







 本文介绍了Python中Urllib模块的基本使用方法,包括发送GET和POST请求、处理请求超时及如何避免被目标网站识别为爬虫等内容。
本文介绍了Python中Urllib模块的基本使用方法,包括发送GET和POST请求、处理请求超时及如何避免被目标网站识别为爬虫等内容。
发送get请求
get请求可以不用附带任何的信息,直接发送即可
import urllib.request
import urllib.parse
response = urllib.request.urlopen("https://www.baidu.com")
print(response.read().decode("utf-8")) # utf-8可以让返回的内容不会乱码
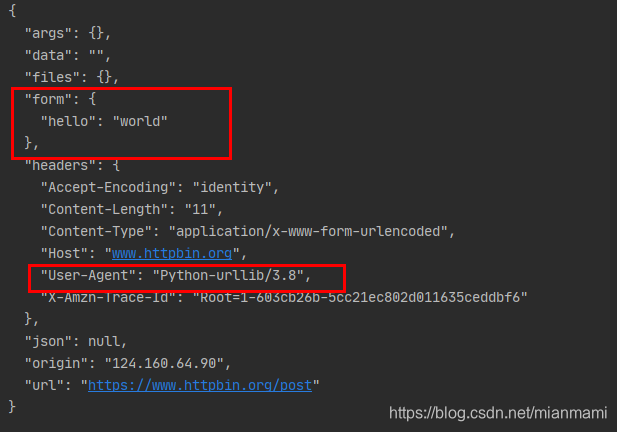
发送post请求
post请求需要发送一个用户的表单进行加密(这个post请求暂时不是很理解,后期再改)
post端会有一个获取请求后的反应,例子中用,这个网站用于模拟服务器对post请求的反应。
# 人为定义一个表单请求的信息,这里假设包含的是二进制的信息,里面是一些键值对,例如用户名:密码等
# urllib.parse对键值对按照 utf-8 的格式进行解析
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({"hello":"world"}), encoding="utf-8")
response = urllib.request.urlopen("https://www.httpbin.org/post", data=data)
print(response.read().decode("utf-8"))
能看得网站能识别到是爬虫在模拟人的登录
发送请求超时处理
加下timeout进行显示,嵌套try except
import urllib.request
import urllib.parse
try:
response = urllib.request.urlopen("https://www.httpbin.org/get", timeout=0.01)
print(response.read().decode("utf-8"))
# 还可以获得一些用户,网站的其他信息
print(response.status)
print(response.getheaders())
except Exception as e:
print("Time out!")
避免被网站识破
如果直接利用爬虫爬取,有些网站会识破你是python的程序在爬取,所以需要对请求进行封装。
关键在于将header改为自己的浏览器
import urllib.request
import urllib.parse
url = "https://www.douban.com"
data = bytes(urllib.parse.urlencode({"hello":"world"}), encoding='utf-8')
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36"
}
req = urllib.request.Request(url=url, data=data, method='POST', headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









