






提到大数据技术,大多数开发者首先想到的技术莫过于Hadoop和Spark。他们都是大数据框架,也是当前应用最广泛的大数据框架。
4月11晚8点(本周二),CSDN大数据学习班将迎来咱们的第二期知识大咖分享活动,主要分享开源的Spark大数据技术。
分享嘉宾:叶帅
叶帅 毕业于东华大学,研究方向为数据科学,目前就职于小i机器人,主要负责Hadoop、Spark集群搭建和维护,大数据分析和数据挖掘,Hive数据仓库和数据建模。Job和日志数据管理等工作
以下为昨晚的分享总结:
本次分享主题是Spark入门,既然是入门,就涉及Spark的部署和基本概念的理解,这也是我们进一步深入理解Spark的基础。
首先是部署环节:
1.先安装,HDFS的namenode,secondaryNamenode, datanode
Spark的master和worker进程;
Master负责分配资源,在集群启动时,Driver向Master申请资源,Worker负责监控自己节点的内存和CPU等状况,并向Master汇报。
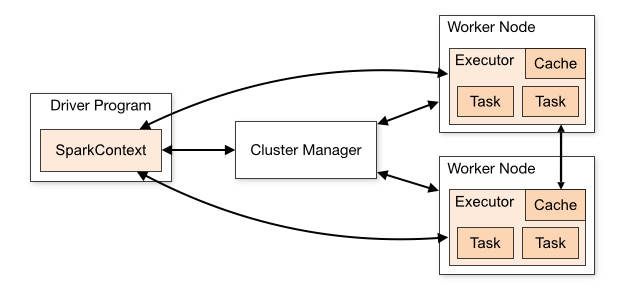
2.Cluster模型:Spark Application的组成部分
一个Worker默认情况下分配一个Executor,配置时根据需要也可以配置多个Executor。一个节点,如果配置了多个Executor,那么就会涉及到性能调优。
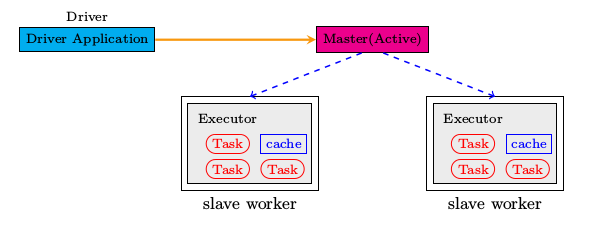
3.standalone的运行模式:
组成cluster的两大元素即Master和Worker。slave worker可以有1到多个,这些worker都处于active状态。
Driver Application可以运行在Cluster之内,也可以在cluster之外运行,先从简单的讲起即Driver Application独立于Cluster。那么这样的整体框架如上图所示,由driver,master和多个slave worker来共同组成整个的运行环境。
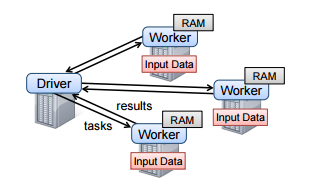
4.Spark Runtime
Driver进程启动多个worker进程,worker从HDFS读取Block,然后将RDD分片保存在内存中能计算。
5.来一个wordcount程序:
object WordCount {
def main(args: Array[String]) {
val inputFile = args(0)
val outputFile = args(1)
val conf = new SparkConf().setAppName("wordCount")
// Create a Scala Spark Context.
val sc = new SparkContext(conf)
// Load our input data.
val input = sc.textFile(inputFile)
// Split up into words.
val words = input.flatMap(line => line.split(" "))
// Transform into word and count.
val counts = words.map(word => (word, 1)).reduceByKey{case (x, y) => x + y}
// Save the word count back out to a text file, causing evaluation.
counts.saveAsTextFile(outputFile)
}
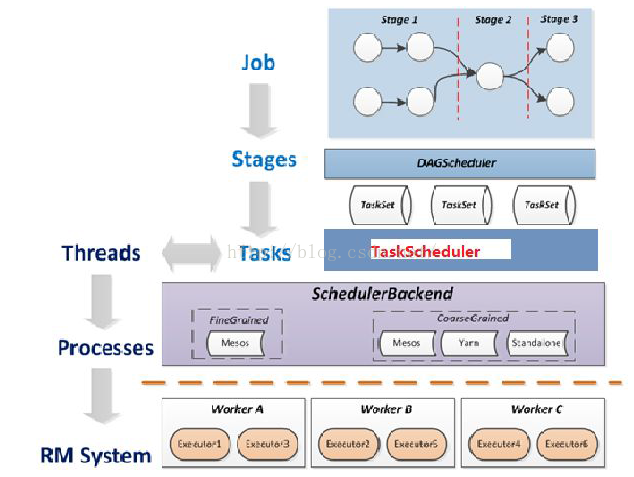
}6.Job的内部运行机制
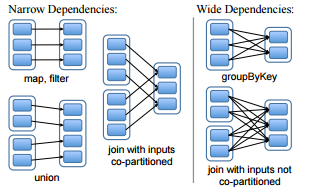
7.RDD宽依赖和窄依赖的例子
- 窄依赖:父RDD的每个分片基本都被子RDD的一个分片所利用。
- 宽依赖:父RDD的每个分片被多个子RDD分片依赖。
这里每个蓝色方框都是一个RDD,外边的长方形是分片。
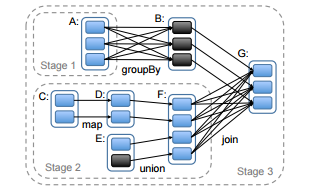
8.Job Stage
任务调度,黑色部分代表RDD在内存中。基于RDD的G是一个action操作,引起跨stage的宽依赖和一个stage中的窄依赖转换(pipeline transformation)。Stage的虚线是宽依赖所需要的shuffle操作。只有有一个task计算失败,只要还有父RDD,就在其他节点上重新计算。
CSDN大数据学习班正在火热招新中,扫描下方二维码,备注:“大数据”即可入班学习。
















 1085
1085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









