







基本模型
*随机游走模型
- 针对浏览网页的用户行为建立的抽象模型
- 直接跳转:打开浏览器,输入网址,然后根据链接跳转
转移概率矩阵
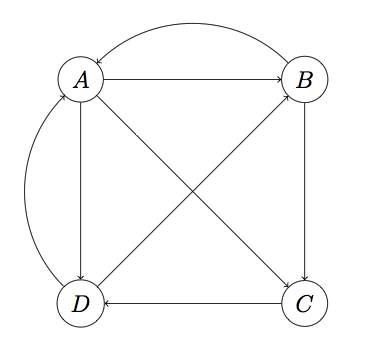
则可以组织这样一个N维矩阵:其中i行j列的值表示用户从页面j转到页面i的概率
M=⎡⎣⎢⎢⎢⎢01/31/31/31/201/2000011/21/200[AA,BA,CA,DA][AB,BB,CB,DB][AC,BC,CC,DC][AD,BD,CD,DD]⎤⎦⎥⎥⎥⎥远程跳转:以1/4的概括进入任意页面(rank值)
v=⎡⎣⎢⎢⎢⎢1/41/41/41/4⎤⎦⎥⎥⎥⎥M的第一行是各页面到A页面的概率
- v的列是ABCD当前的rank值
- Mv是ABCD的新的rank
Mv=⎡⎣⎢⎢⎢⎢1/45/245/241/3⎤⎦⎥⎥⎥⎥
然后用M再乘以这个新的rank向量,又会产生一个更新的rank向量。迭代这个过程,可以证明v最终会收敛,即v约等于Mv,此时计算停止。最终的v就是各个页面的pagerank值。例如上面的向量经过几步迭代后,大约收敛在(1/4, 1/4, 1/5, 1/4),这就是A、B、C、D最后的pagerank。
* pagerank
http://blog.jobbole.com/71431/
http://blog.codinglabs.org/articles/intro-to-pagerank.html
http://ibillxia.github.io/blog/2012/07/08/Google-PageRank-Algorithm/
- 数量假说:在web图模型中,如果一个页面节点接收到其他网页指向的入链数量越多,那么这个页面越重要
- 质量假说:指向A的入链质量不同,质量高的页面会通过链接转向其他页面传递更高的权重。所以越是质量高的页面指向A,A越重要
pagerank的计算
- Miv
- 本质是马尔科夫过程,如果收敛需要满足:图是强连通的,即从任意网页可以到达其他任意网页;
pagerank的问题
- 避免终止点
互联网上的网页不满足强连通的特性,因为有一些网页不指向任何网页,如果按照上面的计算,上网者到达这样的网页后便走投无路、四顾茫然,导致前面累计得到的转移概率被清零,这样下去,最终的得到的概率分布向量所有元素几乎都为0。假设我们把上面图中C到A的链接丢掉,C变成了一个终止点 - 避免陷阱问题
即有些网页不存在指向其他网页的链接,但存在指向自己的链接。
抽税的做法
原来的公式:
v′=M∗v较小概率的随机跳转到一个随机的网页
一是以概率(1- β )随机访问任何一个页面( 遇到上述0的情况,人为的跳出),二是以概率( β )访问 页面i中的某个链接。
v′=βMv+(1−β)e/n
β
取值(0.8~0.9)一般常取值0.85
e为N维单位向量,加入e的原因是这个公式的前半部分是向量,e是维度是n,数值是1的列向量
e=⎡⎣⎢⎢⎢⎢1/n1/n1/n1/n⎤⎦⎥⎥⎥⎥
n是web图所有节点的数目
这样,整个计算就变得平滑,因为每次迭代的结果除了依赖转移矩阵外,还依赖一个小概率的心灵转移。















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









