







1.术语
index(索引)
索引就像关系数据库中的表。它有一个映射,用于定义索引中的字段。
索引是一个逻辑命名空间,它映射到一个或多个主分片,并且可以有零个或更多个副本分片。
document(文档)
文档是存储在ES中的JSON文档。它就像关系数据库中表中的一行。每个文档都存储在一个索引中,并具有一个类型和一个id。
文档是一个JSON对象(在其他语言中也称为哈希/哈希映射/关联数组),它包含零个或多个字段或键值对。
id (文档唯一标识)
文档的ID标识文档。文档的索引/类型/id必须唯一。如果未提供ID,则将自动生成。
field(文档字段)
文档包含字段列表或键值对。该值可以是简单的值(例如字符串、整数、日期),也可以是嵌套结构,如数组或对象。字段类似于关系数据库中表中的列。
每个字段的映射都有一个字段类型(不要与文档类型混淆),它指示可以存储在该字段中的数据类型,例如整数、字符串、对象。映射还允许您定义(除其他外)如何分析字段的值。
mapping(映射)
映射类似于关系数据库中的表结构定义。每个索引都有一个映射,该映射定义了索引中的每个字段类型。
映射既可以显式定义,也可以在为文档编制索引时自动生成。
primary shard(主分片)
每个文档都存储在一个主分片中。当您对文档进行索引时,它首先在主分片上进行索引,然后在主分片的所有副本上进行索引。
默认情况下,索引有5个主分片。您可以指定更少或更多的主分片来缩放索引可以处理的文档数量。
创建索引后,不能更改索引中主分片的数量。
replica shard(副本分片)
每个主分片可以有零个或多个副本。副本是主分片的副本,有两个目的:
增加故障转移:如果主分片发生故障,副本分片可以升级为主分片
提高性能:get和搜索请求可以由主分片或副本分片处理。
默认情况下,每个主分片都有一个副本,但副本的数量可以在现有索引上动态更改。副本分片永远不会在与其主分片相同的节点上启动。
node
节点是属于集群的弹性搜索的运行实例。出于测试目的,可以在一台服务器上启动多个节点,但通常每个服务器应该有一个节点。
启动时,节点将使用单播来发现具有相同群集名称的现有群集,并尝试加入该群集。
node角色
1、master node
资源要求:中高CPU;中高内存;中低磁盘
一般在生产环境中配置3台
一个集群只有1台活跃的主节点,负责分片管理,索引创建,集群管理等操作
整个集群的管理者,索引管理,分片管理,以及整个集群的状态的管理,master节点是从master候选节点中选出的,成为master候选节点的方式:
2、data node
数据节点保存数据并执行数据相关操作,如CRUD、搜索和聚合。
资源要求:CPU、内存、磁盘要求都高
3、Coordinating node 协调节点
向集群添加太多的仅协调节点会增加整个集群的负担,因为所选的主节点必须等待来自每个节点的集群状态更新确认!仅协调节点的好处不应夸大 — 数据节点可以愉快地服务于相同的目的。
协调节点,所有节点都可以接受来自客户端的请求进行转发,因为每个节点都知道集群的所有索引分片的分布情况,但是别的节点,都还肩负着别的工作,如果请求压力过大,可能会拖垮整个集群的响应速度,所以就专门有了这个协调节点,他什么都不用做,只处理请求和请求结果,所以成为coordinating node的方式:
cluster(集群)
群集由共享相同群集名称的一个或多个节点组成。每个集群都有一个单独的主节点,该节点由集群自动选择,如果当前主节点发生故障,则可以替换该节点。
routing(路由)
当您为文档编制索引时,它存储在单个主分片上。通过散列路由值来选择该分片。默认情况下,路由值来自文档的ID,如果文档具有指定的父文档,则来自父文档的ID(以确保子文档和父文档存储在同一个分片上)。
可以通过在索引时指定路由值或映射中的路由字段来覆盖此值。
shard = hash(routing) % number_of_primary_shards
Refresh
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 近 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
性能开销大
将文档先保存在Index buffer中,以refresh_interval为间隔时间,定期清空buffer,生成 segment,借助文件系统缓存的特性,先将segment放在文件系统缓存中,并开放查询,以提升搜索的实时性
segment
段是索引中存储索引数据的内部存储元素,并且是不可变的。较小的段会定期合并到较大的段中,以保持索引大小不变,并消除删除。
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
index.translog.flush_threshold_size 默认 512 MB
Translog
Segment没有写入磁盘,即便发生了当机,重启后,数据也能恢复,从ES6.0开始默认配置是每次请求都会落盘
对Lucene的更改仅在Lucene提交期间持久化到磁盘,这是一个相对繁重的操作,因此无法在每次索引或删除操作之后执行。如果进程退出或硬件故障,在一次提交之后和另一次提交之前发生的更改将丢失。
为了防止这种数据丢失,每个碎片都有一个与其相关的事务日志或预写日志。任何索引或删除操作都会在内部Lucene索引处理后写入translog。
在发生崩溃的情况下,当碎片恢复时,可以从事务日志中回放最近的事务。
Elasticsearch刷新是执行Lucene提交并启动新translog的过程。它是在后台自动完成的,以确保事务日志不会增长太大,这将使恢复过程中重播其操作需要相当长的时间。它也通过API公开,尽管很少需要手动执行。
Analysis(分词器)
分词器是将全文转换为术语的过程。根据使用的分析器,这些短语:FOO BAR、FOO BAR、FOO、BAR可能都会产生FOO和BAR。这些术语实际上存储在索引中。
ik、HanLP
倒排索引
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
为了创建倒排索引,我们通过分词器将每个文档的内容域拆分成单独的词(我们称它为词条或 Term),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。
寄件地址1:叶山风社·海鲜烧烤·小龙虾
寄件地址2:李氏串烧•烧烤•小龙虾(石桥铺店)
寄件地址3:深夜的喵烧烤·小龙虾(越城店)
……
| Term | Doc1 | Doc2 | Doc3 |
| 叶山风社 | V | ||
| 海鲜 | V | ||
| 李氏串烧 | V | ||
| 烧烤 | V | V | V |
| 小龙虾 | V | V | V |
| 深夜的喵 | V | ||
| 石桥铺店 | V | ||
| 越城店 | V |
2、部署架构
初级
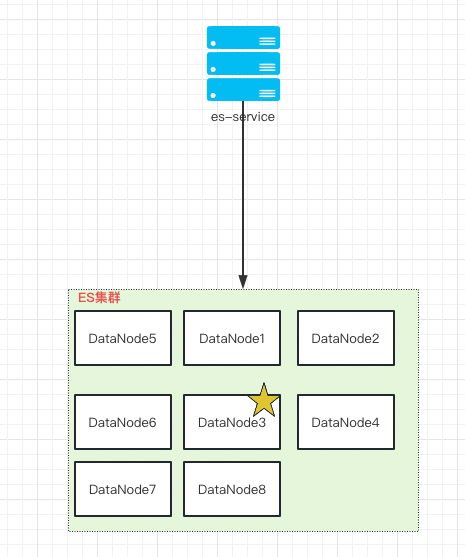
一般规模
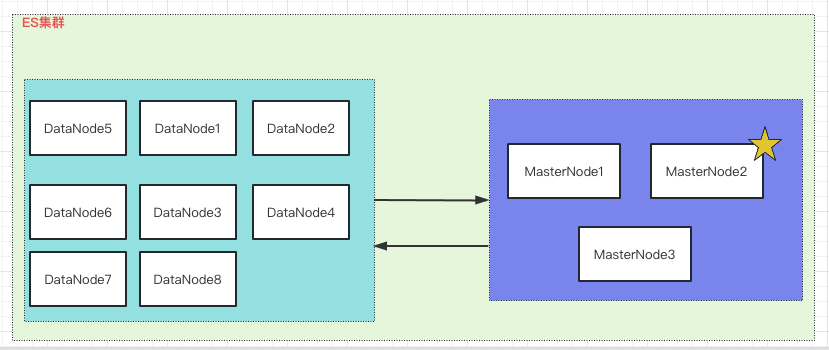
超大型规模集群场景:
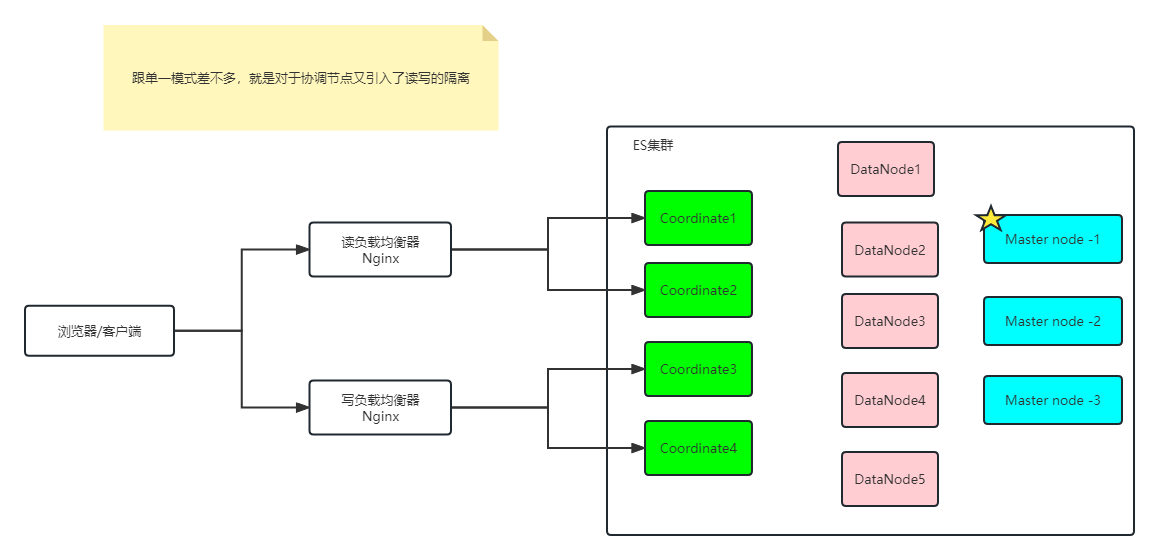
读写分离架构
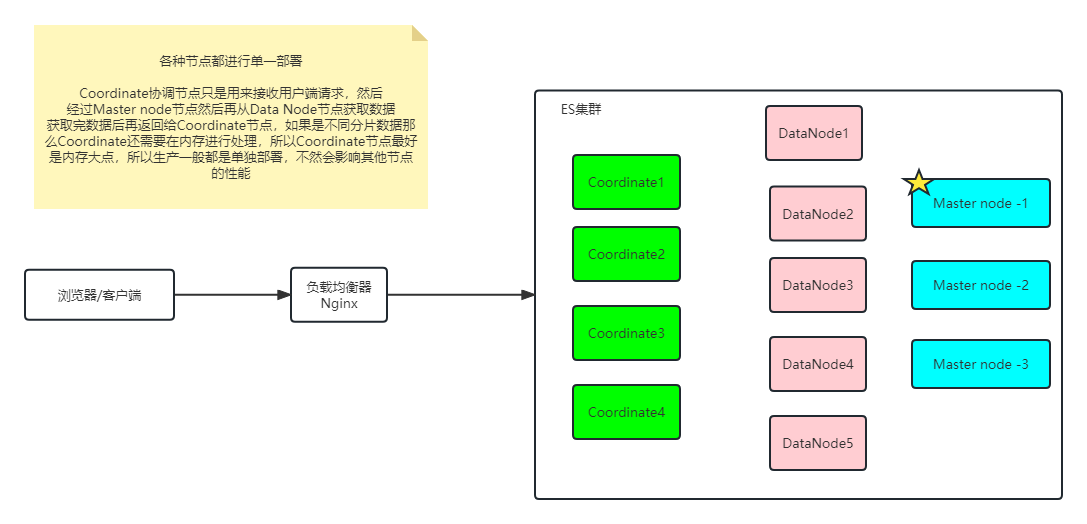
在单一职责上对协同节点进行隔离,这是针对协调节点的
业务灵活:
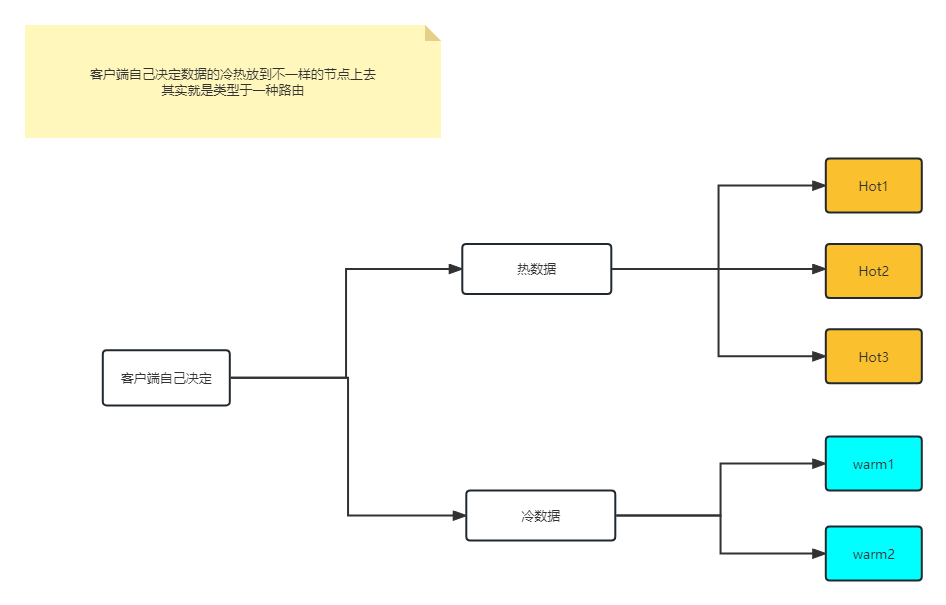
3、应用场景
ELK

订单搜索
商品搜索
酒店机票
资讯
















 2672
2672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











