










前言
上一篇我们从redis的线程模型分析了redis为什么使用单线程,以及从单线程性能依旧很出色分析了基于I/O多路复用的反应堆模式请求处理流程。本篇将此内存结构出发来分析redisDB的数据结构以及内存管理机制。
redis以内存作为存储资源也是它高性能的一个核心原因,接下来我们就来分析下redis是如何管理内存资源的。
一:Redisdb数据结构

Redis源码中对redisdb的定义如上图,其中dict *dict成员就是将key和具体的对象(可能是string、list、set、zset、hash中任意类型之一)关联起来,存储着该数据库中所有的键值对数据。expires成员用来存放key的过期时间。下面通过一张结构图来介绍这两个最核心的元素:
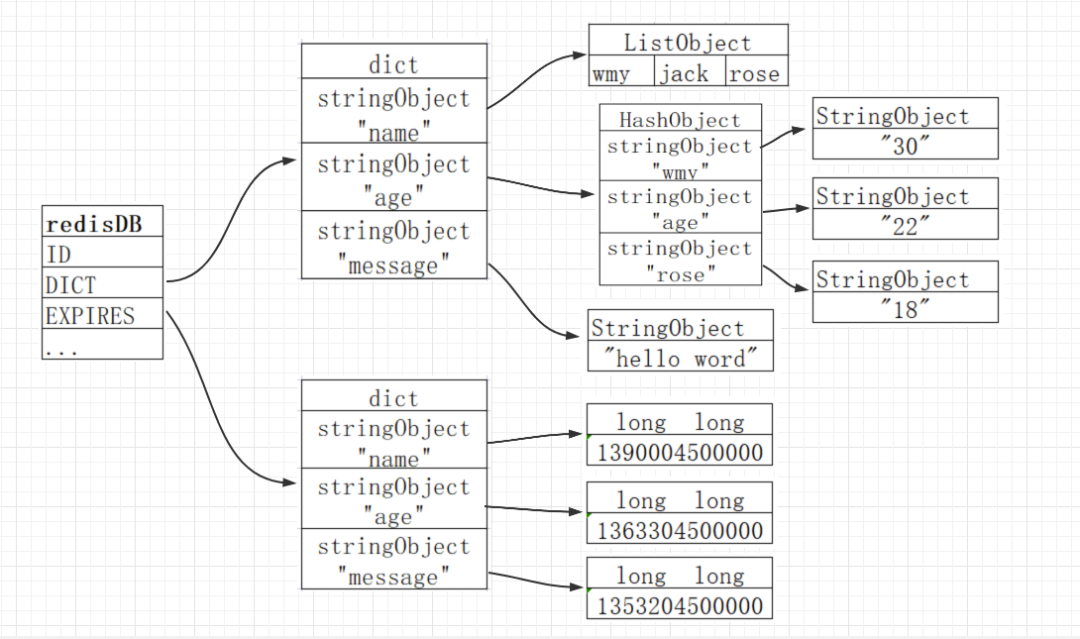
Dict中保存着redis的具体键值对数据,expires来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key,过期字典的值是一个long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
二:内存回收
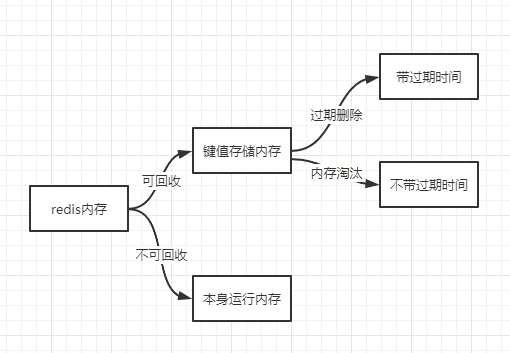
redis占用内存分为键值对所耗内存和本身运行所耗内存两部分,可回收的部分只能是键值对所使用的内存。键值对内存的回收分以带过期的、不带过期的、热点数据、冷数据。Redis 回收内存大致有两个机制:一是删除到达过期时间的键值对象;二是当内存达到 maxmemory 时触发内存移除控制策略,强制删除选择出来的键值对象。
2.1 过期删除
上面对redisdb结构的分析可以知道redis通过维护一个过期字典expires来记录key的过期时间,也知道是记录的过期毫秒值,那么应该怎样来实施删除操作了?
很容易我们能够想到以下三种模式:
-
定时删除:在设置键的过期时间的同时,创建定时器,让定时器在键过期时间到来时,即刻执行键值对的删除。
-
定期删除:每隔特定的时间对数据库进行一次扫描,检测并删除其中的过期键值对。
-
惰性删除:键值对过期暂时不进行删除,当获取键时先查看其是否过期,过期就删除,否则就保留。
当 Redis保存大量的键,对每个键都进行精准的过期删除会导致消耗大量的 CPU,惰性删除会造成内存空间的浪费,因此 Redis 采用惰性删除和定时任务删除相结合机制实现过期键的内存回收。
2.2 定期删除


在redis配置文件间中有hz和maxmemory-samples这样两个参数,hz默认为10,表示1s执行10次定期删除,maxmemory-samples配置了每次随机抽样的样本数,默认为5。下面用流程图来说明定期删除的执行逻辑。

-
定时任务首先根据快慢模式( 慢模型扫描的键的数量以及可以执行时间都比快模式要多 )和相关阈值配置计算计算本周期最大执行时间、要检查的数据库数量以及每个数据库扫描的键数量。
-
从上次定时任务未扫描的数据库开始,依次遍历各个数据库。
-
从数据库中随机选取键,如果发现是过期键,则调用函数删除它。
-
如果执行时间超过了设定的最大执行时间,则退出,并设置下一次使用快周期模式执行。
-
未超时的话,则判断是否采样的键中是否有25%的键是过期的,如果是则继续扫描当前数据库否则开始扫描下一个数据库。
如果Redis里面有大量key都设置了过期时间,全部都去检测一遍的话CPU负载就会很高,会浪费大量的时间在检测上面,所以只会抽取一部分而不会全部检查。正因为定期删除只是随机抽取部分key来检测,这样的话就会出现大量已经过期的key并没有被删除,这就是为什么有时候大量的key明明已经过了失效时间,但是redis的内存还是被大量占用的原因 ,为了解决这个问题,Redis又引入了“惰性删除策略”。
2.3 惰性删除
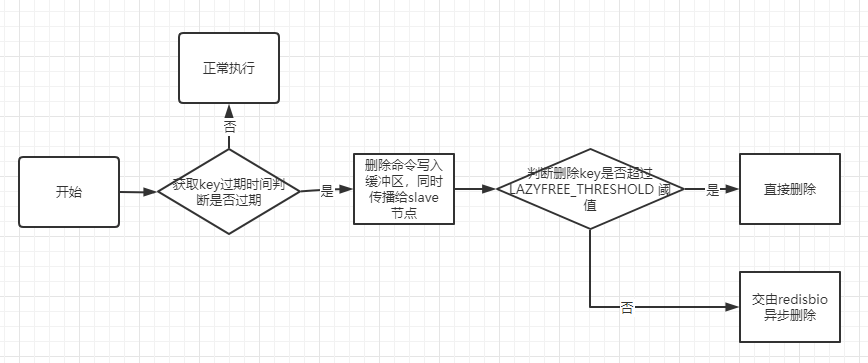
前面介绍到惰性删除是在操作一个key的时候再去判断是否过期,过期则进行删除。在操作key之前都会调用expireIfNeeded方法去检测是否过期并处理回收逻辑。

惰性删除逻辑如下图:
除了定期删除和惰性删除这些主动操作key的场景,其他场景下针对过期key会如何操作了?
1、快照生成RDB文件时
过期的key不会被保存在RDB文件中。
2、服务重启载入RDB文件时
Master载入RDB时,文件中的未过期的键会被正常载入,过期键则会被忽略。Slave 载入RDB 时,文件中的所有键都会被载入,当主从同步时,再和Master保持一致。
3、AOF 文件写入时
因为AOF保存的是执行过的Redis命令,所以如果redis还没有执行del,AOF文件中也不会保存del操作,当过期key被删除时,DEL 命令也会被同步到 AOF 文件中去。
4、重写AOF文件时执行
BGREWRITEAOF 时 ,过期的key不会被记录到 AOF 文件中。
5、主从同步时
Master 删除 过期 Key 之后,会向所有 Slave 服务器发送一个 DEL命令,Slave 收到通知之后,会删除这些 Key。Slave 在读取过期键时,不会做判断删除操作,而是继续返回该键对应的值,只有当Master 发送 DEL 通知,Slave才会删除过期键,这是统一中心化的键删除策略,保证主从服务器的数据一致性。
三:内存淘汰
可以为了保证Redis的安全稳定运行,设置了一个max-memory的阈值,那么当内存用量到达阈值,新写入的键值对无法写入,此时就需要内存淘汰机制,在Redis的配置中有几种淘汰策略可以选择:
-
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错;
-
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中移除最近最少使用的 key;
-
allkeys-random:当内存不足以容纳新写入数据时,在键空间中随机移除某个 key;
-
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key;
-
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 key;
-
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 key 优先移除;
-
volatile-lfu(least frequently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
-
allkeys-lfu(least frequently used):当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
内存淘汰机制由redis.conf配置文件中的maxmemory-policy属性设置,没有配置时默认为no-eviction模式。

volatile-lru、volatile-random、volatile-ttl三种策略都是针对过期字典的处理,但是在过期字典为空时会noeviction一样返回写入失败,所以一般选择第二种allkeys-lru基于LRU策略进行淘汰。volatile-lfu和allkeys-lfu是4.0 版本后新增加的。
3.1 LRU & LFU
上面的淘汰策略中主要分为lru和lfu两种类型,LRU即最近最少使用淘汰算法(Least Recently Used),LRU是淘汰最长时间没有被使用的。LFU即最不经常使用淘汰算法(Least Frequently Used),LFU是淘汰一段时间内,使用次数最少的页面。
LRU:它把数据存放在链表中按照最近访问的顺序排列,当某个key被访问时就将此key移动到链表的头部,保证了最近访问过的元素在链表的头部或前面。当链表满了之后,就将链表尾部的元素删除,再将新的元素添加至链表头部。
可以Redis采用了一种近似LRU的做法:给每个key增加一个大小为24bit的属性字段,代表最后一次被访问的时间戳。然后随机采样出5个key,淘汰掉最旧的key,直到Redis占用内存小于maxmemory为止。其中随机采样的数量可以通过Redis配置文件中的 maxmemory_samples 属性来调整,默认是5,采样数量越大越接近于标准LRU算法,但也会带来性能的消耗。在Redis 3.0以后增加了LRU淘汰池,进一步提高了与标准LRU算法效果的相似度。淘汰池即维护的一个数组,数组大小等于抽样数量 maxmemory_samples,在每一次淘汰时,新随机抽取的key和淘汰池中的key进行合并,然后淘汰掉最旧的key,将剩余较旧的前面5个key放入淘汰池中待下一次循环使用。
自己实现一个LRU算法:
使用head和end表示链表的头和尾,在时间上先被访问的数据作为双向链表的head,后被访问的数据作为双向链表的end,当容量达到最大值后,新进入未被访问过的数据,则将head的节点删除,将新的数据插入end处,如果访问的数据在内存中,则将数据更新到end除,删除原始在的位置。结构变换示意如下:

代码实现:
public class LRUCache<K, V> {
//最大容量
private int maxSize;
//缓存存储结构
private HashMap<K,CacheNode> map;
//第一个元素结点
private CacheNode first;
//最后一个元素结点
private CacheNode last;
//初始化
public LRUCache(int size){
this.maxSize = size;
map = new HashMap<K,CacheNode>(size);
}
//新增节点,,放在队列头,容量满了删除队列尾元素。
public void put(K k,V v){
CacheNode node = map.get(k);
if(node == null){
if(map.size() >= maxSize){
map.remove(last.key);
removeLast();
}
node = new CacheNode();
node.key = k;
}
node.value = v;
moveToFirst(node);
map.put(k, node);
}
//获取元素将被操作元素移到队列头
public Object get(K k){
CacheNode node = map.get(k);
if(node == null){
return null;
}
moveToFirst(node);
return node.value;
}
//删除元素,调整前后节点位置关系
public Object remove(K k){
CacheNode node = map.get(k);
if(node != null){
if(node.pre != null){
node.pre.next=node.next;
}else {
first = node.next;
}
if(node.next != null){
node.next.pre=node.pre;
}else {
last = node.pre;
}
}
return map.remove(k);
}
public void clear(){
first = null;
last = null;
map.clear();
}
//将元素移动到队列头
private void moveToFirst(CacheNode node){
if(first == node){
return;
}
if(node.next != null){
node.next.pre = node.pre;
}
if(node.pre != null){
node.pre.next = node.next;
}
if(node == last){
last= last.pre;
}
if(first == null || last == null){
first = last = node;
return;
}
node.next=first;
first.pre = node;
first = node;
first.pre=null;
}
private void removeLast(){
if(last != null){
last = last.pre;
if(last == null){
first = null;
}else{
last.next = null;
}
}
}
@Override
public String toString(){
StringBuilder sb = new StringBuilder();
CacheNode node = first;
while(node != null){
sb.append(String.format("%s:%s ", node.key,node.value));
node = node.next;
}
return sb.toString();
}
//定义node数据结构
class CacheNode{
CacheNode pre;
CacheNode next;
Object key;
Object value;
}
public static void main(String[] args) {
LRUCache<Integer,String> lru = new LRUCache<Integer,String>(3);
lru.put(1, "a");
lru.put(2, "b");
lru.put(3, "c");
System.out.println(lru.toString());
lru.get(1);
System.out.println(lru.toString());
lru.get(3);
System.out.println(lru.toString());
lru.put(4, "d");
System.out.println(lru.toString());
lru.put(5,"e");
System.out.println(lru.toString());
}
}执行结果如下,和上述设计示意图一致

LFU:最近最少使用,跟使用的次数有关,淘汰使用次数最少的。从 Redis 4.0 版本开始,新增最少使用的回收模式。在 LRU 中,一个最近访问过但实际上几乎从未被请求过的 key 很有可能不会过期,那么风险就是删除一个将来有更高概率被请求的 key。LFU 加入了访问次数的维度,可以更好地适应不同的访问模式。

上图这种情况在lru算法下将会被保留下来。淘汰算法的本意是保留那些将来最有可能被再次访问的数据,而LRU算法只是预测最近被访问的数据将来最有可能被访问到。LFU(Least Frequently Used)算法就是最频繁被访问的数据将来最有可能被访问到。在上面的情况中,根据访问频繁情况,可以确定保留优先级:B>A>C=D。
3.2 Redis LFU算法设计思路
在LFU算法中,可以为每个key维护一个计数器。每次key被访问的时候,计数器增大。计数器越大,可以约等于访问越频繁。
上述简单算法存在一个问题,只是简单的增加计数器的方法并不完美。访问模式是会频繁变化的,一段时间内频繁访问的key一段时间之后可能会很少被访问到,只增加计数器并不能体现这种趋势。解决办法是,记录key最后一个被访问的时间,然后随着时间推移,降低计数器。

在LRU算法中,24 bits的lru是用来记录LRU time的,在LFU中也可以使用这个字段,不过是分成16 bits与8 bits使用:高16 bits用来记录最近一次计数器降低的时间ldt,单位是分钟,低8 bits记录计数器数值counter。
配置 LFU 策略,如下:
-
volatile-lfu :在设置了失效时间的所有 key 中,使用近似的 LFU 淘汰 key,也就是最少被访问的 key.
-
allkeys-lfu : 在所有 key 里根据 LFU 淘汰 key.
为了解决上述访问次数增长过快和突然不访问后次数不变造成的不会被清楚问题,提供了如下配置参数:
-
lfu-log-factor 10 可以调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。
-
lfu-decay-time 1 是一个以分钟为单位的数值,可以调整counter的减少速度,衰减时间默认是1.
3.3 自己实现一个LFU算法:
设计思路:可以使用JDK提供的优先队列 PriorityQueue 来实现,即可以保证每次 poll 元素的时候,都可以根据我们的要求,取出当前所有元素的最大值或是最小值。
只需要我们的实体类实现 Comparable 接口就可以了。需要定义一个 Node 来保存当前元素的访问频次 freq,全局的自增的 index,用于比较大小。然后定义一个 Map<Integer,Node> cache ,用于存放元素的信息。
当 cache 容量不足时,根据访问频次 freq 的大小来删除最小的 freq 。若相等,则删除 index 最小的,因为index是自增的,越大说明越是最近访问过的,越小说明越是很长时间没访问过的元素。
代码如下:
public class LFUCache {
//存储node元素
Map<Integer,Node> cache;
//优先队列
Queue<Node> ;
//容量
int capacity;
//当前缓存的元素个数
int size;
int index = 0;
//初始化
public LFUCache(int capacity){
this.capacity = capacity;
if(capacity > 0){
queue = new PriorityQueue<>(capacity);
}
cache = new HashMap<>();
}
public int get(int key){
Node node = cache.get(key);
// node不存在,则返回 -1
if(node == null) return -1;
//每访问一次,频次和全局index都自增 1
node.freq++;
node.index = index++;
// 每次都重新remove,再offer是为了让优先队列能够对当前Node重排序
//不然的话,比较的 freq 和 index 就是不准确的
queue.remove(node);
queue.offer(node);
return node.value;
}
public void put(int key, int value){
//容量0,则直接返回
if(capacity == 0) return;
Node node = cache.get(key);
//如果node存在,则更新它的value值
if(node != null){
node.value = value;
node.freq++;
node.index = index++;
queue.remove(node);
queue.offer(node);
}else {
//如果cache满了,则从优先队列中取出一个元素,这个元素一定是频次最小,最久未访问过的元素
if(size == capacity){
cache.remove(queue.poll().key);
//取出元素后,size减 1
size--;
}
//否则,说明可以添加元素,于是创建一个新的node,添加到优先队列中
Node newNode = new Node(key, value, index++);
queue.offer(newNode);
cache.put(key,newNode);
//同时,size加 1
size++;
}
}
//必须实现 Comparable 接口才可用于排序
private class Node implements Comparable<Node>{
int key;
int value;
int freq = 1;
int index;
public Node(int key, int value, int index){
this.key = key;
this.value = value;
this.index = index;
}
@Override
public int compareTo(Node o) {
//优先比较频次 freq,频次相同再比较index
int minus = this.freq - o.freq;
return minus == 0? this.index - o.index : minus;
}
}
public static void main(String[] args) {
LFUCache cache = new LFUCache(2);
cache.put(1, 1);
cache.put(2, 2);
// 返回 1
System.out.println(cache.get(1));
cache.put(3, 3); // 去除 key 2
// 返回 -1 (未找到key 2)
System.out.println(cache.get(2));
// 返回 3
System.out.println(cache.get(3));
cache.put(4, 4); // 去除 key 1
// 返回 -1 (未找到 key 1)
System.out.println(cache.get(1));
// 返回 3
System.out.println(cache.get(3));
// 返回 4
System.out.println(cache.get(4));
}四:告一段落
可到这里我们从redisdb内存存储结构分析了内存回收模式,过期回收和内存淘汰两类,根据内存淘汰策略解读了LRU算法和LFU的算法,以及使用java语言对两种算法做了简单的实现。接下来将对redis的持久化、主从同步、高可用部署等其他相关内容做分析解读。

文章导航
| 类别 | 标题 | 发布 |
| Redis | Redis(一):单线程为何还能这么快 | 己发布 |
| Redis(二):内存模型及回收算法 | 本文章 | |
| Redis(三):持久化 | 2021.10.27 | |
| Redis(四):主从同步 | 即将上线 | |
| Redis(五):集群搭建 | 即将上线 | |
| Redis(六):实战应用 | 即将上线 | |
| Elasticsearch | Elasticsearch:概述 | 己发布 |
| Elasticsearch:核心 | 2021.10.25 | |
| Elasticsearch:实战 | 2021.10.29 | |
| Elasticsearch写入流程详解 | 即将上线 | |
| Elasticsearch查询流程详解 | 即将上线 | |
| Elasticsearch集群一致性 | 即将上线 | |
| Lucene的基本概念 | 即将上线 | |
| Elasticsearch部署架构和容量规划 | 即将上线 | |
| RocketMQ | RocketMQ—NameServer总结及核心源码剖析 | 2021.11.01 |
| RocketMQ—深入剖析Producer | 即将上线 | |
| Broker—启动流程源码解密 | 即将上线 | |
| Broker—接受消息处理流程解密 | 即将上线 | |
| Tomcat源码分析 | Tomcat(一):项目结构及架构分析 | 即将上线 |
| Tomcat(二):启动关闭流程分析 | 即将上线 | |
| Tomcat(三):应用加载原理分析 | 即将上线 | |
| Tomcat(四):网络请求原理分析 | 即将上线 | |
| Tomcat(五):嵌入式及性能调优 | 即将上线 | |
| Nacos | Nacos项目结构及架构分析 | 即将上线 |
| Nacos服务注册源码解析 | 即将上线 | |
| Nacos配置管理源码解析 | 即将上线 | |
| Nacos2.0版本优化功能解析 | 即将上线 | |
| Netty | 计算机网络&nio核心原理 | 即将上线 |
| 详细解读kafka是如何基于原生nio封装网络通信组件的? | 即将上线 | |
| netty初识之核心组件介绍 | 即将上线 | |
| 源码解析netty服务端,端口是如何拉起来的?新连接接入又如何处理? | 即将上线 | |
| 深入netty中各种事件如何在pipeline中传播的? | 即将上线 | |
| 网络编程中拆包粘包是什么?kafka以及netty是如何解决的? | 即将上线 | |
| 深入解读netty中最为复杂的缓存分配是如何进行的? | 即将上线 | |
| 源码分析netty、kafka、sentinel中不同时间轮实现方式以及细节 | 即将上线 | |
| 尝试从上帝角度对比kafka&netty中的性能优化,各种设计模式的丰富运用 | 即将上线 | |
| Netty在Rocketmq中的实践,RocketMq的消息协议解读 | 即将上线 | |

关注IT巅峰技术,私信作者,获取以下2021全球架构师峰会PDF资料。

















 3897
3897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









