







hive架构
- 独立于集群之外,可以视为Hadooop的客户端
- Metastore是Hive的元数据集中存放池
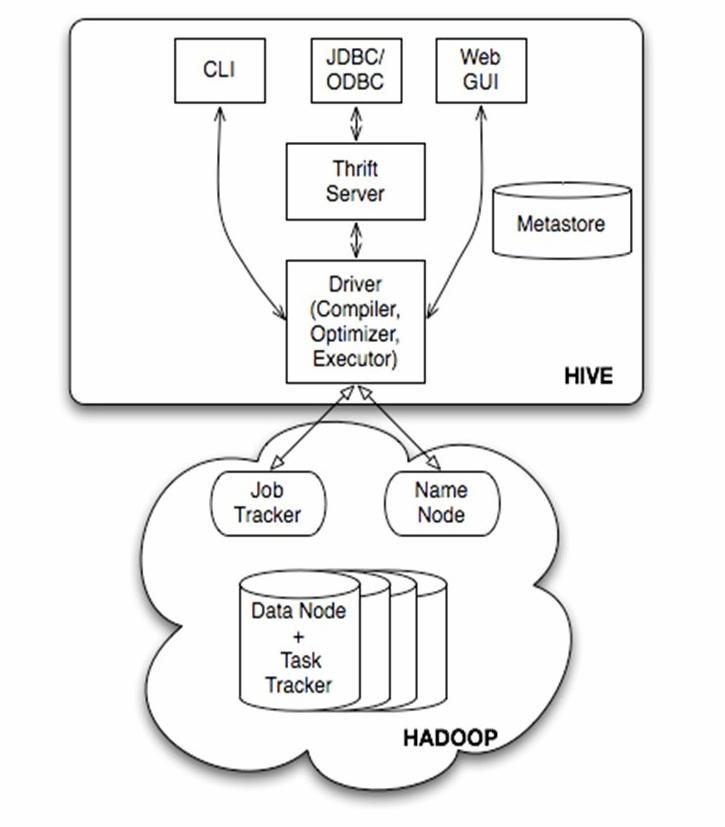
用户接口:CLI
Thrift服务器
以服务器模式运行,供客户连接
thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引擎,以构建在 C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, and OCaml 这些编程语言间无缝结合的、高效的服务。元数据存储 (METASTORE)
存储在关系数据库:MySQL中
存储各种表与分区的信息Hive数据存储在HDFS上
hive的数据存储
- 表、分区、桶、外部
HIVE 语法
基本类型
| 数据类型 | 长度 | 示例 |
|---|---|---|
| TINYINT | 1字节 | 11 |
| SMALLINT | 2字节 | 11 |
| INT | 4字节 | 11 |
| BIGINT | 8字节 | 11 |
| FLOAT | 4字节 | 11.0 |
| DOUBLE | 8字节 | 11.0 |
| BOOLEAN | true/false | TRUE |
| STRING | 字符序列 | ‘hadoop’ |
复杂结构
- struct
- map
- array
存储格式
stored as
* TEXTFILE
* SEQUENCEFILE
* RCFILE
* 自定义格式
数据格式
\n......
^A......\001
^B......\002
^C......\003
表
- 创建表: create DATABASE test
- show tables
- DESC tables
分区
PARTITIONED BY
加载数据
load data inpath ‘……’ inti tables test;
插入数据
insert overwrite table test SELECT * FROM source
insert overwrite table test PARTITION (part=’a’ ) SELECT * FROM source
导出数据
INSERT OVERWRITE DIRECTORY ………. hdfs
INSERT OVERWRITE LOCAL DIRECTORY……… 本地
select 、where
GROUP BY
先按照一个列或者多个列分组在,再聚合函数
SLECT COUNT(*) FROM STTUDENT GROUP BY age;
- 查询字段不在group by 则需要使用聚合函数
SELECT name, AVG(age) FROM student GROUP BY classID;
join
ORDER BY /SORT BY
- order by全局排序,必须由一个reduce完成
- sort by 局部排序
distirbuted by
- 类似于partitoned
UDF
add jar /home/hadoop/udf.jar
create temproaary function mycount as ‘….’















 4537
4537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









