







RDD
- 可被切分
- 由一个函数计算每一个分片
- 对其他的RDD依赖
- 可选:key-value的rdd是根据hash来分区的,类似于partitioner接口
RDD计算模式
- Iterative Algorithms
- Relational Queries
- MapRdecue
- Streaming
RDD的四个核心方法
- getPartitions: 返回一系列partitions集合
- getDependencies:表达RDD之间的依赖关系
- compute:针对每个partition计算
- getPreferredLocation:寻找partions的位置
- 可选的分区策略,默认分区是HashPartitioner
spark计算代码
- 生成RDD
val rdd=sc.parallelize(list(1,2,3,4,5))- filter
val filterRDD=mappedRDD.filter(_ > 4)
filterRDD.collect- cache
*count
val vordcount=rdd.flatMap(_.split(' ')).map(_,1).reduceByKey(_+_)
wordcount.saveAsTextFile('/data/test')- sort
val wc=rdd.flatmap(_.split('')).map(_,1).reduceByKey(_+_).map(x=>(x._2,x._1)).sortByKey().map(x=>(x._2,x._1))- union
- groupByKey
RDD计算模型
http://blog.csdn.net/dc_726/article/details/41381791
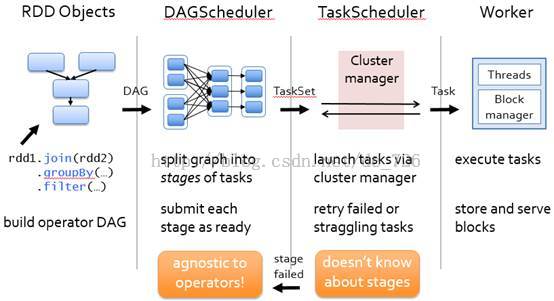
- 创建RDD对象,
- DAG调度器创建执行计划,
Task调度器分配任务并调度Worker开始运行。
Driver
- RDD依赖分析,生成RDD
- 生成DAG,将job划分为不同的stage(宽窄依赖)
- stage生成task,发送到Executor















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









