







什么是Controller
Controller作为Kafka集群中的核心组件,它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。 Controller与Zookeeper进行交互,获取与更新集群中的元数据信息。其他broker并不直接与zookeeper进行通信,而是与 Controller 进行通信并同步Controller中的元数据信息。 Kafka集群中每个节点都可以充当Controller节点,但集群中同时只能有一个Controller节点。
1. Kafka Broker的作用
Apache Kafka的Broker节点是Kafka系统的基本组成部分,它们主要负责数据的存储和传输。Kafka的所有数据都存储在Broker节点中,同时它们还负责处理客户端的读写请求,以及在Broker节点之间复制数据以确保数据的可靠性和高可用性。
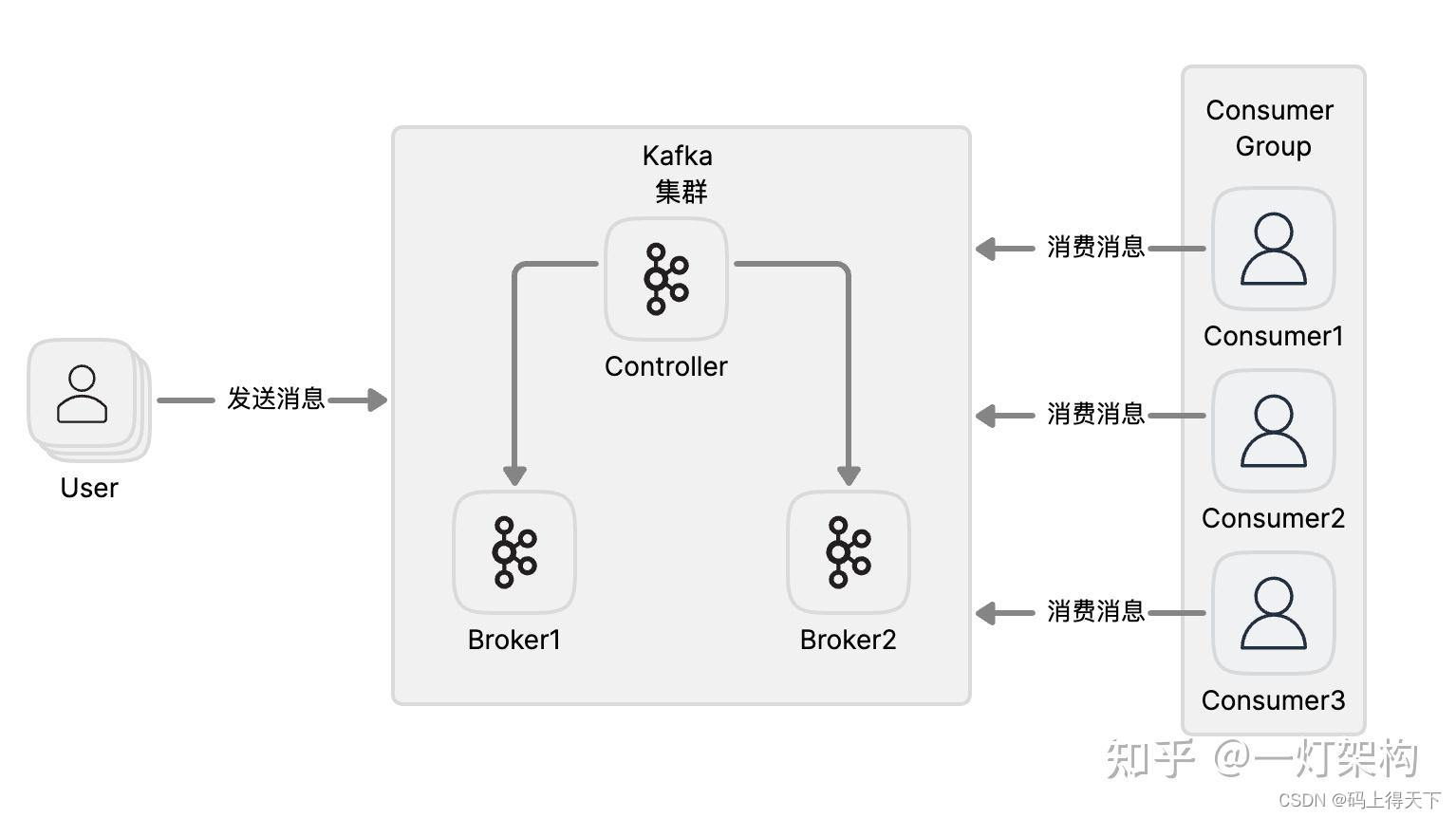
一个Broker节点相当于一台机器,多个Broker节点组成一个Kafka集群。但是只有一个Broker节点可以充当Controller(控制器)节点,Controller节点直接与zookeeper进行通信,并负责管理整个集群的状态和元数据信息。
以下是Controller节点的主要职能:
- Broker状态管理:Controller会跟踪集群中所有Broker的在线状态,并在Broker宕机或者恢复时更新集群的状态。
- 分区状态管理:当新的Topic被创建,或者已有的Topic被删除时,Controller会负责管理这些变化,并更新集群的状态。
- 分区领导者选举:当一台Broker节点宕机时,并且宕机的机器上包含分区领导者副本时,Controller会负责对其上的所有Partition进行新的领导者选举。
- 副本状态管理:Controller负责管理Partition的ISR列表,当Follower副本无法及时跟随Leader副本时,Controller会将其从ISR列表中移除。
- 分区重平衡:当添加或删除Broker节点时,Controller会负责对Partition的分布进行重平衡,以确保数据的均匀分布。
- 存储集群元数据:Controller保存了集群中最全的元数据信息,并通过发送请求同步到其他Broker上面。

而非Controller节点的主要作用如下:
- 数据存储:每个非Controller节点都存储一部分数据,这部分数据是由Topic的Partition组成的。这意味着,每个Broker都保存了特定Partition的所有数据,不论这个Partition是Leader还是Follower。
- 数据复制:为了保证数据的可靠性,Kafka系统通过数据复制机制在多个Broker之间备份数据。每个Topic的Partition都有一个Leader和多个Follower。Leader负责处理所有的客户端读写请求,而Follower负责从Leader复制数据。在这个过程中,非Controller节点既可以是Leader也可以是Follower。
- 处理客户端请求:非Controller节点负责处理来自Producer和Consumer的请求。对于Producer的写请求,Broker会将数据写入对应的Partition。对于Consumer的读请求,Broker会从对应的Partition读取数据。
- 参与Leader选举:当Partition的Leader节点出现故障时,非Controller节点可能被选举为新的Leader节点。虽然Leader选举过程由Controller节点协调,但所有的非Controller节点都需要参与这个过程。
- 故障恢复:当某个Broker宕机时,Kafka会自动重新分配其上的Partition的Leader角色给其他的Broker,这也是非Controller节点的重要职责之一。
2. Controller节点初始化
Kafka Controller节点的初始化依赖Zookeeper实现,具体流程如下:
- 注册 Controller 节点
当 Kafka 集群启动时,每个 Broker 都会尝试在 Zookeeper 中的/controller路径下创建一个临时节点。因为同一时刻只能存在一个/controller节点,所以只有一个 Broker 成功创建节点并成为Controller。其他 Broker 会收到节点创建失败的通知,然后转为观察者(Observer)状态,监视Controller节点路径的变化。 - 监听 Controller 节点
所有非Controller的 Broker 都会在 Zookeeper 中对/controller路径设置一个 Watcher 事件。这样当Controller节点发生变化时(例如,Controller失效),所有非Controller就会收到一个 Watcher 事件。 - 选举新的Controller
当某个 Broker 接收到Controller节点变化的通知后,它会再次尝试在 Zookeeper 中的/controller路径下创建一个临时节点。与启动时的过程类似,只有一个 Broker 能够成功创建节点并成为新的Controller。新Controller会在选举成功后接管集群元数据的管理工作。 - 更新集群元数据
新Controller在选举成功后需要更新集群元数据,包括分区状态、副本状态等。同时,新控制器会通知所有相关的 Broker 更新它们的元数据信息。这样,集群中的所有 Broker 都能够知道新Controller的身份,并进行协同工作。
注意:临时节点的特点是在创建它的客户端(即 Broker节点)断开连接时,它会自动被 Zookeeper 删除。这种机制保证了只有一个Broker节点能够成为控制器,以避免多个控制器同时对集群元数据进行操作引发的问题。

3. 故障转移
在 Kafka 集群运行过程中,只能有一台 Broker 充当控制器的角色,那么这就存在单点失效(Single Point of Failure)的风险,Kafka 是如何应对单点失效的呢?答案就是,为控制器提供故障转移功能,也就是说所谓的 Failover。
故障转移指的是,当运行中的控制器突然宕机或意外终止时,Kafka 能够快速地感知到,并立即启用备用控制器来代替之前失败的控制器。这个过程就被称为 Failover,该过程是自动完成的,无需你手动干预。
接下来,我们一起来看一张图,它简单地展示了控制器故障转移的过程。
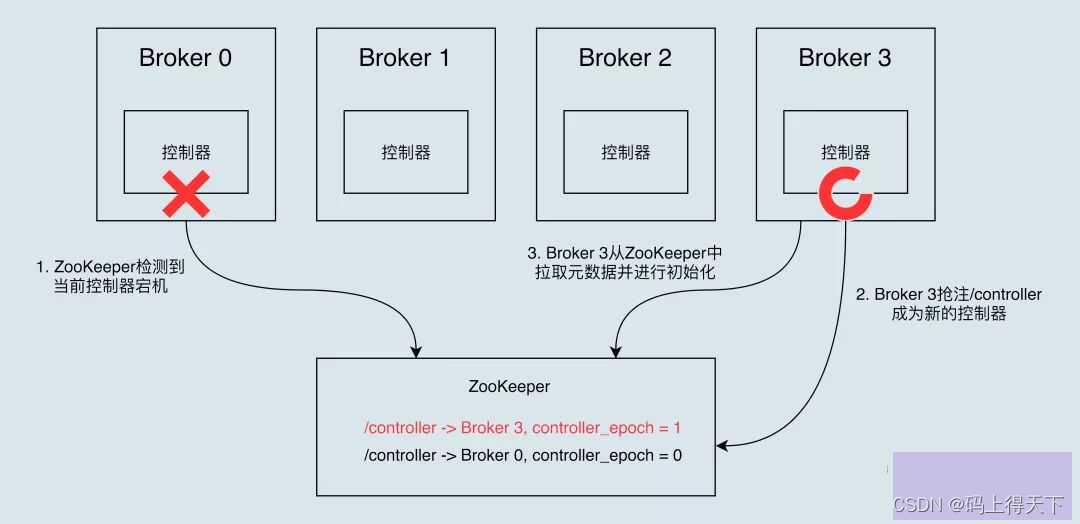
最开始时,Broker 0 是控制器。当 Broker 0 宕机后,ZooKeeper 通过 Watch 机制感知到并删除了 /controller 临时节点。之后,所有存活的 Broker 开始竞选新的控制器身份。Broker 3 最终赢得了选举,成功地在 ZooKeeper 上重建了 /controller 节点。之后,Broker 3 会从 ZooKeeper 中读取集群元数据信息,并初始化到自己的缓存中。至此,控制器的 Failover 完成,可以行使正常的工作职责了。
4. Kafka脑裂问题
脑裂问题是分布式系统中经常出现的现象,Kafka脑列问题是由于网络或其他原因导致多个Broker认为自己是Controller,从而导致元数据不一致和分区状态混乱的问题。
Kafka是通过epoch number(纪元编号)来解决脑裂问题,epoch number是一个单调递增的版本号。
脑裂问题产生和处理过程如下:
- 假设有三个Broker,分别是Broker 0,Broker 1和Broker 2。Broker 0是Controller,它在ZooKeeper中创建了/controller节点,并设置epoch number值为1。Broker 1和Broker 2在/controller节点设置了Watcher。
- 由于某种原因,Broker 0出现了Full GC,导致它与ZooKeeper的会话超时。ZooKeeper删除了/controller节点,并通知Broker 1和Broker 2进行新的Controller选举。
- Broker 1和Broker 2同时尝试在ZooKeeper中创建/controller节点,假设Broker 1成功了,那么它就成为了新的Controller,设置epoch number值为2,并向Broker 2同步数据。
- Broker 0的Full GC结束后,继续向Broker 1和Broker 2同步数据,Broker 1和Broker 2接收到数据后,发现epoch number小于当前值,就会拒绝这些消息。并通知Broker 0最新的epoch number,然后Broker 0发现自己已经不是Controller了,最后与新的Controller建立连接。

5. 总结
本文详细介绍了Kafka Controller的作用和故障转移过程,以及Kafka是怎么解决脑裂问题的。下篇文章再一块学一下Kafka分区的Leader Replica的选举过程。














 9008
9008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









