







初探hadoop,去了解hadoop的简史对于我们学习hadoop有很大的帮助,下面我们来看看什么是hadoop?
一. What Is Apache Hadoop?
(1)The Apache™ Hadoop® project developsopen-source software for reliable, scalable, distributed computing.
(2)hadoop要去解决的问题:①海量数据的存储(HDFS)②海量数据的分析(MapperReduce)③资源管理调度(YARN)。
(3)始于apache项目Nutch
2003年Google发表了关于GFS的论文
2004年Nutch的开发者开发了NDFS
2004年Google发表了关于MapReduce的论文
2005年MapReduce被引入了NDFS
2006年改名为Hadoop,NDFS的创始人加入Yahoo,Yahoo成立了一个专门的小组发展Hadoop
(4)Hadoop大事记
2004年-- 最初的版本(现在称为HDFS和MapReduce)由Doug Cutting和Mike Cafarella开始实施。
2005年12月-- Nutch移植到新的框架,Hadoop在20个节点上稳定运行。
2006年01月-- Doug Cutting加入雅虎。
2006年02月-- Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
2006年02月-- 雅虎的网格计算团队采用Hadoop。
2006年04月-- 标准排序(10 GB每个节点)在188个节点上运行47.9个小时。
2006年05月-- 雅虎建立了一个300个节点的Hadoop研究集群。
2006年05月-- 标准排序在500个节点上运行42个小时(硬件配置比4月的更好)。
2006年11月-- 研究集群增加到600个节点。
2006年12月-- 标准排序在20个节点上运行1.8个小时,100个节点3.3小时,500个节点5.2小时,900个节点7.8个小时。
2007年01月-- 研究集群到达900个节点。
2007年04月-- 研究集群达到两个1000个节点的集群。
2008年04月-- 赢得世界最快1TB数据排序在900个节点上用时209秒。
2008年10月-- 研究集群每天装载10 TB的数据。
2009年03月-- 17个集群总共24 000台机器。
2009年04月-- 赢得每分钟排序,59秒内排序500 GB(在1400个节点上)和173分钟内排序100 TB数据(在3400个节点上)。
二. 作者介绍
hadoop的作者是Doug Cutting,受Google三篇论文的启发(GFS、MapReduce、BigTable),Doug
Cutting开源的实现hadoop这个超级工程。
三. hadoop具体能干什么?
(1)hadoop擅长日志分析,facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的自定 义 筛选也使用的 Hive ;利用 Pig 还可以做高级的数据处理,包括 Twitter 、 LinkedIn 上用于发现您可能认识的人,可以实现类似 Amazon.com 的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有
用户特征建模。(2012年8月25新更新,天猫
的推荐系统是hive,少量尝试mahout!)
四. 哪些公司使用hadoop?
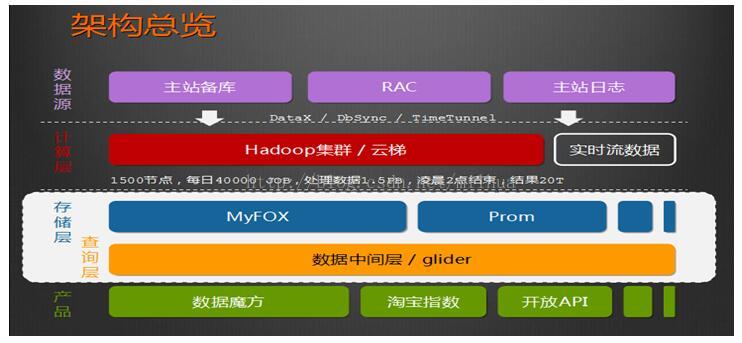
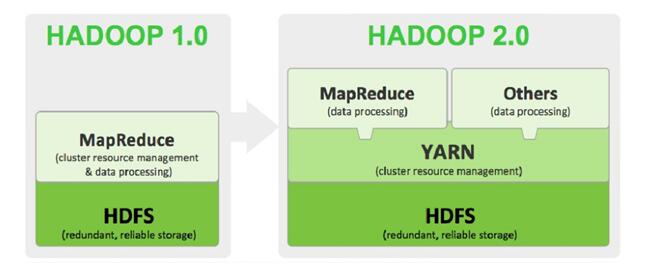
五. 架构总览
六. hadoop EcoSystem Map
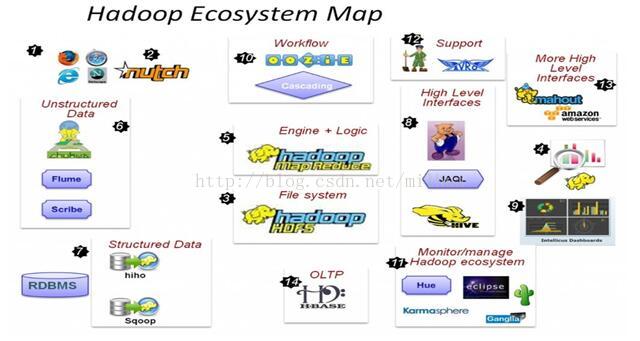
1. 这一切是如何开始的—Web上庞大的数据!
2.使用Nutch抓取Web数据
3.要保存Web上庞大的数据——HDFS应运而生
4.如何使用这些庞大的数据?
5.采用Java或任何的流/管道语言构建MapReduce框架用于编码并进行分析
6.如何获取Web日志,点击流,Apache日志,服务器日志等非结构化数据——fuse,webdav,chukwa, flume, Scribe
7.Hiho和sqoop将数据加载到HDFS中,关系型数据库也能够加入到Hadoop队伍中
8.MapReduce编程需要的高级接口——Pig,Hive, Jaql
9.具有先进的UI报表功能的BI工具- Intellicus
10.Map-Reduce处理过程使用的工作流工具及高级语言
11.监控、管理hadoop,运行jobs/hive,查看HDFS的高级视图—Hue,karmasphere, eclipse plugin, cacti, ganglia
12.支持框架—Avro(进行序列化), Zookeeper (用于协同)
13.更多高级接口——Mahout,Elastic map Reduce
14.同样可以进行OLTP——Hbase
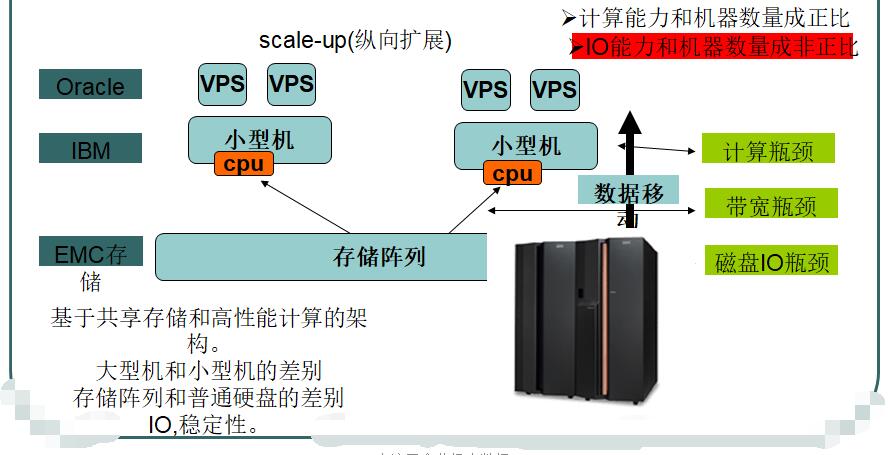
七. 集群存储和计算的主要瓶颈
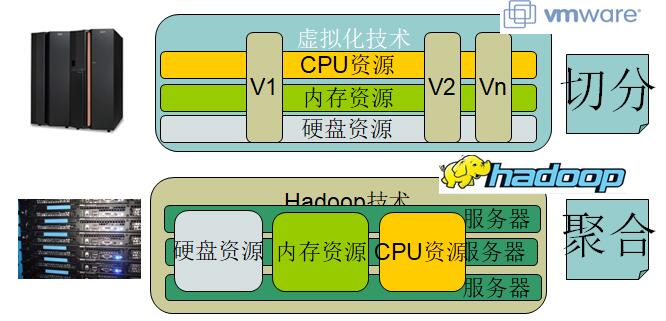
八. Hadoop和虚拟化的差异点
九. hadoop核心
十. hadoop的特点















 5836
5836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









