







熵的概念
引例:
如果随机变量x的可能取值为 X=x1,x2,...,xk 。若用n位的y: y1,⋯,yn(每个y有c种取值) 表示,则n的取值期望。∑i=1kp(x=xi)log1p(x=xi)logc
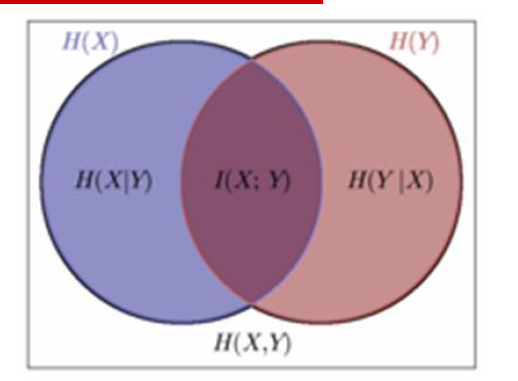
熵: H(X)=−∑x∈Xp(x)lnp(x) = >单位nat(奈特)
- 熵是不确定性的度量
- 随机变量退化为定值,熵是0
- 均匀分布熵最大
- 0≤H(x)≤log|x|联合熵: H(X,Y)
- 条件熵: H(X|Y)=H(X,Y)−H(Y)
相对熵 (KL散度): D(p||q)=∑xp(x)logp(x)q(x)
- 度量两个随机变量的距离
- D(p||q)≠D(q||p)互信息: I(X,Y)=D(P(X,Y)||P(X)P(Y))=∑x,yp(x,y)logp(x,y)p(x)p(y)
Venn
最大熵原理
- 承认已知事物(知识)
对未知事物不做任何假设,没有偏见
最大熵: 计算X和Y的分布,使得H(Y|X)最大
一般形式
maxp∈PH(Y|X)=−∑(x,y)p(x,y)logp(y|x)
p是X上满足条件的概率分布
最大熵模型
- 特征: (x,y)->(特征的上下文,特征的确定信息)->(“花”,”flower”),(“花”,”spend”)
- 样本:已知
< p¯(x)=x出现的概率 >;
< p¯(x,y)=x和y一起出现的概率 >;
< p¯(f)=特征f在样本中的期望值 > - 特征函数: 对于 (x0,y0) ->定义特征函数: f(x,y)={1x=x0且y=y00otherwise
- 对于特征 (x0,y0) ,其样本中的期望值是 p¯(f)=∑(xi,yi)p¯(x,y)f(x,y)
*条件
特征函数和经验分布 p¯(X,Y)的期望值:p¯(f)=∑x,yp¯(x,y)f(x,y)
特征函数和模型p(Y|X)与经验分布 p¯(X) 的期望值
p(f)=∑(xi,yi)p(xi,yi)f(xi,yi)
=∑(xi,yi)p(yi|xi)p(xi)f(xi,yi)
=∑(xi,yi)p¯(yi|xi)p(xi)f(xi,yi)若模型能获得训练数据中的信息,则两个期望相等<理论模型的分布应该与样本的分布一致>
p(f)=p¯(f)
- 转换为
-目标函数:
p∗=argmaxp∈PH(Y|X)=−∑(x,y)p(x,y)logp(x,y)
=−∑(x,y)p(y|x)p¯(x)logp(y|x)
约束:
∑y∈Yp(y|x)=1
E(fi)=E¯(fi)
解优化
过程省略
结果:
p∗(y|x)=1exp(1−λ0)exp(∑iλifi(x,y))
- 最大熵和logistc的多分类情况softmax具有相同的目标函数
- 均以似然函数为目标函数的最优化问题
- 最大熵的解和最大似然的解一致,具有相同的目标函数















 206
206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









