






需求:最近公司产品提出一个需求,要爬取某网站的数据列表中,进入某条数据的pdf文件中,提取出对应的关键字出来。
解决:
-
将pdf文件中每页图片保存下来。
-
pdf文件中的内容是个图片,不能直接转换成文字。
-
根据产品需求,指定提取相关内容,并保存。
总结:通过调研,可以使用python的pytesseract库来完成相关pdf的文字提取。pdf图片保存和文字内容匹配暂不介绍,主要介绍下pytesseract的使用。
01 python-tesseract介绍
Python-tesseract 是 Python 的光学字符识别 (OCR) 工具。也就是说,它将识别并“读取”嵌入在图像中的文本。
Python-tesseract 是Google 的 Tesseract-OCR Engine的包装器。它也可用作 tesseract 的独立调用脚本,因为它可以读取 Pillow 和 Leptonica 成像库支持的所有图像类型,包括 jpeg、png、gif、bmp、tiff 等。此外,如果用作脚本,Python-tesseract 将打印识别的文本而不是将其写入文件。
02 结果展示

原pdf图片
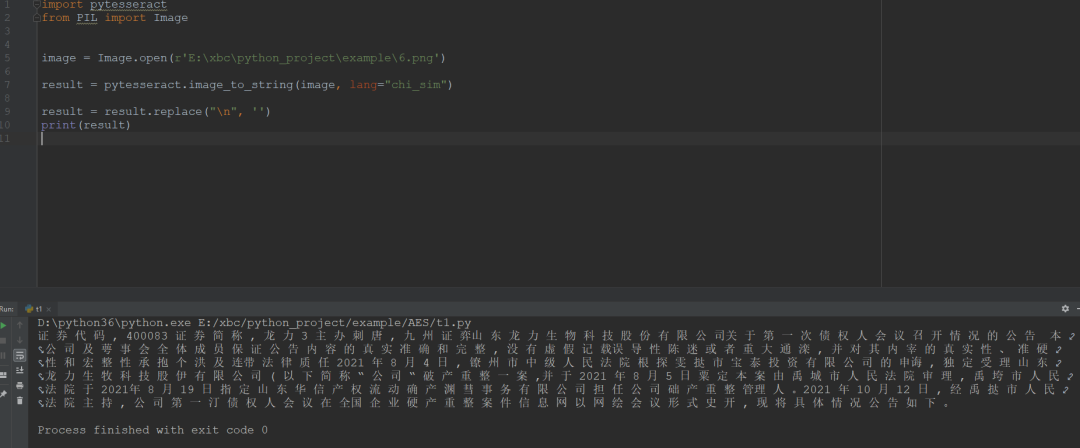
识别后
对于识别的结果,是能够满足后续的关键字提取的需求的。
03 tesseract安装
下载地址:https://digi.bib.uni-mannheim.de/tesseract/
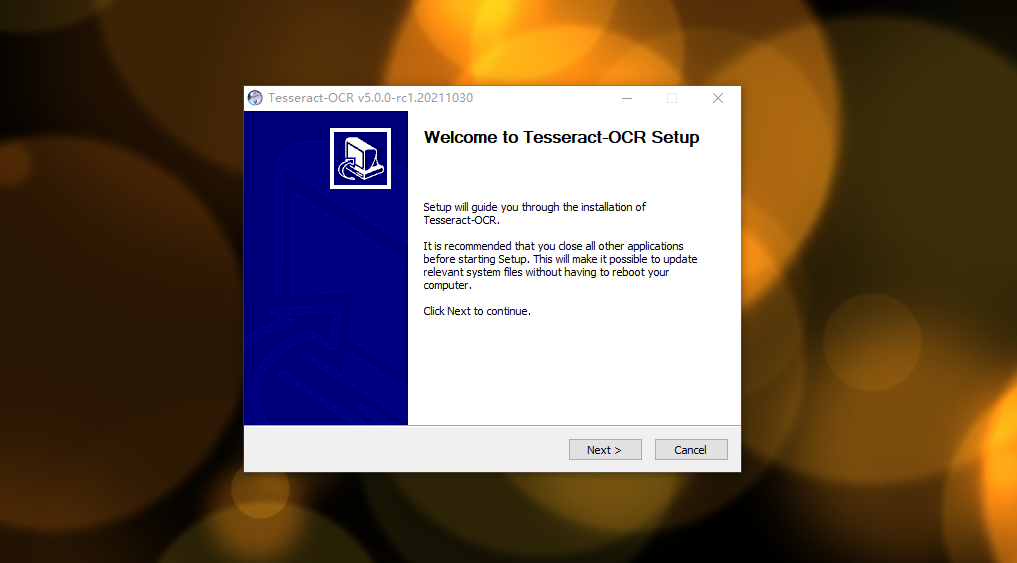
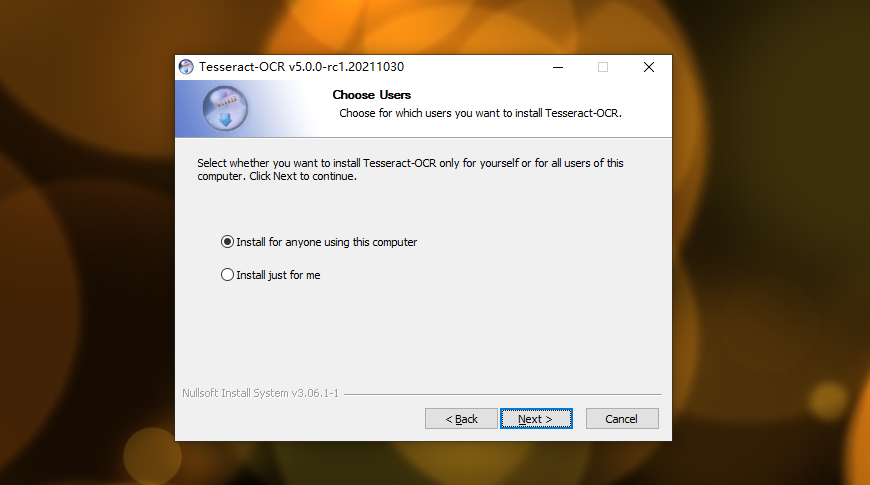
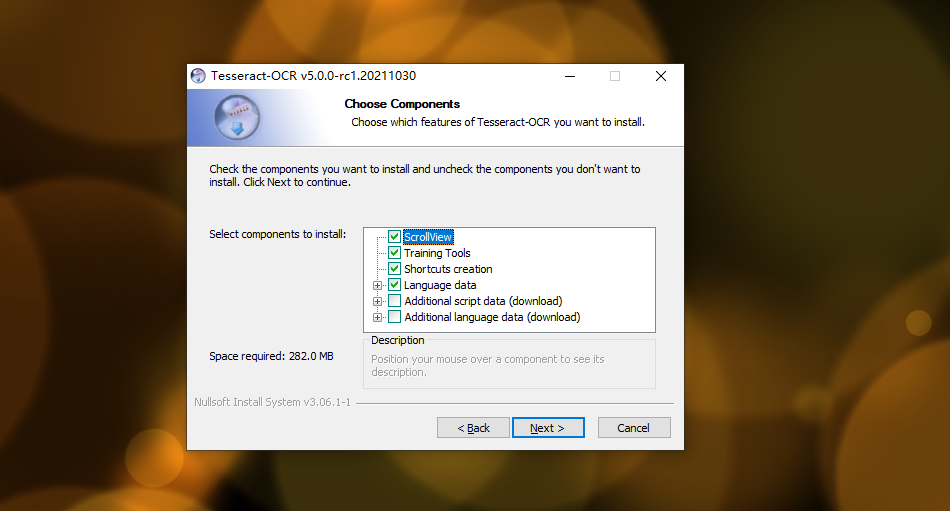
安装过程:
安装完成之后,查看是否安装成功:
查看版本
tesseract --version
pytesseract安装
pip install pytesseract
修改pytesseract.py文件
tesseract_cmd = 'E:/tools/tesseract/tesseract.exe'

04 示例代码
图片识别实例
import pytesseract
from PIL import Image
image = Image.open(r'E:\xbc\python_project\example\6.png')
result = pytesseract.image_to_string(image, lang="chi_sim")
result = result.replace("\n", '')
print(result)
在遇到图像中的文字需要识别时,使用ptytesseract还是比较方便的,尽管有很多平台提供这些功能,但是免费的工具它不香吗?
感兴趣的可以关注作者微信公众号:程序员9527。


















 2196
2196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









