







前言
最近家里事情比较多,逃了很久的更。终于找到了点时间继续写一写,好不容易坚持下来的写东西的习惯可不能半途而废了。
上一篇文章吐槽了下技术快速发展对技术人员带来的各种深远影响,但是主要是从总体上来说的,并没有细化。今天就从作者最熟悉的数据库领域来说明下技术发展带来的显著影响。曾经一家独大的数据库领域,为何在大数据时代变得英雄辈出,群雄逐鹿的。下面的知识点和干货比较多,不是很了解的同学可能消化起来比较慢,建议收藏后慢慢研究,对于后续研究数据库甚至面试还是有许多帮助的。
一家独大的RDS
数据库元年伊始,数据库的定位就是能存数据,能查数据。彼时的数据库五花八门,并没有形成统一的标准,大家都在自娱自乐。公司或者行业内部还能玩得转,但是范围稍微扩大,就会发现无数兼容和适配的问题,代码和难度巨大。
再加上日益增加的数据库需求,已经从能存数据,能查数据演变成了能高效的存数据,能快速的查数据,这使得原本就问题不断的数据库行业雪上加霜。
这种混乱的局面一直持续到了关系型数据库的出现才告一段落(下面为了描述方便,统一简称RDS)。RDS的出现使得数据库在真正意义上有了统一的标准:
-
统一的存储结构和存储方式:DataBase->Table->Row->Column
-
统一的设计标准-3NF
-
统一的查询语言-SQL
-
统一的高级数据处理-索引&视图&触发器&存储过程&函数
-
统一的事务管理模式-ACID
这一阶段催生了以Oracle、SqlServer,DB2以及Mysql为首的RDS主流公司,而上述的标准和规范是在RDS出现之后并由这些RDS公司根据实际情况和长期发展而制定的。后续的如PostgreSql也是基本上完全遵循上述标准的前提下发展出来的。
所以这一时期,虽然数据库的种类很多,但是用法以及场景基本上都一致,除了个别数据以及业务比较大,需求比较复杂的场景外,其余情况下这些数据库选型基本上都是相通的,稍微正式点的系统都有适配多种数据库的能力。
所以这个阶段,虽然数据库有好多个,但是借助于统一的标准和规范,数据库的市场可谓是RDS一家独大,而且各家的使用场景和技术架构也大同小异,整个数据库市场一片统一祥和。
RDS的阿喀琉斯之踵
如果事情按部就班发展下去,一切都很完美,很可能这就是终点了,大家精通了这几个数据库中的一个或者几个就万事大吉,高枕无忧了。
但是人算不如天算,不可避免的时代变革还是来了,尤其是移动互联网时代的到来,数据巨量膨胀,传统的RDS越来越力不从心,曾经面对大数据量的解决方案已经无法抵挡海量数据的一波波一轮轮的进攻了。
RDS面对大数据量的常规解决方案有如下两种方案:
-
硬件的纵向扩展:这个是最直接也是最简单的方式,通过增加单机的硬件资源来支撑更多的数据和业务。钱能解决的问题都不是问题,所以RDS时代小型机这种吞金兽基本上是各大银行以及运营商标配,IBM也因为小型机业务赚的盆满钵满。
-
数据分库分表:如果数据量真的大到单表或者单机无法处理的情况下怎么办呢?借鉴分治法的思想,对数据按照某一个或者几个维度进行整体的拆分,将不同的数据路由到不同的表中或者服务器上以达到负载均衡以及硬件的横向扩展。

上面两种方案从理论上来说可以解决数据不断膨胀的问题。但是理想很丰满,现实很骨干。数据分库分表看起来可以做到横向扩展,但是操作起来却不是那么的美好。
-
首先,数据按照某一维度被切分,就意味着所有的业务必须按照这个维度展开才是最合理的,如果想跨维度进行数据的聚合或者操作,操作以及通信成本大到惊人,尤其是多服务器的情况。
-
其次,随着数据规模的增大以及种类的增多,维护分库分表的路由表的工作也越来越复杂,一些细小的修改或者调整都可能引发灾难性的后果,维护成本也是高到离谱,甚至可能成为整个系统的瓶颈。
-
最后,虽然事务性可以又RDS自身的机制进行保障,但是跨表以及跨节点的事务还是需要使用者做大量的工作才能解决,成本和风险都不可控。
从上述的描述来看,RDS虽然展开了积极自救,但是在强力对手的面前显得微不足道。纵使最后RDS中的翘楚进行了最后一波反抗,试着支持分布式,最后也推出了一个“share disk”模式的非完全分布式模式的分布式解决方案链接,但是由于还是存在存储层面的性能瓶颈,所以效果并不是很好。直到云计算和云原生出现后,这种模式由于天生兼容云平台的特点而被再次“复活”,这就是后话了。
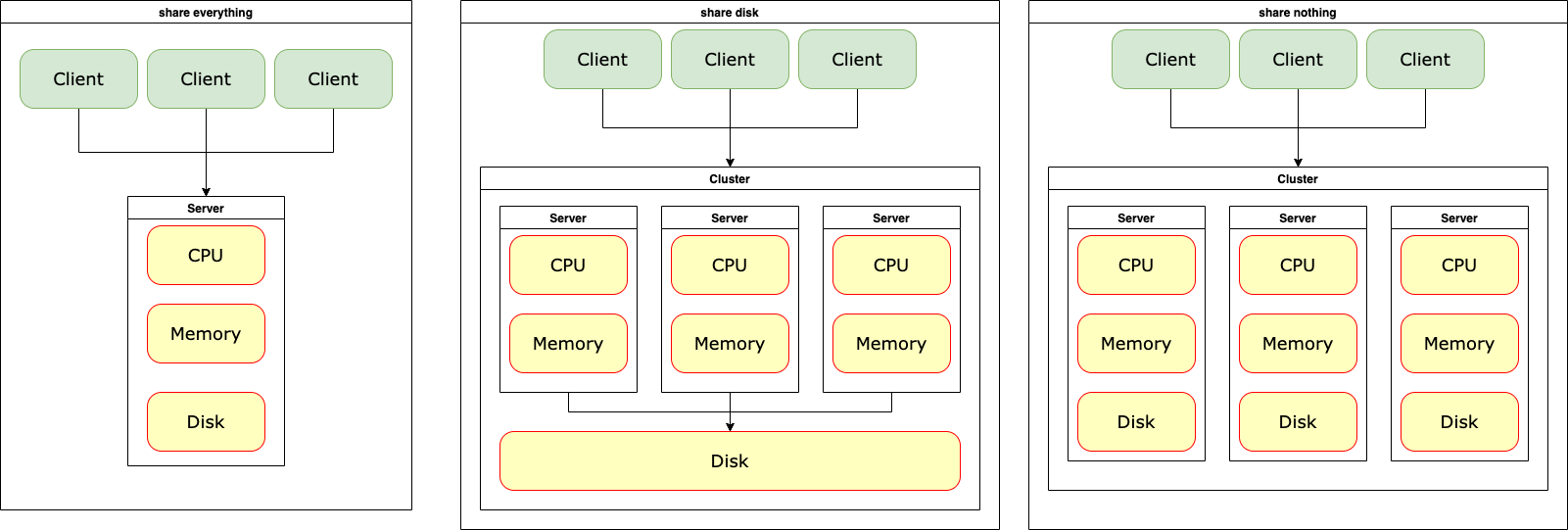
群雄逐鹿的DBS
既然的RDS的分库分表以及“share disk”模式的分布式解决方案无法彻底解决越来越多的数据存储和数据处理场景,那么完全分布式的NOSQL方案就被推到了前台,走进了大家的视野。
不同于RDS的统一标准与一家独大,NOSQL却是群雄逐鹿,各领风骚的场景,而且不断有新的数据库出现挑战老一代王者的桂冠,声声不息。
为什么同样的数据处理和存储场景到了不同的时期会有如此大的变化呢?原因自然有很多,但是主要原因不外乎下面的几种,作者试着从自己的理解来说明下这个问题:
CAP理论
这里的CAP可不是帽子的意思,而是数据库的三个特性:
Consistency:强一致性
Availability:高可用性
Partition tolerance:分区容错性
CAP理论指的是,任何一个数据库系统,最多只能同时满足三个特征中的两个。
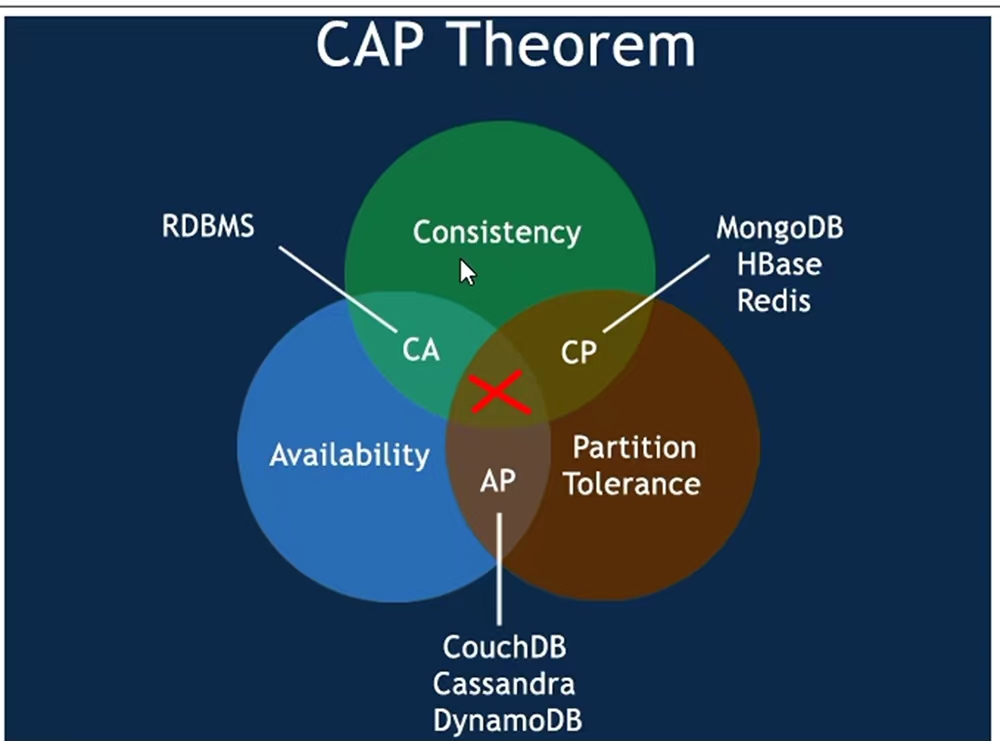
从图上可以看出RDS能同时满足高可用性和强一致性,由于不是分布式数据库所以无法支持分区容错性;而NOSQL由于都是分布式数据库,所以必须要支持分区容错性,至于差别就是AP还是CP数据库了,大家可以根据这里理论去分析下自己常用的NOSQL数据库到底是AP类型还是CP类型的数据库。
正是由于这种数据库本身的特点,才导致不同的业务场景需要使用不同的数据库,没有一个数据库可以做到覆盖所有场景,做到"One stack to rule them all"。
针对CAP理论网上的文章很多,这里就不过多阐述了,说几点网上可能不会提到或者会有误区的点吧:
-
上面在说CAP理论的时候,我特别强调了“同时”满足三个特性中的两个,这是因为很多NOSQL数据库都有对一致性的进行配置的选项,理论上可以让一个NOSQL数据库根据场景在AP与CP之间转换,使得该数据库能有更多的使用场景以及市场占有率。但是同一时刻或者统一配置下只能是AP或者CP,不能是CAP。
-
网上一些文章在介绍CAP的C以及A时用的是一致性和可用性,这个描述是不准确且容易产生歧义的。我认为准确的描述应该是高可用性和强一致性。因为一致性分为强一致性和最终一致性,很多AP数据库都能保证数据的最终一致性(比如ElaticSearch等);也有很多CP数据库也会在一定时间容忍范围内自动恢复故障进而保持可用性(如HBase等)。如果不对概念进行规约,很有可能会造成歧义进而导致大家对于CAP概念理解的偏差。
OLTP和OLAP
说完了NOSQL的特性之外,再来看看NOSQL的使用场景,当前主流的场景就是OLTP以及OLAP,下面先来看看概念:
联机事务处理(On-Line Transaction Processing,OLTP):表示事务性非常高的系统,一般都是高可用的在线系统,以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute Query的数量。典型的OLTP系统有电子商务系统、银行、证券等。
联机分析处理(On-Line Analytical Processing,OLAP):有的时候也叫DSS决策支持系统,就是我们说的数据仓库。在这样的系统中,语句的执行量不是考核标准,因为一条语句的执行时间可能会非常长,读取的数据也非常多。所以,在这样的系统中,考核的标准往往是磁盘子系统的吞吐量(带宽),如能达到多少MB/s的流量。当前绝大多数的统计分析以及辅助决策的系统绝大部分都是属于OLAP类型的。
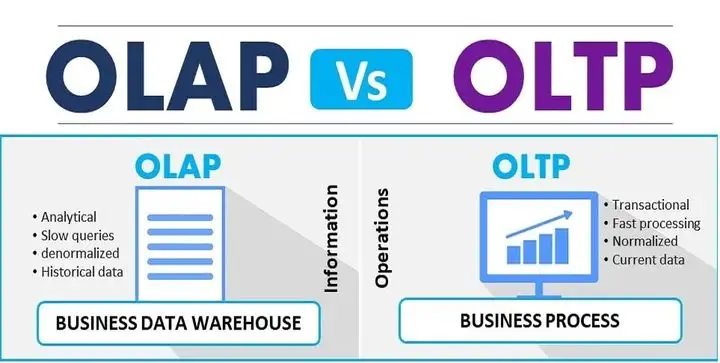
看了两者的区别我们来看一下这两个使用场景对于数据库的影响,下面直接捞干货:
存储方式的不同
-
众所周知,数据库事务通常情况下最小粒度是行级即一行数据,所以OLTP的数据库绝大多数是行存数据库,即按数据行来组织数据结构,这样便于事务的开展与管理。
-
而OLAP数据库更在意数据统计以及数据聚合的效果和性能,而数据统计和数据聚合多数情况下只需要少量的列即可,在这种情况下拿出整行数据显然是得不偿失的。所以OLAP数据库多数都是列存数据库,数据按列进行存储。另外列存数据库由于按列存储,相同数据类型的列数据压缩比更高,存储成本相对更低。
实现方式的不同
-
OLTP数据库更多看中的是吞吐量以及事务的准确性,所以难点主要集中在分布式事务上,常见的是paxos、raft以及两者相关的变种,再结合2pc以及3pc来解决复杂的分布式事务。当然如果事务仅仅控制在行级的话,也可以使用mvcc来实现。
-
OLAP数据库更多看中的是数据统计以及聚合的效果以及性能,借助于列存数据的特点,OLAP数据库往往使Vectorization(用向量化技术)利用CPU的SIMD(单指令多数据流)特点来实现高效的数据处理。
当然OLTP和OLAP数据库还有很多其他的区别,这里就不多说了,感兴趣的大家可以自己再学习下。
当然,现在有很多数据库号称技能支持OLAP,又能支持OLTP,即HTAP数据库。虽然听起来很美好,但是选型的时候也要慎重。
-
首先,这种数据库一般都是侧重于一种使用场景,而通过其他方式来单独支持另一种使用场景。所以这种架构的复杂性就无需多言了,自然学习成本也是相当可观了,如果轻易入坑,后续实际应用中很有可能就会掉进坑里出不来了。
-
其次,这种数据库一般都很吃硬件,虽然看起来是一套数据库系统,其实用这一套数据库系统的资源可能都能支撑OLAP和OLTP各一套系统的了。而且在硬件条件无法达标的前提下,很多性能指标很难达到预期,甚至让人大跌眼镜。
要问我为什么知道?那是因为我曾经感受了下TiDB的无情暴击,最后留下了一篇填坑文档后草草收场了。链接
总结来说数据存储格式的差别以及使用场景的差别再次成功的做大了NOSQL的蛋糕,使得更多的数据库有了发挥的舞台。
即席查询(AD-HOC)
最后再来说说即席查询,先来看看即席查询的概念:
即席查询是用户根据自己的需要灵活选择查询条件,系统可以根据用户的选择生成相应的统计报表或者查询结果。即时查询与普通应用查询最大的区别在于,普通应用查询是定制开发的,即席查询由用户即时定制的。

看到这里有些人可能并不是很理解即席查询和普通查询比有什么不同,举个例子来说:RDS中用来加速普通查询以及统计查询的方法有如下两种:
-
使用索引来加速数据查询
-
使用存储过程或者视图来预处理或者预统计指定维度的数据来加速统计结果的计算和查询
所以在系统设计之初会针对客户的需求对可能用到的字段增加索引来加速查询或者对相关的聚合和统计结果进行离线生成。但是有一天客户突然心血来潮要自己使用SQL查询某些结果,这时候如果用户的这次自主查询未能命中索引,那么查询和统计的效率肯定会大打折扣。
为了避免这种情况的产生传统的数据仓库有对应的解决方案来尽量较少和避免这种情况的发生。而这种情况在NOSQL的世界里同样存在,毕竟创建索引的成本很高昂,更不用说统计和聚合了。虽然说spark以及flink都有对应的SQL引擎,但是这种情况下还是无法完全满足客户对应即席查询的诉求。
这种情况下,有部分数据库开始支持即席查询(ElasticSearch、ClickHouse以及DorisDB等),按规则对数据进行全方位的索引或者管理,用以在可以接受的成本与开销下尽量满足用户的即席查询需求。
其他NOSQL数据库
除了上面几种常用的NOSQL数据库种类外,还有为了支持图计算以及机器学习而诞生的图数据库;以及方便扩展,易于部署的嵌入式数据库,这些以及其他小众的NOSQL数据库进一步盘活了大数据时代的数据库市场,真正做到了术业有专攻,百花齐放的场景。
总结
天下合久必分,分久必合;江山代有人才出,各领风骚数百年这些古语显然也适用于数据库的市场。相对于数据量迅速膨胀这个表象之外,数据类型复杂度的提升以及业务场景的细分才是当今数据库市场百花齐放的根本原因。这也是技术发展的必然,作为程序员的我们必然是痛并快乐着。在技术发展历史的洪流前,我们无力阻挡,只能顺势而为了,活到老学到老看来要真的成为程序员的座右铭了。
文章到这里就结束了,最后路漫漫其修远兮,大数据之路还很漫长。如果想一起大数据的小伙伴,欢迎点赞转发加关注,下次学习不迷路,我们在大数据的路上共同前进!














 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









