









前言
防砸声明:此文仅仅能保证入门,不保证商业生产。
最终实现效果:
爬虫简介:
引用钱洋博士课程的部分内容(有删改):
网络爬虫技术,有效的获取网络数据资源的重要方式。简单的理解,比如您对百度贴吧的一个帖子内容特别感兴趣,而帖子的回复却有1000多页,这时采用逐条复制的方法便不可行。而采用网络爬虫便可以很轻松地采集到该帖子下的所有内容。
网络爬虫的作用,我总结为以下几点:
- 舆情分析:企业或政府利用爬取的数据,采用数据挖掘的相关方法,发掘用户讨论的内容、实行事件监测、舆情引导等。
- 企业的用户分析:企业利用网络爬虫,采集用户对其企业或商品的看法、观点以及态度,进而分析用户的需求、自身产品的优劣势、顾客抱怨等。
- 科研工作者的必备技术:现有很多研究都以网络大数据为基础,而采集网络大数据的必备技术便是网络爬虫。利用网络爬虫技术采集的数据可用于研究产品个性化推荐、文本挖掘、用户行为模式挖掘等。
按照陈树义前辈在《聊聊整体性学习方法》一文中提到的思想,本文思路如下:
- 获取:目前都有哪些爬虫技术?
- 理解:这些爬虫技术的特色是什么?
- 扩展:快速上手一下cdp4j爬虫技术。
- 纠错:解析网页过程中踩过的坑与填坑之路。
- 应用:实战爬取网易新闻评论内容。
正文
一、目前都有哪些爬虫技术,及其特色都是什么?
先说一句我不是专业搞爬虫的,从2019-07-06到2019-07-11累计学习6天。这篇文章是对我这6天学习的总结。以我浅显的了解,在此我列出我曾经尝试过后来又放弃了的框架,最后压轴(zhoù)再写我正在使用的框架。目前有以下流行的爬虫框架技术:
-
Apache Nutch(高大上)
Nutch这个框架运行需要Hadoop,Hadoop需要开集群,对于想要快速入门爬虫的我是望而却步了…
一些资源地址列在这里,说不定以后会学习呢。
-
Crawler4j(感觉很强)
从它的包名上可以看出这个框架来自加州大学欧文分校。我下载下来Demo运行了一下,感觉很强!但他的官方文档介绍很简洁,Demo只是运行了一下没看懂怎么用。之所以感觉很强,是看见了好的厉害的API,当然也有一些加州大学的名气影响。
-
WebMagic(国产)
根据网上介绍,这个框架产自曾就职于大众点评的黄亿华大佬,但是,无论GitHub还是码云上这个仓库已经两年没有更新了,其中有一个致命的“Bug”,不能爬https的链接。作者在GitHub的issue中明确说明会在下一个版本(0.7.4)中修复此“Bug”,但是,两年过去了,依然没有发布下一个版本,截止2019年7月11号,GitHub上依然是0.7.3版本,可能作者遇到了某种不可抗拒力量,导致无法维护下去。下图来自GitHub issues
-
Spiderman2(国产)
这个听名字就挺霸气的,和蜘蛛侠电影齐名。我也是下载下来Demo运行了一下,但是运行啥啥报错…
而且官方库也没有提供文档。
但是,之所以列出来这个库,是因为作者在码云的issue中现场教学感动了我。

-
WebController(国产·合肥工业大学)
当我根据这个库的包名搜索出合肥工业大学时,心中只有两个字:牛X!
维护这个库的兄弟还煞费苦心的把README.md全英文书写。不过同样是因为文档过于简陋。Demo运行了几个,不知道运行出来个啥。
之所以贴出来这个,确实是因为他在GitHub上2000+star震惊到我了,同样身为大学生的我,求学三年,毫无产出,甚是惭愧。定当以前辈励志,再加努力。
-
HtmlUnit(经典)
这个框架堪称经典,也是我们暑期实训老师讲解的框架。有近乎完整的文档介绍。
但是,HtmlUnit使用起来相当麻烦,或许用多了就不觉得麻烦了。还有一点忍受不了,就是太慢了,慢到令人发指的地步!再尝试了几个Demo之后,我就放弃了。
-
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期实训老师讲解的框架。有近乎完整的文档介绍。
但是Jsoup只能get到静态网页内容。但是,当今世界,静态网页已经寥寥可数了,大都是与后台交互的动态网页,很多数据都是经过后台获取,渲染之后才能呈现在网页上。据我6天浅显的学习,发现单纯的Jsoup无法爬取动态网页内容。
大家可以试一下,打开一篇网易新闻,然后右键查看源代码,你会发现,你所看到的页面和源代码内容并不是一一对应的。不过,这个框架有个有个优点,具有很强大的解析网页的功能。
-
selenium(Google多名大佬参与开发)
感觉很厉害,实际真的很厉害,看官网以及其他人的介绍,说是真正模拟浏览器。GitHub1.4w+star,你没看错,上万了。但是我硬是没配好环境。入门Demo就是没法运行成功,所以就放弃了。
-
cdp4j(今天的主角)
使用前提:
安装Chrome浏览器,即可。
简单介绍:
HtmlUnit的优点在于,可以方便的爬取静态网友;缺点在于,只能爬取静态网页。
selenium的优点在于,可以爬取渲染后的网页;缺点在于,需要配环境变量等等。
将二者整合,取长补短,就有了cdp4j。
之所以选用它,是因为真的方便好用,而且官方文档详细,Demo程序基本都能跑起来,类名起的见名知意。想当年学软件工程的时候,一直在纳闷,为什么要写文档啊,我程序能实现功能不就得了?现如今,看着如此详实的文档,留下了激动而又悔恨的泪水…
cdp4j有很多功能:
a. 获得渲染后的网页源码
b. 模拟浏览器点击事件
c. 下载网页上可以下载的文件
d. 对网页进行截屏或转PDF打印
e. 拿到网页响应内容
f. 等等
更多详细信息可以自行去如下三个地址中探索发现:
小结
我在正文列出了9个爬虫框架。有强如Apache、Google大佬开发维护,也有诸如我国合肥工业大学学生的作品。其实各有各自的特色,弱水三千,我想全喝,但没有那个能力。所以目前只饮一瓢,就是cdp4j了。
二、快速上手一下cdp4j爬虫技术
首先,再强调一点:使用前提是安装了Chrome浏览器
当然,不能凭空使用,还需要Maven依赖
<dependency>
<groupId>io.webfolder</groupId>
<artifactId>cdp4j</artifactId>
<version>3.0.12</version>
</dependency>
<!-- 2.2.1 版本的cdp4j不用导入winp;3.0+ 版本的cdp4j需要导入此包 -->
<!-- https://mvnrepository.com/artifact/org.jvnet.winp/winp -->
<dependency>
<groupId>org.jvnet.winp</groupId>
<artifactId>winp</artifactId>
<version>1.28</version>
</dependency>
先看一下官网给出的HelloWorld
看出来我贴的是一张图片了吗?所以先别着急敲,因为这个程序还需要稍作修改,如下:
import io.webfolder.cdp.Launcher;
import io.webfolder.cdp.session.Session;
import io.webfolder.cdp.session.SessionFactory;
import static java.util.Arrays.asList;
public class HelloWorld {
public static void main(String[] args) {
Launcher launcher = new Launcher();
try (SessionFactory factory = launcher.launch(asList("--disable-gpu",
"--headless"))) {
String context = factory.createBrowserContext();
try (Session session = factory.create(context)) {
// 设置要爬的网站链接,必须要有http://或https://
session.navigate("https://www.baidu.com");
// 默认timeout是10*1000 ms,也可以像下面这样手动设置
session.waitDocumentReady(15 * 1000);
// 通过session得到渲染后的html内容
String html = session.getContent();
System.out.println(html);
}// session创建结束
// 处理浏览器上下文,源码:contexts.remove(browserContextId)
// 意思应该是将后台浏览器进程关闭
// 我曾经尝试将此举注释,只保留下面的launcher.getProcessManager().kill();
// 依然可以关闭后台进程,但是官方给的代码有这句,那就带着吧,或许有其他作用。
factory.disposeBrowserContext(context);
}// factory创建结束
// 真正的关闭后台进程
launcher.getProcessManager().kill();
}// main方法结束
}
上面的代码你可以手动敲一遍,当然一般都是复制粘贴的。
与截图不同的是:
- 这里的factory和session是在两个不同的try-with-resource语句中创建的,
- 创建factory时多了一句 asList("–disable-gpu","–headless") 这个作用就是不启用GPU加速,不弹出浏览器
- 在最后对BrowserContex以及launcher进行了关闭操作以达到回收内存的目的。
大家如果不理解这段代码的作用,可以自行运行一下两种代码,然后打开任务管理器,查看IDEA进行下的子进程。
运行结束后再看一下任务管理器,如果执行了关闭操作,那么IDEA下的子进程会被关闭,否则,有两种情况:
-
创建factory时候,没有加上 asList("–disable-gpu","–headless") 这样会弹出一个Chrome浏览器,需要手动进行关闭
-
创建factory时候,加上了 asList("–disable-gpu","–headless") 这样IDEA进程的子进程,也就是上图的Google Chrome会驻留在后台,占据内存资源。
小结
说白了,cdp4j就是一个模拟浏览器,区别于HtmlUnit,这里是真的用到了浏览器,如果代码写的不对,还会弹出浏览器,吓你一跳 : )
目前只是简简单单的获取到了渲染后的html,真正的爬虫可不仅仅就这。
三、解析网页过程中踩过的坑与填坑之路
-
啥是xPath?
详细介绍可以参考W3cSchool XPath 简介 或者 Runoob XPath 简介
我在这里简单总结一下:xPath是用来遍历DOM树的。
你要是敢问我啥是DOM树,我可就举起来拖鞋抽你了 : ) 哈哈,开玩笑,同样也是看一下W3CSchool HTML DOM 简介 或者 Runoob HTML DOM 简介
-
如何快速获取一个节点的xPath?
我们暑期实训老师是按下F12,然后找到对应节点,再从上到下一个一个的数出来的xPath。
第一次见这样操作的时候,由于新鲜感过于强烈,所以也就没有感到有多麻烦。不过,数的次数多了,总觉得这样不行。应该有更快更好的方法获取xPath。
还记得SpiderMan2吗?自风老师在码云的issue里面亲身教学:Chrome获取XPath的方法
整了半天,原来人家Chrome浏览器早就替我们实现好了,就知道我们要用到xPath干坏事。
-
xPath具体怎么用?
自风老师教的copy xPath直接用的话,只能是一个节点。
实际上,有时候我们需要一次性拿到很多节点,比如说xPath路径都是div/p,这时候我们可以写成“//div/p”,又有时候,我们需要拿到指定class的div下的p,那么语法就是“//div[@class=‘classname’]/p”
更详细的用法可以参考 Runoob XPath 语法
-
怎样快速解析一个html,拿到想要的内容?
虽说cdp4j自带xPath解析功能,但要说解析html,还要属Jsoup最专业:Jsoup中文教程
Jsoup支持xPath和CSS选择器,学前端的同学看到CSS选择器应该会很激动吧,我头一次看到内心是:竟然还有这种操作!
小结
xPath、Jsoup这些新名词,很多人(比如我)大学上了3年,还是头一次听说,所以需要一些时间去接近,熟悉最终才能掌握。
四、实战爬取网易新闻评论内容
【项目源码】 进去找 News163CommentCrawlerDemo 或者 News163CommentCrawlerDemo.zip
实现思路就是模拟真实浏览器拿到评论并展示的过程,注意是浏览器拿到评论的过程而不是人类拿到评论的过程,区别就在于,人类是通过html页面渲染,而浏览器是通过 解析json 动态加载的:
- 打开国内新闻链接:https://news.163.com/domestic/
- 从上面链接获取获取渲染后的html内容,拿到新闻列表的链接
- 根据新闻列表中的每一篇文章的链接获取渲染后的html内容,拿到新闻详细内容
- 根据新闻详细内容拿到评论地址
- 打开评论地址并拿到响应内容(官方Demo地址),正则匹配后拿到评论JSON API地址链接
- 请求评论JSON API链接,获取渲染后的html
- 解析渲染后的评论JSON HTML并拿到评论相关的内容
具体步骤:
- 打开IDEA new 一个新坑

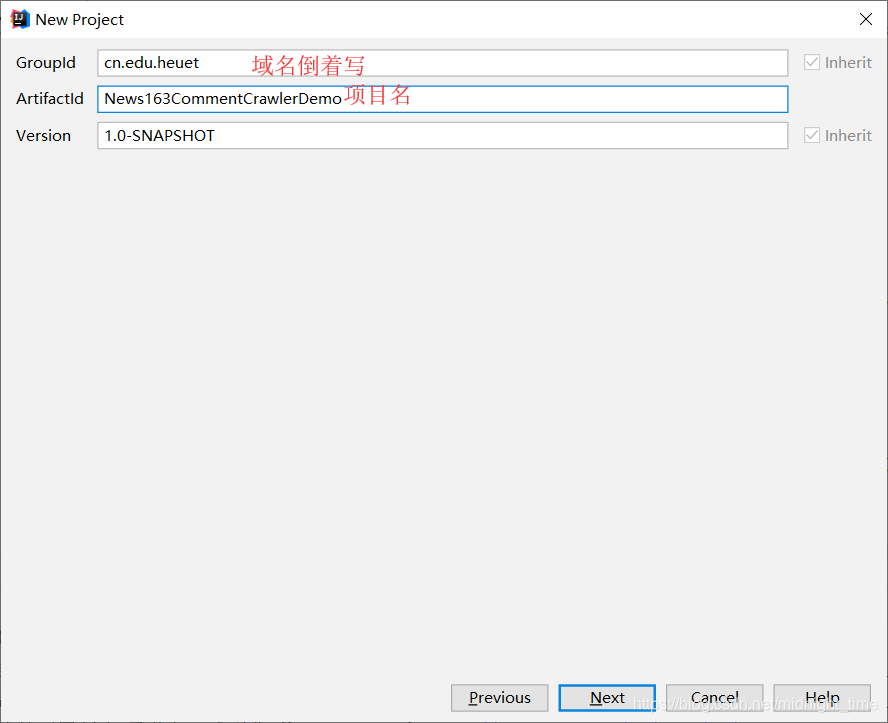
- 完整pom.xml内容
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.edu.heuet</groupId>
<artifactId>News163CommentCrawlerDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 指定 JDK1.8进行编译 -->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<properties>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.source>1.8</maven.compiler.source>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
<!--<dependency>-->
<!--<groupId>io.webfolder</groupId>-->
<!--<artifactId>cdp4j</artifactId>-->
<!--<version>2.2.1</version>-->
<!--</dependency>-->
<!-- https://mvnrepository.com/artifact/com.google.code.gson/gson -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>io.webfolder</groupId>
<artifactId>cdp4j</artifactId>
<version>3.0.12</version>
</dependency>
<!-- 2.2.1 版本的cdp4j不用导入此包;3.0+ 版本的cdp4j需要导入此包 -->
<!-- https://mvnrepository.com/artifact/org.jvnet.winp/winp -->
<dependency>
<groupId>org.jvnet.winp</groupId>
<artifactId>winp</artifactId>
<version>1.28</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.json/json -->
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20170516</version>
</dependency>
</dependencies>
</project>
-
项目目录结构
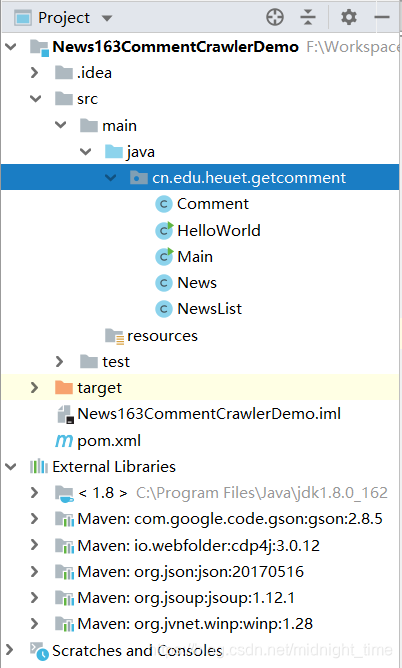
-
Main.java内容概览
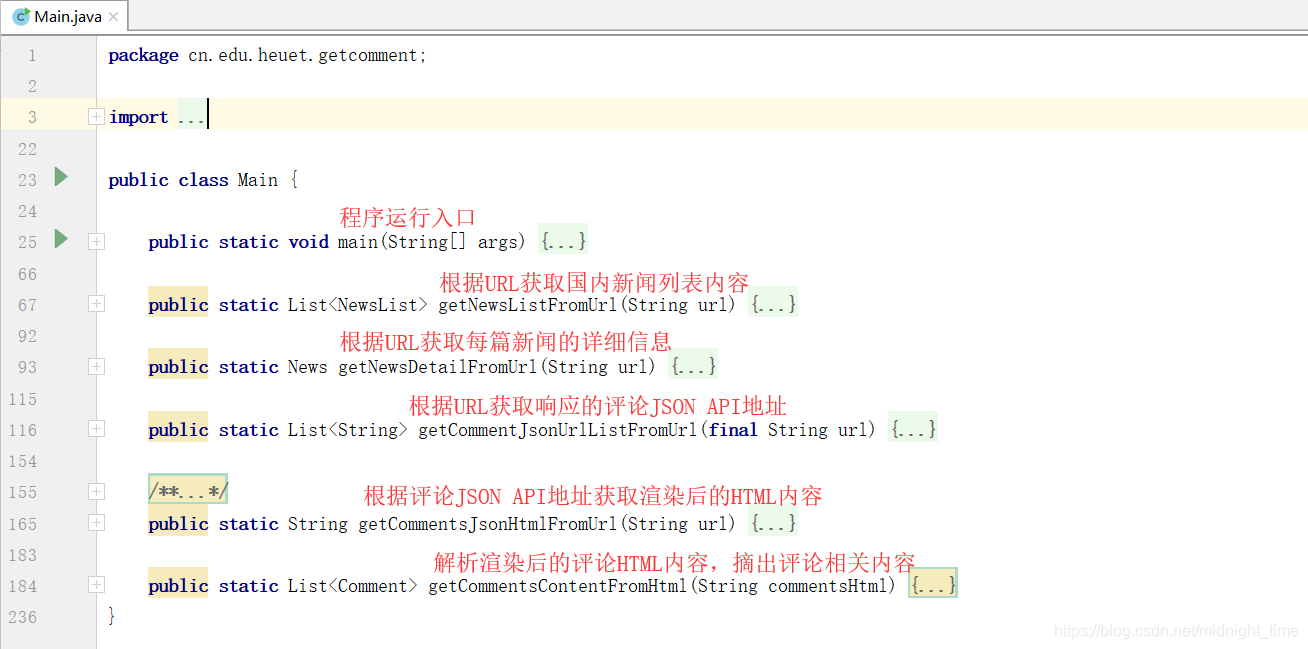
- 最终实现效果
【项目源码】 进去找 News163CommentCrawlerDemo 或者 News163CommentCrawlerDemo.zip (约 90kb)
注意:Maven需要指定Java1.8 否则try-with-resource中不能使用外部数据。
总结
虽说实现了爬取网易新闻评论的功能,但还有一些技术要点没有解决:
- 只能爬取第一页的内容,尚未实现分页爬取
- 爬取的内容有重复,尚未实现内存去重
- 爬取的内容没有持久化保存,尚未实现内容存入MongoDB(下篇会介绍如何入库)
时间匆匆,一晃6天就过去了。














 633
633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









