







Linux下Hadoop2以上版本安装配置
对于初学者的我来说,不适用linux命令配置hadoop,所以用的是linux桌面,这是我还不容易配置成功的一次,赶快记录下来:
- 确认IP是否设置正常
- 安装 VM tools
- 安装hadoop
- 配置环境变量
- Hadoop配置文件修改
- 关闭防火墙
- 格式化HDFS,生成namenode和datanode
- 启动HDFS和MapReduce
- 遇到的问题汇总
确认IP是否设置正常
输入 ifconfig,如果正常显示ip说明一切正常。(这里的IP跟前章设置的IP不一样)

安装 VM tools
安装vm tools 是为了可以将本机的hadoop压缩包直接用CV大法就可以粘到虚拟机的linux中。
1,选择 虚拟机 菜单的 安装虚拟机tools。
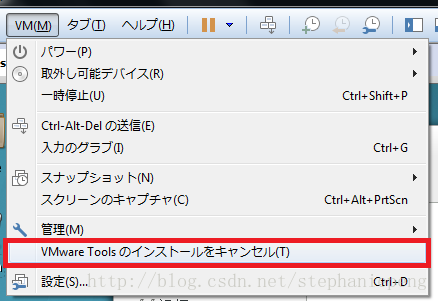
2,出现了一个窗口,选择 使用文件打开。
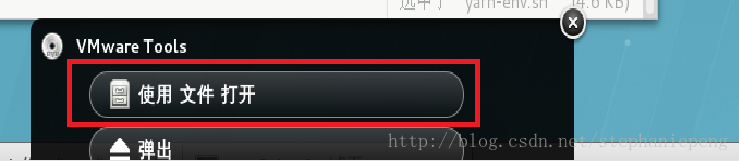
3,这时候自动跳出一个目录,里面有个压缩包,将这个压缩包拷到本地目录。
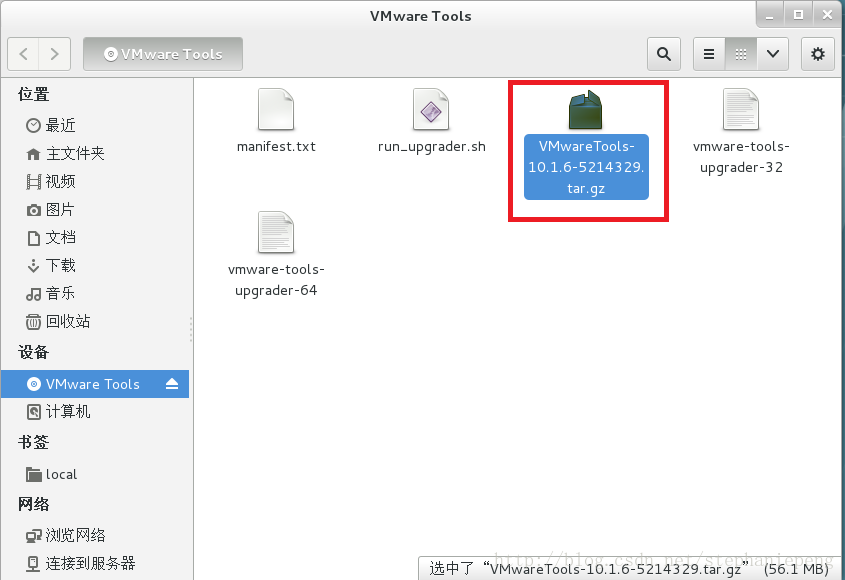
4,将拷到本地的vmware-tools-distib压缩包解压。
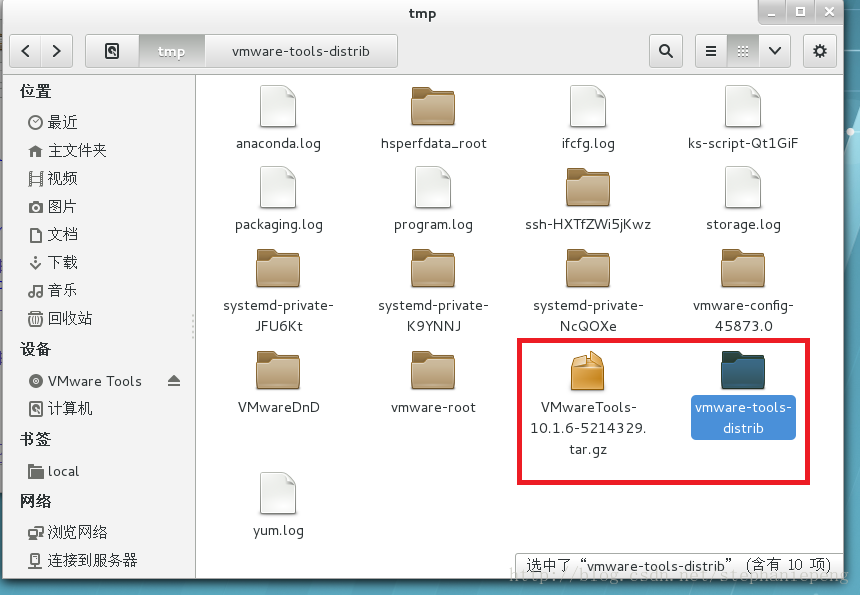
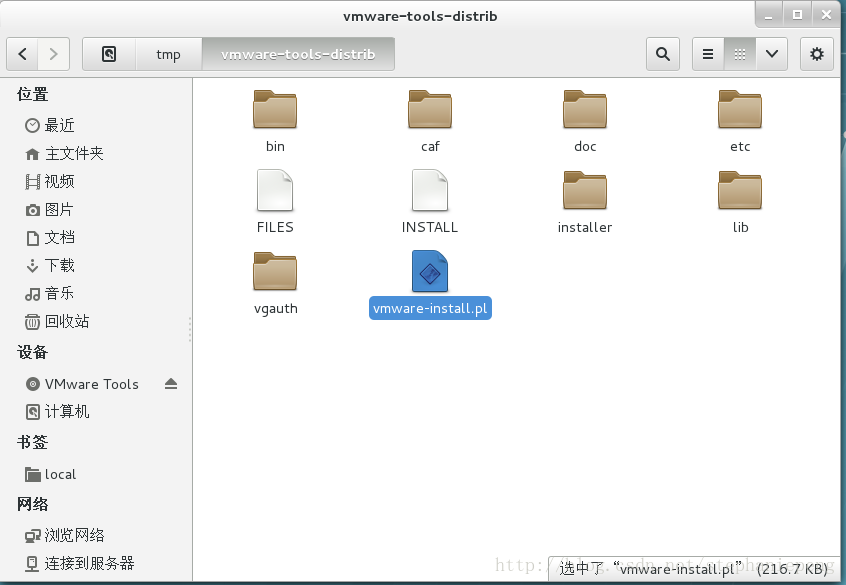
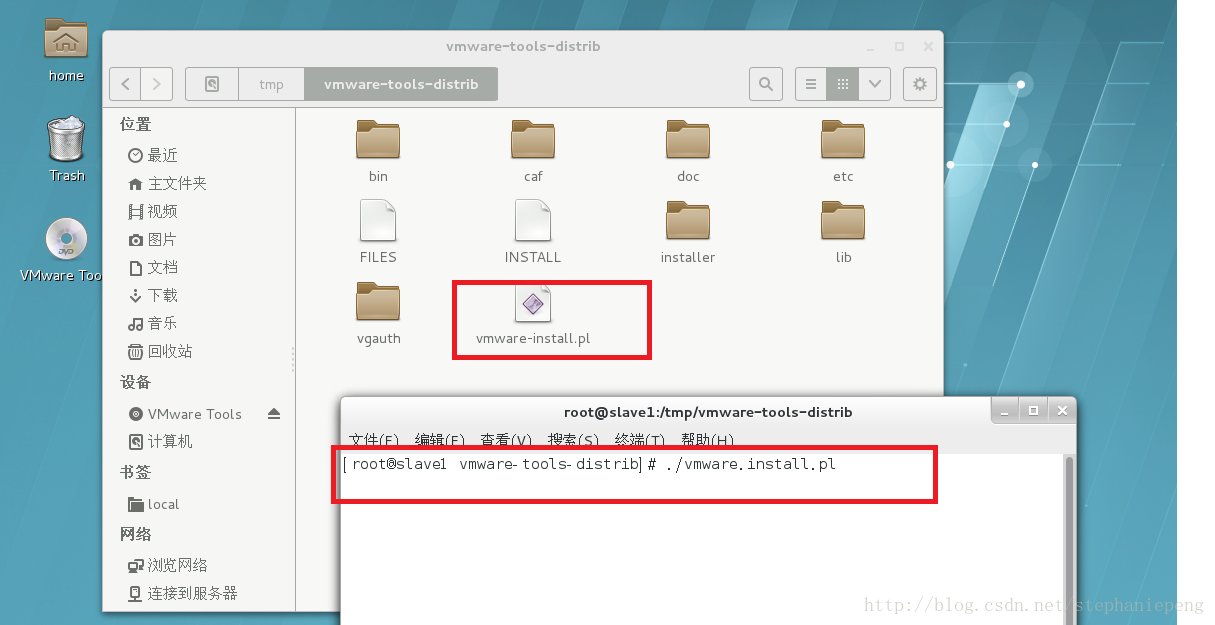
5,找到 vmware-install.pl文件,鼠标右键,打开linux终端,输入
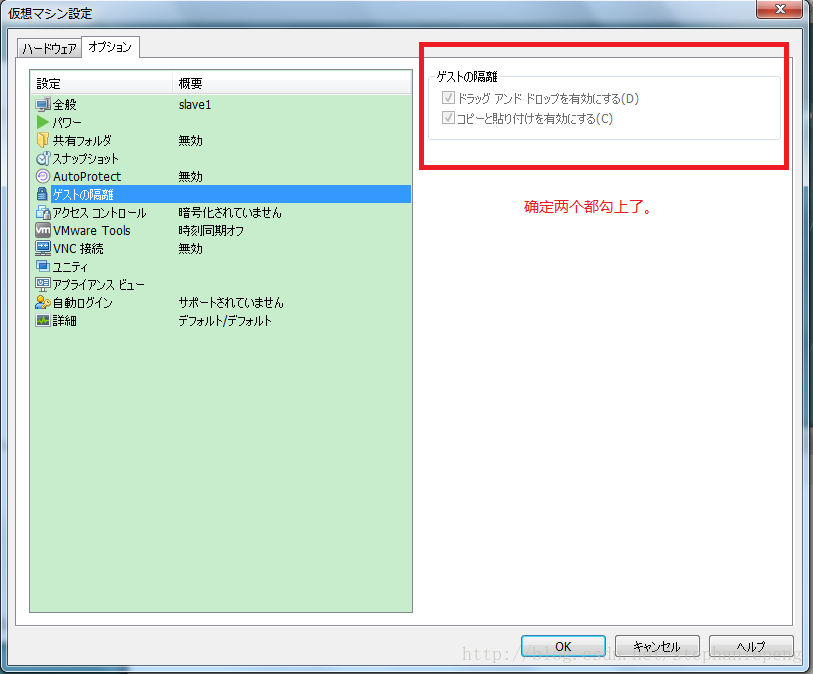
./vmware-install.pl后,点击回车。就开始安装,之后就是回车,yes就行。然后重启linux系统,就可以从本机复制文件到虚拟机中的linux系统中。(注意,要确定两个设定,如下图)

安装hadoop
(1)从官网下载hadoop包 地址:
https://dist.apache.org/repos/dist/release/hadoop/common/
我用的是:hadoop-2.8.0.tar.gz 这个版本的。
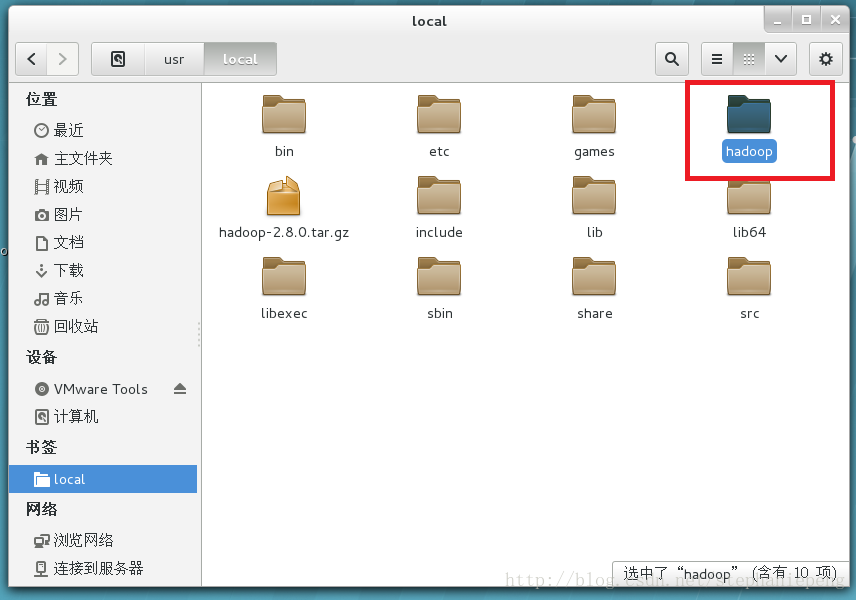
(2)将下载的hadoop压缩包,复制粘贴到虚拟机的linux中:
放到了目录:/usr/local 文件夹中,并且解压,命名为hadoop文件夹。
配置环境变量
(1)文件夹/ect中,有个profile文件,点击右键,选择编辑器,进行内容添加 :
由于我装linux的时候,选上了装jdk的选项,所以无需另外安装jdk。
在最后加上:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin(2)文件夹/usr/local/hadoop/etc/hadoop中,有个mapred-env.sh和yarn-env.sh以及hadoop-env.sh文件,点击右键,选择编辑器,进行内容添加 :
这两个文件,都加上:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0(3)执行 source /etc/profile 命令,生效环境变量 :
source /etc/profile接着分别输入,确认环境变量时候配置进去:
echo $JAVA_HOME
echo $HADOOP_HOME
echo $PATH最后输入,确认环境变量是否配置成功:
java -version
hadoop version
成功后,如图显示:
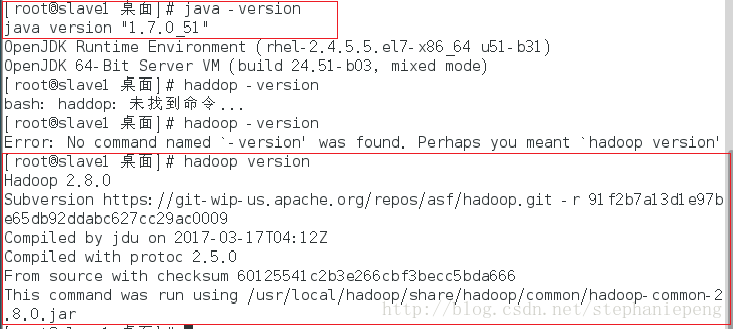
Hadoop配置文件修改
所有的配置文件在目录:
/usr/local/hadoop/ect/hadoop中。
core_site.xml修改 :
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.248.131:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hdfs_site.xml修改 :
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/hdfs/data</value>
</property>
</configuration>
mapred_site.xml修改 :
<configuration>
<property>
<name>mapreduce.jobtracker.address</name>
<value>192.168.248.131:9001</value>
</property>
<property>
<name>mapreduce.cluster.local.dir</name>
<value>file:/usr/local/hadoop/temp/mapred/local</value>
</property>
<property>
<name>mapreduce.jobtracker.system.dir</name>
<value>file:/usr/local/hadoop/temp/mapred/system</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn_site.xml 用于hadoop2.0以上版本修改 :
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
</configuration>
关闭防火墙
由于我用的是红帽的Linux,所以如下:
1)立即关闭,并非永久关闭
service iptables stop
systemctl stop firewalld
2)永久关闭
iptables -F 关闭防火墙功能
chkconfig iptables off 禁止防火墙启动
systemctl disable firewalld
3)查看时候关闭成功
systemctl status firewalld
*另外,运行 setup 在界面,选择Firewall configuration,进入下一界面,选择 Security Level为Disabled,保存。
配置SSH,实现无密码登陆(由于是伪分布式部署,则需要配置SHH,独立和分布式忽略)
1)确认是否已经安装SSH,输入 ssh localhost。如出现让你输入密码的提示,说明成功安装SSH。
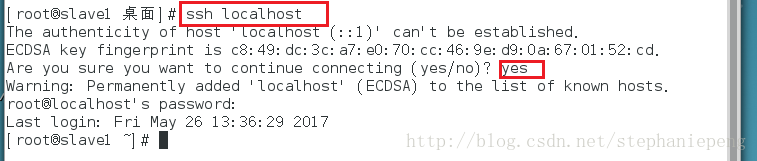
2) 执行 下方命令,创建RSA公钥
ssh-keygen -t rsa执行结果如下:
[root@slave1 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
ab:ca:b1:c1:f3:ea:7e:6b:89:13:f4:58:e1:fc:44:cc root@slave1
The key's randomart image is:
+--[ RSA 2048]----+
| o |
| . E |
| o o |
| . + . |
| . + oS |
| .o . .. |
| =o .. |
| .o*+. |
| oB*+. |
+-----------------+
3)生成私钥匙:
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys验证是否成功可以输入:ssh localhost
看是否提示需要输入密码,不提示,说明成功。
格式化HDFS,生成namenode和datanode.
hadfs namenode -format
如果执行失败的话,删除上面配置文件指定namenode.dir和datanode.dir目录中的文件。再执行一次。
启动HDFS和MapReduce
注意,下方的命令没有空格。
启动HDFS: start-dfs.sh
启动MapReduce: start-yarn.sh
停止则是将 start 换成 stop。
遇到的问题汇总:
1) 50070无法打开:
先确定防火墙是否成功关闭,如果防火墙关闭的话,确认你的配置文件是否有些错的地方。
确认文件配置没有问题后,确认本机上网是否用的代理(本人就坑在这里,电脑上网用的代理,ping能ping通地址,不知道为啥就是地址栏访问,无法访问,关闭代理,就成功了)。
可用:jps 命令,查看是否成功生成namenode和datanode.
2)无法正常关闭HDFS和YARN:
由于Hadoop默认会把PID文件放入/tmp目录下,而该目录每240小时就会自动清除,Hadoop无法找到PID文件。
需要重新指定HDFS和YARN的PID文件保存位置。
在 hadoop-env.sh文件开头加入
export HADOOP_PID_DIR=/usr/local/hadoop/pids在 yarn-env.sh文件开头加入
export HADOOP_PID_DIR=/usr/local/hadoop/pids重启hadoop,可以看到指定的目录下生成了PID。
2)重新 format namenode以后,启动hadoop,输入jps,datanode没有启动解决:
删除hadoop存放namenode和datanode的tmp文件夹,这个是上面配置文件中,自己指定的路径。(这是很野蛮的解决方式,试试自己玩玩用,因为真正的项目,你删了,项目就没啦)
由于format namenode以后,namenode的namenodeID变化,与datanode中的namenodeID不一致,修改Datanode上的namenodeID(位于/dfs/data/current/VERSION文件中)或修改NameNode的namespaceID(位于/dfs/name/current/VERSION文件中),使其一致。















 1750
1750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









