






目录
我们已经讨论了PostgreSQL索引引擎、访问方法的接口,以及主要的访问方法,例如:哈希索引、B树、GiST、SP GiST和GIN。在本文中,我们将观察杜松子酒如何变成朗姆酒(GIN如何变成RUM的)。
RUM
尽管作者声称GIN是一种强大的精灵,但酒类的主题最终赢得了胜利:下一代GIN被称为RUM(朗姆酒)。
这种访问方法扩展了GIN的基本概念,使我们能够更快地执行全文搜索。在本系列文章中,这是标准PostgreSQL交付中未包含的唯一方法,也是一个外部扩展。有几种安装选项可供选择:
- 从PGDG存储库获取“yum”或“apt”包。例如,如果您是从“PostgreSQL-10”软件包中安装PostgreSQL的,请同时安装“PostgreSQL-10-rum”。
- 从github上的源代码构建并自行安装(说明也在那里)。
- 作为Postgres Pro Enterprise的一部分使用(或至少阅读其中的文档)。
GIN的局限性
RUM能让我们超越GIN的哪些局限性?
首先,“tsvector”数据类型不仅包含词素,还包含它们在文档中的位置信息。正如我们上次观察到的,GIN索引不存储这些信息。因此,GIN索引对9.6版中出现的短语搜索操作的支持效率很低,必须访问原始数据进行重新检查。
其次,搜索系统通常会返回按相关性排序的结果(不管这意味着什么)。为此,我们可以使用排序函数“Tsu rank”和“Tsu rank_cd”,但它们必须针对结果的每一行进行计算,这当然很慢。
在第一种近似情况下,RUM访问方法可以被视为GIN,它额外存储位置信息,并可以按需要的顺序返回结果(就像GiST可以返回最近的邻居一样)。让我们一步一步来。
短语搜索
全文搜索查询可以包含考虑词素之间距离的特殊运算符。例如,我们可以找到文件,其中“手”与“大腿”之间用另外两个词隔开:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@
to_tsquery('hand <3> thigh');
?column?
----------
t
(1 row)或者我们可以指定单词必须连续:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@
to_tsquery('hand <-> slap');
?column?
----------
t
(1 row)常规GIN索引可以返回包含这两个词素的文档,但我们只能通过查看tsvector来检查它们之间的距离:
postgres=# select to_tsvector('Clap your hands, slap your thigh');
to_tsvector
--------------------------------------
'clap':1 'hand':3 'slap':4 'thigh':6
(1 row)
在RUM索引中,每个词素不只是引用表中的行:每个TID都提供了该词素在文档中出现的位置列表。这就是我们如何设想在“slit-sheet”表上创建的索引,我们已经非常熟悉该表(默认情况下,tsvector使用“rum_tsvector_ops”操作符类):
postgres=# create extension rum;
postgres=# create index on ts using rum(doc_tsv);图中的灰色方块包含添加的位置信息:
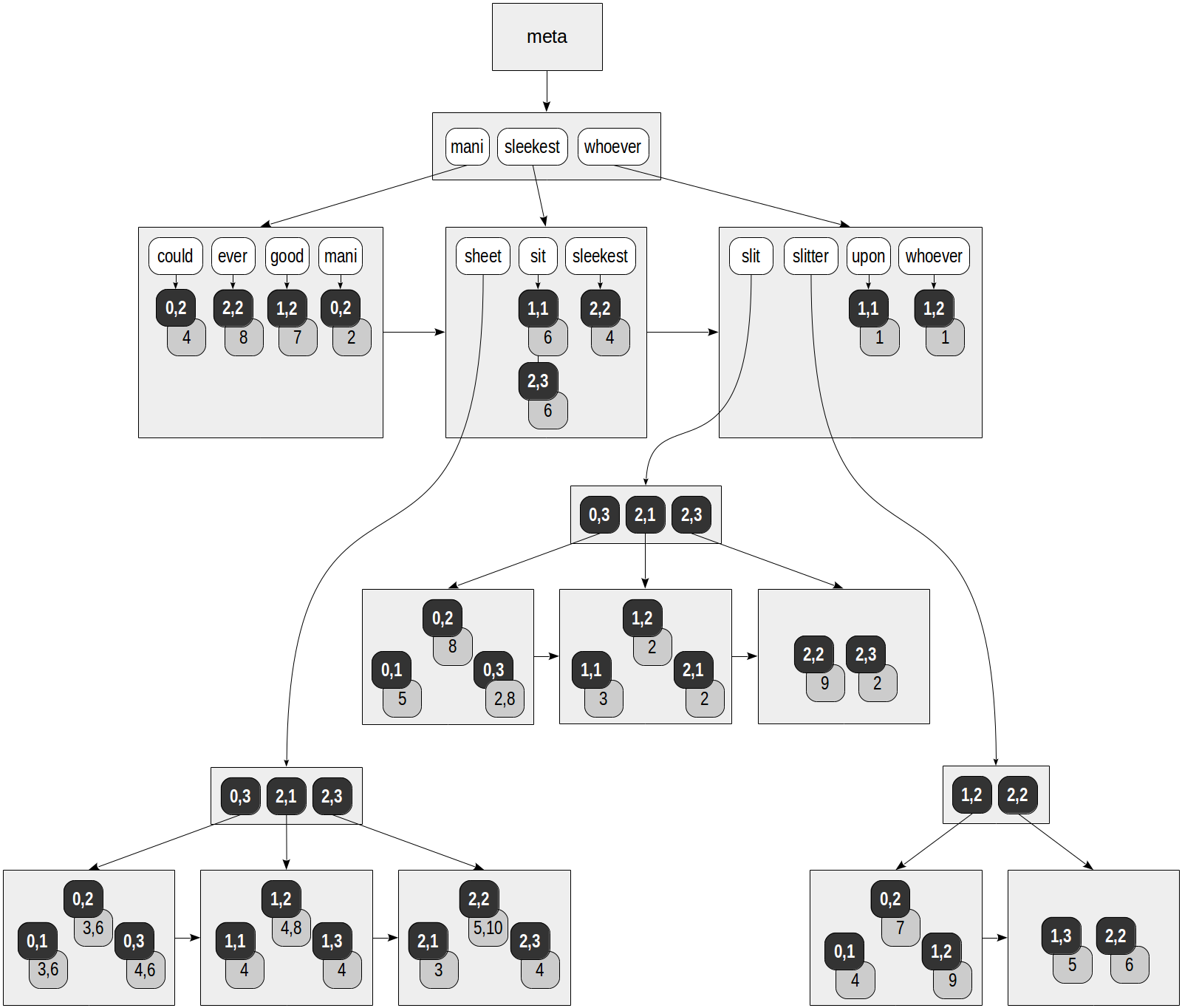
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv
-------+----------------------+---------------------------------------------------------
(0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4
(0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7
(0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8
(1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1
(1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1
(1,3) | I am a sheet slitter | 'sheet':4 'slitter':5
(2,1) | I slit sheets. | 'sheet':3 'slit':2
(2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6
(2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2
(9 rows)当指定“fastupdate”参数时,GIN还提供延迟插入;此功能已从RUM中删除。
要了解该索引如何处理实时数据,让我们使用熟悉的pgsql-hackers邮件列表。
fts=# alter table mail_messages add column tsv tsvector;
fts=# set default_text_search_config = default;
fts=# update mail_messages
set tsv = to_tsvector(body_plain);
...
UPDATE 356125以下是如何使用GIN索引执行使用短语搜索的查询:
fts=# create index tsv_gin on mail_messages using gin(tsv);
fts=# explain (costs off, analyze)
select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN
---------------------------------------------------------------------------------
Bitmap Heap Scan on mail_messages (actual time=2.490..18.088 rows=259 loops=1)
Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text))
Rows Removed by Index Recheck: 1517
Heap Blocks: exact=1503
-> Bitmap Index Scan on tsv_gin (actual time=2.204..2.204 rows=1776 loops=1)
Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text))
Planning time: 0.266 ms
Execution time: 18.151 ms
(8 rows)正如我们从计划中看到的,使用了GIN索引,但它返回1776个潜在匹配,其中259个剩余,1517个在重新检查阶段被删除。
让我们删除GIN索引并构建RUM。
fts=# drop index tsv_gin;
fts=# create index tsv_rum on mail_messages using rum(tsv);索引现在包含了所有必要的信息,并且可以准确地执行搜索:
fts=# explain (costs off, analyze)
select * from mail_messages
where tsv @@ to_tsquery('hello hackers');
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on mail_messages (actual time=2.798..3.015 rows=259 loops=1)
Recheck Cond: (tsv @@ to_tsquery('hello hackers'::text))
Heap Blocks: exact=250
-> Bitmap Index Scan on tsv_rum (actual time=2.768..2.768 rows=259 loops=1)
Index Cond: (tsv @@ to_tsquery('hello hackers'::text))
Planning time: 0.245 ms
Execution time: 3.053 ms
(7 rows)按相关性排序
为了按照所需的顺序方便地返回文档,RUM索引支持排序运算符,我们在GiST相关文章中讨论了这一点。RUM扩展定义了这样一个操作符,<=>,它返回文档(“tsvector”)和查询(“tsquery”)之间的距离。例如:
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=>l to_tsquery('slit');
?column?
----------
16.4493
(1 row)
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=> to_tsquery('sheet');
?column?
----------
13.1595
(1 row)与第二个查询相比,文档似乎与第一个查询更相关:单词出现的频率越高,它的“价值”就越低。
让我们再次尝试在相对较大的数据量上比较GIN和RUM:我们将选择十个最相关的文档,其中包含“hello”和“hackers”。
fts=# explain (costs off, analyze)
select * from mail_messages
where tsv @@ to_tsquery('hello & hackers')
order by ts_rank(tsv,to_tsquery('hello & hackers'))
limit 10;
QUERY PLAN
---------------------------------------------------------------------------------------------
Limit (actual time=27.076..27.078 rows=10 loops=1)
-> Sort (actual time=27.075..27.076 rows=10 loops=1)
Sort Key: (ts_rank(tsv, to_tsquery('hello & hackers'::text)))
Sort Method: top-N heapsort Memory: 29kB
-> Bitmap Heap Scan on mail_messages (actual ... rows=1776 loops=1)
Recheck Cond: (tsv @@ to_tsquery('hello & hackers'::text))
Heap Blocks: exact=1503
-> Bitmap Index Scan on tsv_gin (actual ... rows=1776 loops=1)
Index Cond: (tsv @@ to_tsquery('hello & hackers'::text))
Planning time: 0.276 ms
Execution time: 27.121 ms
(11 rows)GIN index返回1776个匹配项,然后执行单独的排序步骤,以选择十个最佳匹配项。
使用RUM index,使用简单的索引扫描执行查询:不需要查看额外的文档,也不需要单独排序:(因为是精确查询,所以不需要重新检查;因为rum索引会根据"附加信息"——距离来组织索引项,所以不需要排序)
fts=# explain (costs off, analyze)
select * from mail_messages
where tsv @@ to_tsquery('hello & hackers')
order by tsv <=> to_tsquery('hello & hackers')
limit 10;
QUERY PLAN
--------------------------------------------------------------------------------------------
Limit (actual time=5.083..5.171 rows=10 loops=1)
-> Index Scan using tsv_rum on mail_messages (actual ... rows=10 loops=1)
Index Cond: (tsv @@ to_tsquery('hello & hackers'::text))
Order By: (tsv <=> to_tsquery('hello & hackers'::text))
Planning time: 0.244 ms
Execution time: 5.207 ms
(6 rows)附加信息
RUM索引,以及GIN,可以建立在几个字段上。但是,虽然GIN存储每一列的词素独立于另一列的词素,但RUM使我们能够将主字段(“本例中的tsvector”)与另一个字段“关联”(就是根据另一个可排序的字段来组织索引项,而默认是使用距离排序的)。为此,我们需要使用专门的运算符类“rum_tsvector_addon_ops”:
fts=# create index on mail_messages using rum(tsv RUM_TSVECTOR_ADDON_OPS, sent)
WITH (ATTACH='sent', TO='tsv');我们可以使用此索引返回按附加字段排序的结果:
fts=# select id, sent, sent <=> '2017-01-01 15:00:00'
from mail_messages
where tsv @@ to_tsquery('hello')
order by sent <=> '2017-01-01 15:00:00'
limit 10;
id | sent | ?column?
---------+---------------------+----------
2298548 | 2017-01-01 15:03:22 | 202
2298547 | 2017-01-01 14:53:13 | 407
2298545 | 2017-01-01 13:28:12 | 5508
2298554 | 2017-01-01 18:30:45 | 12645
2298530 | 2016-12-31 20:28:48 | 66672
2298587 | 2017-01-02 12:39:26 | 77966
2298588 | 2017-01-02 12:43:22 | 78202
2298597 | 2017-01-02 13:48:02 | 82082
2298606 | 2017-01-02 15:50:50 | 89450
2298628 | 2017-01-02 18:55:49 | 100549
(10 rows)在这里,我们搜索尽可能接近指定日期的匹配行,无论是更早还是更晚。要获得严格在指定日期之前(或之后)的结果,我们需要使用<=|(或|=>)运算符。
正如我们所料,查询只需通过简单的索引扫描即可执行:
ts=# explain (costs off)
select id, sent, sent <=> '2017-01-01 15:00:00'
from mail_messages
where tsv @@ to_tsquery('hello')
order by sent <=> '2017-01-01 15:00:00'
limit 10;
QUERY PLAN
---------------------------------------------------------------------------------
Limit
-> Index Scan using mail_messages_tsv_sent_idx on mail_messages
Index Cond: (tsv @@ to_tsquery('hello'::text))
Order By: (sent <=> '2017-01-01 15:00:00'::timestamp without time zone)
(4 rows)如果我们在没有字段关联的附加信息的情况下创建索引,对于类似的查询,我们必须对索引扫描的所有结果进行排序。
除了日期,我们当然可以将其他数据类型的字段添加到RUM索引中。几乎所有基本类型都受支持。例如,在线商店可以按新颖性(日期)、价格(数字)和受欢迎程度或折扣值(整数或浮点)快速显示商品。
其他操作符类
为了完整性,我们应该提到其他可用的操作符类。
让我们从“rum_tsvector_hash_ops”和“rum_tsvector_hash_addon_ops”开始。它们类似于已经讨论过的“rum_tsvector_ops”和“rum_tsvector_addon_ops”,但索引存储的是词素的哈希代码,而不是词素本身(这个和gist索引中的一样)。这可以减少索引大小,但当然,搜索变得不那么准确,需要重新检查。此外,索引不再支持搜索部分匹配。
“rum_tsquery_ops”操作符类很有趣。它使我们能够解决一个“逆”问题:找到与文档匹配的查询。为什么需要这样做?例如,根据用户的筛选器订阅新商品,或自动对新文档进行分类(类似于智能推荐与AI识物)。看看这个简单的例子:
fts=# create table categories(query tsquery, category text);
fts=# insert into categories values
(to_tsquery('vacuum | autovacuum | freeze'), 'vacuum'),
(to_tsquery('xmin | xmax | snapshot | isolation'), 'mvcc'),
(to_tsquery('wal | (write & ahead & log) | durability'), 'wal');
fts=# create index on categories using rum(query);
fts=# select array_agg(category)
from categories
where to_tsvector(
'Hello hackers, the attached patch greatly improves performance of tuple
freezing and also reduces size of generated write-ahead logs.'
) @@ query;
array_agg
--------------
{vacuum,wal}
(1 row)其余的操作符类“rum_anyarray_ops”和“rum_anyarray_addon_ops”旨在操作数组,而不是“tsvector”。这一点在上一次GIN索引中已经讨论过了,无需重复。
索引和预写日志(WAL)的大小
很明显,因为RUM比GIN储存更多的信息,所以它的尺寸必须更大。我们上次比较了不同索引的大小;让我们把RUM加到这张表上:
RUM | GIN | GiST | btree
457MB | 179MB | 125MB | 546MB
正如我们所看到的,规模显著增长,这就是快速搜索的成本。
值得注意一点:RUM是一个扩展,也就是说,它可以在不修改系统核心的情况下安装。由于Alexander Korotkov的补丁,9.6版中启用了这一功能。为此必须解决的问题之一是日志记录的生成。记录操作的技术必须绝对可靠,因此,不能让扩展进入随意更改。不允许扩展创建自己类型的日志记录,而是执行以下操作:扩展的代码传达其修改页面的意图,对页面进行任何更改,并发出完成的信号,系统核心比较页面的新旧版本,并生成所需的统一日志记录。
当前的日志生成算法逐字节比较页面,检测更新的片段,并记录这些片段中的每个片段及其与页面开始的偏移量。当只更新几个字节或整个页面时,这可以正常工作。但是,如果我们在页面中添加一个片段,将其余内容向下移动(反之亦然,删除一个片段,将内容向上移动),将比实际添加或删除的字节要多得多。
因此,剧烈变化的RUM索引可能会生成比GIN大得多的日志记录(GIN不是扩展,而是核心的一部分,它自己管理日志)。这种恼人影响的程度在很大程度上取决于实际的工作负载,但为了深入了解问题,让我们尝试多次删除和添加多行,将这些操作与“vacuum”交错。我们可以按如下方式评估日志记录的大小:在开始和结束时,使用“pg_current_wal_location”函数(在10之前的版本中使用“pg_current_xlog_location”)记住日志中的位置,然后查看差异。
当然,我们应该考虑很多方面。我们需要确保只有一个用户在使用该系统(否则,“额外”记录将被考虑在内)。即使是这样,我们不仅要考虑RUM,还要考虑表本身和支持主键的索引的更新。配置参数的值也会影响大小(这里使用的是没有压缩的“副本”日志级别)。但我们还是试试吧。
fts=# select pg_current_wal_location() as start_lsn \gset
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv)
select parent_id, sent, subject, author, body_plain, tsv
from mail_messages where id % 100 = 0;
INSERT 0 3576
fts=# delete from mail_messages where id % 100 = 99;
DELETE 3590
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv)
select parent_id, sent, subject, author, body_plain, tsv
from mail_messages where id % 100 = 1;
INSERT 0 3605
fts=# delete from mail_messages where id % 100 = 98;
DELETE 3637
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv)
select parent_id, sent, subject, author, body_plain, tsv from mail_messages
where id % 100 = 2;
INSERT 0 3625
fts=# delete from mail_messages where id % 100 = 97;
DELETE 3668
fts=# vacuum mail_messages;
fts=# select pg_current_wal_location() as end_lsn \gset
fts=# select pg_size_pretty(:'end_lsn'::pg_lsn - :'start_lsn'::pg_lsn);
pg_size_pretty
----------------
3114 MB
(1 row)因此,我们获得了大约3GB的容量(差)。但如果我们用GIN索引重复同样的实验,这将只产生大约700MB。
因此,我们希望有一种不同的算法,该算法将找到能够将页面的一种状态转换为另一种状态的最小插入和删除操作数。“diff”实用程序以类似的方式工作。Oleg Ivanov已经实现了这种算法,他的补丁正在讨论中。在上面的例子中,这个补丁使我们能够将日志记录的大小减少1.5倍,达到1900 MB,但代价是速度稍微减慢。
【不幸的是,补丁卡住了,没有任何关于它的动向。】
属性
像往常一样,让我们看看RUM访问方法的属性,注意与GIN的区别。
以下是访问方法的属性:
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
rum | can_order | f
rum | can_unique | f
rum | can_multi_col | t
rum | can_exclude | t -- f for gin以下是索引层的特性:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t -- f for gin
bitmap_scan | t
backward_scan | f请注意,与GIN不同,RUM支持索引扫描——否则,在带有“limit”子句的查询中,就不可能准确返回所需数量的结果。因此,不需要对应的“gin_fuzzy_search_limit”参数。因此,该索引可用于支持排除约束(因为是精确查询,所以可以知道一个值是否已有(而不需要重新检查),从而保证索引项的唯一性,即支持排除约束)。
以下是列层面的特性:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | t -- f for gin
returnable | f
search_array | f
search_nulls | f区别在于RUM支持排序运算符(所以,即使支持排序运算符,也不一定支持顺序/逆序输出,因为排序是按照文档相关性排序的,而顺序/逆序是指关键字之间的大小,这显然没有意义)。然而,并非所有操作符类都是如此:例如,对于“tsquery_ops”(因为这个操作符将数据转化为位图了),这是错误的。
(由于CSDN垃圾的撤销重做功能,让我终于舍弃了继续在该平台写文章的想法,下面会先在石墨文档上写,以后可能会转到其他平台,如果有好的分享记录平台的话)














 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









