






半监督学习介绍
Zhu X, Goldberg A B. Introduction to semi-supervised learning[J]. Synthesis lectures on artificial intelligence and machine learning, 2009, 3(1): 1-130.
链接半监督
无监督学习:主要目的是从独立同分布采样中得到的n个独立样本中找到intresting的结构
监督学习:从给定的一组训练集(x,y)中学习从x到y的映射,训练集也属于独立同分布,学到的映射可由测试集评估。当y属于实数集或者一般说当y连续时,为回归任务。当y的值属于有限集(离散标签),为分类任务。监督学习中有两种算法:生成算法、判别算法
半监督学习:介于监督学习和无监督学习之间。除了标签数据还有些监督信息,一般来说这些监督信息都是一些**样本的标签,还有些其他形式的监督信息如一些点有相同的标签这种约束信息。
关于半监督学习有人提出一种问题叫做Transductive leaning,相对还有个问题是Inductive learning
半监督学习中需要满足特定的假设
监督学习的平滑假设:如果两个点很接近,那么它们相应的输出也该如此
半监督平滑假设:如果两个点再高密度区域很接近,那么它们相应的输出也该如此。这个假设说明如果两个点由一个高密度路径相连(如属于同一聚簇),那么它们的输出也可能很接近。 另一方面来说,如果它们被一个低密度区分离,那他们的输出不应该接近。
聚类假设:如果样本属于同一聚簇,那么它们极可能属于同一类。需注意聚类假设并不意味着一个类对应一个紧凑的簇,通常只能说明我们没有观察到两个不同类别的样本在同一簇中。
考虑到聚簇是一堆在高密度区域相连的点,聚类假设可以看作半监督平滑假设的一个特例。聚簇假设可以以同样的形式表达: 低密度分离(即决策边界应位于低密度区域)。
尽管聚类假设和低密度分概念上相等但是它们可以激发不同的算法。
流行假设:(高维)数据(大致)位于一个低维流形上
深度半监督学习综述
Ouali Y, Hudelot C, Tami M. An Overview of Deep Semi-Supervised Learning[J]. arXiv preprint arXiv:2006.05278, 2020.pdf
1. Introduction
半监督(SSL)在深度学习领域的研究面临的情境,大多是少量标签样本和大量无标签样本。其中无标签信息能提供一些关于数据分布结构的额外信息,以便更好地估计不同类别的决策边界。
SSL算法的分类:
一致性正则化(一致性训练)
代理标签方法:这种方法利用有标签数据集的训练模型,根据一些启发式方法标记无标签数据集的实例,从而产生额外的训练示例。这种方法的一些例子包括自训练、协同训练、多视图训练
生成模型:
基于图的方法:标签数据和无标签数据被看作途中的顶点,其目标是通过两个点间的相似性将标签数据的标签传递给无标签数据。
除了以上类别,还有些熵最小化的研究。
SSL方法基于两种主要学习范式还分为transductive learning 和 inductive learning。
Transductivel learning 是训练好的分类器应用在训练时观察到的无标签示例上。
Inductive learning 目的是学习一个在测试时能够泛化到未观察到的实例的分类器
1.5 SSL评估方法
1、有相同的结构和实验细节(超参数、参数初始化、数据增强、正则化等)
2、高质量的监督基准算法(仅用有标签训练的模型的最优表现)
3、与迁移学习对比(在大量有标签数据集上训练在已知标签数据集上微调)
4、 考虑类别分步不匹配??
5、不同大小的有标签数据和无标签数据
6、
2 一致性正则化
方法:Ladder Networks、pi-Model、Temporal Ensembling、Mean teachers、Dual Students、Fast-SWA、Virtual Adversarial Training、Adversarial Dropout、Interpolation Consistency Training、Unsupervised Data Augmentation
3 熵最小化
4 代理标签方法
自训练、多视图(协同训练,tri-Training)
5 启发性方法
MixMatch、ReMixMatch、FixMatch
6 生成方法
基于变分自编码器的半监督学习:Virational Autoencoder、Variational Auxiliary Autoencoder、Infinite Variational Autoencoder
基于生成对抗网络的半监督学习:CatGAN、DCGGAN、SGAN、Feature Matching GAN、Bad GAN、Triple-GAN、BiGAN
7 基于图的半监督学习
图构建、标签传播、图嵌入、图神经网络
8 自监督的半监督学习
Yang X, Song Z, King I, et al. A Survey on Deep Semi-supervised Learning[J]. arXiv preprint arXiv:2103.00550, 2021.
该文从模型设计和无监督损失函数的角度对深度半监督学习方法的基本原理和最新进展进行了全面的综述。根据现有的方法将深度半监督聚类学习分为深度生成方法、一致性正则化方法、基于图的方法、伪标签方法和混合方法。并从损失、贡献、结构等方便面对比了这些方法。
1 introduction
根据系统的关键目标函数,可以有半监督分类,半监督聚类和半监督回归,该文定义如下:
半监督分类: 训练集中包含有标签数据和无标签数据,半监督分类目标是根据训练集训练出一个分类器,该分类器优于只在有标签数据上进行有监督训练的分类器
半监督聚类: 训练集中包含无标签样例和一些关于聚类的监督信息,半监督聚类的目标是比只用无标签数据取得更好的聚类效果。半监督聚类也成为限制性聚类???
半监督回归:训练集包含有标签样例和无标签样例,半监督回归的目标是从紧用有标签数据的回归算法提高回归算法的性能,输出是实数而不是类别标签
传统半监督学习包含生成模型、半监督支持向量机、基于图的方法和协同训练
深度半监督学习分类如下图

半监督学习目标公式

注意正则损失和无监督损失并没有严格区分开
相关概念
迁移学习:迁移学习的目的是将一个或多个源领域的知识运用于目标域以提升目标任务的性能。与半监督学习相反,迁移任务需满足训练集和测试集独立且同分布的假设,即允许运用在训练集、测试集中的域、任务和分步不同但是相关。
弱监督学习:放松了数据依赖性。有三种类型的弱监督数据:不完整的监督数据(训练集中仅有一个子集被标注,代表有半监督学习和域适应),不精确的监督数据(训练样本的标签是粗略划分的),和不准确的监督数据(所给标签不一定正确)
元学习:目的是用少量样本和以前的知识学习新的技能或者快速适用新的任务
自监督学习:利用输入数据作为监督,将学到的特征表示用于许多下游任务
3 生成方法
生成方法可以学习数据的隐藏特征来更好的建模数据。通过训练集来建模真实数据分步,在通过该分布生成数据。主要介绍了基于生成对抗网络和变分自编码器的SSL
应用及对应数据

4 一致性正则化
一致性正则化方法的核心思想是模型的输出在现实扰动下保持不变
表中有三个层面的一致性约束,1对输入数据进行加噪、随机变换或者对抗训练。2网络中可以丢弃一些层或者连接。3训练过程来看,我们可以使用SWA使SGD拟合一些训练时期的一致性训练或模型的EMA参数作为新的参数???
方法、扰动技术

5 基于图
根据大多数基于图的方法可以分为两大类:图正则化和图嵌入。前者用拉普拉斯正则化,假设强连接的点具有相同的标签如Label propagation(LP),Gaussian random fileds(GRF)、Local and Global Consistency(LGC)。后一种的主要目标是将节点编码为表示其角色和其邻域结构信息的小尺度向量。
作者将图嵌入根据是否用深度学习分为浅层嵌入和深度嵌入。浅层嵌入包括Deep Walk、LINE、node2vec。深度嵌入可分为基于自编码器的和基于图神经网络的方法
6 伪标签方法
6.1基于分歧的方法
协同训练框架假设数据集中的每个数据x都有两个不同且互补的视图,每个视图都足以训练出一个好的分类器。协同训练在这两个视图上学习两个不同的分类器,然后应用这两个分类器预测每个视图的未标记数据,并为另一个模型标记最自信的候选人。这个过程迭代地重复,直到未标记的数据被耗尽,或者满足某些条件
tri-net tri-training:三个分类器结合深度学习
6.2 自训练方法利用模型自己自信的预测为未标记的数据生成伪标签。
7 混合方法
Gong, Chen, et al. “Semi-supervised classification with pairwise constraints.” Neurocomputing 139 (2014): 130-137.
半监督学习广泛应用于大量仅有少量标签数据和大量无标签数据的场景。无标签数据虽然没有具体标签,但是隐含了一些数据分布的先验知识。运用这些无标签数据需要选定恰当的假设,不然会有损分类结果。常用的假设有聚类假设和流行假设。聚类假设认为不同类别的样本形成分离的聚簇,在特征空间中决策边界位于低密度区域。流行假设认为数据分布的几何形状通常由低层的流行支持。流行可以被描述为图,其中样本为顶点,样本间的相似度由边的权重表示。因此,流行假设需要标签在图上平滑的变换,也就是说,两个样本联系紧密,更倾向于由相同的标签。受启发于流行假设,很多基于图的半监督算法被提出。作者提出一种半监督算法同时考虑相似和不相似的约束。
第一步: 建立传统无符号,权重非负的图。往往稀疏图能达到更好的性能,所以采用的是KNN图。
权重计算(采用RBF核)
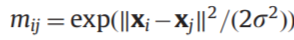
得到邻接矩阵,计算对角阵
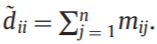
然后对邻接矩阵进行标准化:
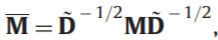
因此
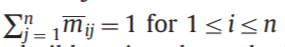
第二步:根据上面标准化后的邻接矩阵以及先验信息正负约束对,创建一个有符号的图。
其中根据已知标签可以得到的约束对如下:
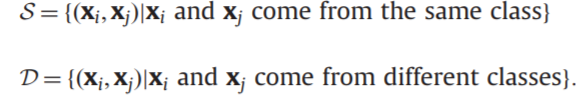
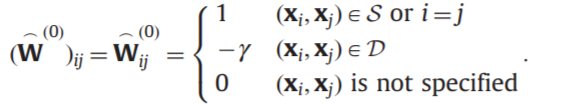
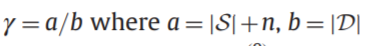
目的是为了从已知有限的约束对扩展到未知标签之间的相似关系,文中称为“平衡约束传播”
传播方法:
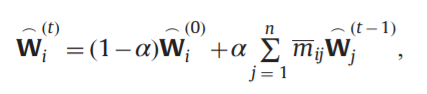
结构正则化公式
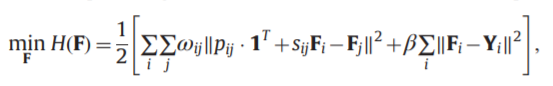
Y初始的真实标签,F最终的软分类向量















 6625
6625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









