
注意的是并不是舍弃小数部分,而是执行 floor 操作,如果要截取整数部分,那么需要使用 math 模块的 trunc 函数
python 3.x:
>>> import math
>>> math.trunc(1 / 2)
0
>>> math.trunc(-1 / 2)
0
异常
在 Python 3 中处理异常也轻微的改变了,在 Python 3 中我们现在使用 as 作为关键词。
捕获异常的语法由 except exc, var 改为 except exc as var。
使用语法except (exc1, exc2) as var可以同时捕获多种类别的异常。 Python 2.6已经支持这两种语法。
- 在2.x时代,所有类型的对象都是可以被直接抛出的,在3.x时代,只有继承自BaseException的对象才可以被抛出。
- 2.x raise语句使用逗号将抛出对象类型和参数分开,3.x取消了这种奇葩的写法,直接调用构造函数抛出对象即可。
在2.x时代,异常在代码中除了表示程序错误,还经常做一些普通控制结构应该做的事情,在3.x中可以看出,设计者让异常变的更加专一,只有在错误发生的情况才能去用异常捕获语句来处理。
xrange
在 Python 2 中 xrange() 创建迭代对象的用法是非常流行的。比如: for 循环或者是列表/集合/字典推导式。
这个表现十分像生成器(比如。“惰性求值”)。但是这个 xrange-iterable 是无穷的,意味着你可以无限遍历。
由于它的惰性求值,如果你不得仅仅不遍历它一次,xrange() 函数 比 range() 更快(比如 for 循环)。尽管如此,对比迭代一次,不建议你重复迭代多次,因为生成器每次都从头开始。
在 Python 3 中,range() 是像 xrange() 那样实现以至于一个专门的 xrange() 函数都不再存在(在 Python 3 中 xrange() 会抛出命名异常)。
import timeit
n = 10000
def test_range(n):
return for i in range(n):
pass
def test_xrange(n):
for i in xrange(n):
pass
Python 2
print 'Python', python_version()
print '\ntiming range()'
%timeit test_range(n)
print '\n\ntiming xrange()'
%timeit test_xrange(n)
Python 2.7.6
timing range()
1000 loops, best of 3: 433 µs per loop
timing xrange()
1000 loops, best of 3: 350 µs per loop
Python 3
print('Python', python_version())
print('\ntiming range()')
%timeit test_range(n)
Python 3.4.1
timing range()
1000 loops, best of 3: 520 µs per loop
print(xrange(10))
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-5-5d8f9b79ea70> in <module>()
----> 1 print(xrange(10))
NameError: name 'xrange' is not defined
八进制字面量表示
八进制数必须写成0o777,原来的形式0777不能用了;二进制必须写成0b111。
新增了一个bin()函数用于将一个整数转换成二进制字串。 Python 2.6已经支持这两种语法。
在Python 3.x中,表示八进制字面量的方式只有一种,就是0o1000。
python 2.x
>>> 0o1000
512
>>> 01000
512
python 3.x
>>> 01000
File "<stdin>", line 1
01000
^
SyntaxError: invalid token
>>> 0o1000
512
不等运算符
Python 2.x中不等于有两种写法 != 和 <>
Python 3.x中去掉了<>, 只有!=一种写法,还好,我从来没有使用<>的习惯
去掉了repr表达式``
Python 2.x 中反引号``相当于repr函数的作用
Python 3.x 中去掉了``这种写法,只允许使用repr函数,这样做的目的是为了使代码看上去更清晰么?不过我感觉用repr的机会很少,一般只在debug的时候才用,多数时候还是用str函数来用字符串描述对象。
def sendMail(from_: str, to: str, title: str, body: str) -> bool:
pass
多个模块被改名(根据PEP8)
| 旧的名字 | 新的名字 |
|---|---|
| _winreg | winreg |
| ConfigParser | configparser |
| copy_reg | copyreg |
| Queue | queue |
| SocketServer | socketserver |
| repr | reprlib |
StringIO模块现在被合并到新的io模组内。 new, md5, gopherlib等模块被删除。 Python 2.6已经支援新的io模组。
httplib, BaseHTTPServer, CGIHTTPServer, SimpleHTTPServer, Cookie, cookielib被合并到http包内。
取消了exec语句,只剩下exec()函数。 Python 2.6已经支援exec()函数。
数据类型
1)Py3.X去除了long类型,现在只有一种整型——int,但它的行为就像2.X版本的long
2)新增了bytes类型,对应于2.X版本的八位串,定义一个bytes字面量的方法如下:
>>> b = b'china'
>>> type(b)
<type 'bytes'>
str 对象和 bytes 对象可以使用 .encode() (str -> bytes) 或 .decode() (bytes -> str)方法相互转化。
>>> s = b.decode()
>>> s
'china'
>>> b1 = s.encode()
>>> b1
b'china'
3)dict的.keys()、.items 和.values()方法返回迭代器,而之前的iterkeys()等函数都被废弃。同时去掉的还有 dict.has_key(),用 in替代它吧 。
附录四、Python uWSGI 安装配置
以 Ubuntu/Debian 为例,先安装依赖包:
apt-get install build-essential python-dev
Python 安装 uWSGI
1、通过 pip 命令:
pip install uwsgi
2、下载安装脚本:
curl http://uwsgi.it/install | bash -s default /tmp/uwsgi
将 uWSGI 二进制安装到 /tmp/uwsgi ,你可以修改它。
3、源代码安装:
wget http://projects.unbit.it/downloads/uwsgi-latest.tar.gz
tar zxvf uwsgi-latest.tar.gz
cd uwsgi-latest
make
第一个 WSGI 应用
让我们从一个简单的 “Hello World” 开始,创建文件 foobar.py,代码如下:
def application(env, start_response):
start_response('200 OK', [('Content-Type','text/html')])
return [b"Hello World"]
uWSGI Python 加载器将会搜索的默认函数 application 。
接下来我们启动 uWSGI 来运行一个 HTTP 服务器,将程序部署在HTTP端口 9090 上:
uwsgi --http :9090 --wsgi-file foobar.py
添加并发和监控
默认情况下,uWSGI 启动一个单一的进程和一个单一的线程。
你可以用 --processes 选项添加更多的进程,或者使用 --threads 选项添加更多的线程 ,也可以两者同时使用。
uwsgi --http :9090 --wsgi-file foobar.py --master --processes 4 --threads 2
以上命令将会生成 4 个进程, 每个进程有 2 个线程。
如果你要执行监控任务,可以使用 stats 子系统,监控的数据格式是 JSON:
uwsgi --http :9090 --wsgi-file foobar.py --master --processes 4 --threads 2 --stats 127.0.0.1:9191
我们可以安装 uwsgitop(类似 Linux top 命令) 来查看监控数据:
pip install uwsgitop
结合 Web 服务器使用
我们可以将 uWSGI 和 Nginx Web 服务器结合使用,实现更高的并发性能。
一个常用的nginx配置如下:
location / {
include uwsgi_params;
uwsgi_pass 127.0.0.1:3031;
}
以上代码表示使用 nginx 接收的 Web 请求传递给端口为 3031 的 uWSGI 服务来处理。
现在,我们可以生成 uWSGI 来本地使用 uwsgi 协议:
uwsgi --socket 127.0.0.1:3031 --wsgi-file foobar.py --master --processes 4 --threads 2 --stats 127.0.0.1:9191
如果你的 Web 服务器使用 HTTP,那么你必须告诉 uWSGI 本地使用 http 协议 (这与会自己生成一个代理的–http不同):
uwsgi --http-socket 127.0.0.1:3031 --wsgi-file foobar.py --master --processes 4 --threads 2 --stats 127.0.0.1:9191
部署 Django
Django 是最常使用的 Python web 框架,假设 Django 项目位于 /home/foobar/myproject:
uwsgi --socket 127.0.0.1:3031 --chdir /home/foobar/myproject/ --wsgi-file myproject/wsgi.py --master --processes 4 --threads 2 --stats 127.0.0.1:9191
–chdir 用于指定项目路径。
我们可以把以上的命令弄成一个 yourfile.ini 配置文件:
[uwsgi]
socket = 127.0.0.1:3031
chdir = /home/foobar/myproject/
wsgi-file = myproject/wsgi.py
processes = 4
threads = 2
stats = 127.0.0.1:9191
接下来你只需要执行以下命令即可:
uwsgi yourfile.ini
部署 Flask
Flask 是一个流行的 Python web 框架。
创建文件 myflaskapp.py ,代码如下:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return "<span style='color:red'>I am app 1</span>"
执行以下命令:
uwsgi --socket 127.0.0.1:3031 --wsgi-file myflaskapp.py --callable app --processes 4 --threads 2 --stats 127.0.0.1:9191
附录五、Python MongoDB
MongoDB 是目前最流行的 NoSQL 数据库之一,使用的数据类型 BSON(类似 JSON)。
- PyMongo
Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接。
pip 安装
pip 是一个通用的 Python 包管理工具,提供了对 Python 包的查找、下载、安装、卸载的功能。
安装 pymongo:
python3 -m pip3 install pymongo
也可以指定安装的版本:
python3 -m pip3 install pymongo==3.5.1
更新 pymongo 命令:
python3 -m pip3 install --upgrade pymongo
easy_install 安装
旧版的 Python 可以使用 easy_install 来安装,easy_install 也是 Python 包管理工具。
python -m easy_install pymongo
更新 pymongo 命令:
python -m easy_install -U pymongo
创建数据库
创建数据库需要使用 MongoClient 对象,并且指定连接的 URL 地址和要创建的数据库名。
如下实例中,我们创建的数据库
实例
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["数据库名称"]
注意: 在 MongoDB 中,数据库只有在内容插入后才会创建! 就是说,数据库创建后要创建集合(数据表)并插入一个文档(记录),数据库才会真正创建。
判断数据库是否已存在
我们可以读取 MongoDB 中的所有数据库,并判断指定的数据库是否存在:
实例
import pymongo
myclient = pymongo.MongoClient('mongodb://localhost:27017/')
dblist = myclient.list_database_names()
# dblist = myclient.database_names()
if "runoobdb" in dblist:
print("数据库已存在!")
注意:database_names 在最新版本的 Python 中已废弃,Python3.7+ 之后的版本改为了 list_database_names()。
创建集合
MongoDB 中的集合类似 SQL 的表。
创建一个集合
MongoDB 使用数据库对象来创建集合,实例如下:
实例
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"]
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
判断集合是否已存在
我们可以读取 MongoDB 数据库中的所有集合,并判断指定的集合是否存在:
实例
import pymongo
myclient = pymongo.MongoClient('mongodb://localhost:27017/')
mydb = myclient['runoobdb']
collist = mydb. list_collection_names()
# collist = mydb.collection_names()
if "sites" in collist: # 判断 sites 集合是否存在
print("集合已存在!")
注意:collection_names 在最新版本的 Python 中已废弃,Python3.7+ 之后的版本改为了 list_collection_names()。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











