







正如标题说的一样,MapperReduce是一种很厉害的面向编程的分布式分析框架,MapperReduce使得hadoop更加有意义,虽然MapperReduce没有Spark计算速度快,但是MapperReduce也又很多优势,那什么是MapperReduce,又怎么解决海量数据的计算?
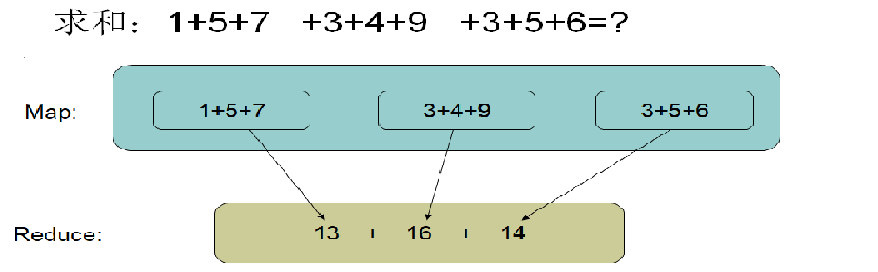
一. MapperReduce概述
(1)MapperReduce是一种分布式计算模型,由Google提供,主要运用于搜索领域,解决海量数据的计算问题。
(2)MR的组成:MapperReduce由Mapper和Reduce两部分组成,用户只需要实现Mapper类然后重写mapper()和继承Reducer类重写reduce(),即可实现分布式计算,非常简单!
(3)这两个函数的形参是key,value对,表示函数的输入和输出!
二. MapperReduce原理
在初探MapperReduce之前我们先来看看下面这张图,下图我用红色框出的A,B,C,D,E五个部分!
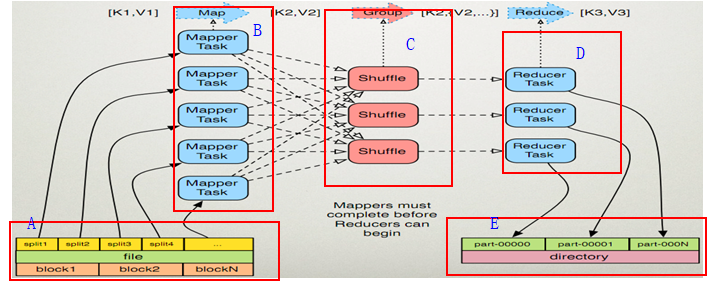
(1). MapperReduce是一个计算模型,在mapper阶段,用户只需要实现mapper()函数,其中有两个形参,代表输入和输出,那么mapper的数据来源就是hadoop的HDFS本地提供的,A部分代表HDFS文件系统中的某一个文件,这个文件在hdfs中分为三个block分布在放在文件系统中,3个block组合起来就是一个完整的文件,mapper通过切分一部分一部分地读取该文件。
(2) B部分代表的是Mapper的主要应用程序,做mapper运算。
(3)C部分是一个mapper传输数据到reduce的中间过程想,这个过程是用来提高MapperReduce计算速度的优化。
(4)D部分代表是的Reduce应用程序做Reduce相关的计算。
(5)E部分表示的是reduce计算要输出的目的地,这个输出是保存到文件中的,这些文件最终落地在HDFS文件系统中。
三. 任务处理
——MapperReuce把任务分层两个阶乘的任务,就是mapper任务跟reduce任务。
(1)mapper任务:
a. 读取输入文件的内容,解析成Key跟Value对。对输入文件的每一行解析成Key、Value对。每一个键值对调用一个mapper函数。
b. 写自己的逻辑,对输入进来的key、value处理,转换成新的key跟value。
(2)reduce处理任务:
a.在reduce之前有一个shuffle的过程对mapper的输入做合并、排序等操作。
b.写reduce逻辑,对mapper输入进来的key、value处理,转换成新的key、value输出。
c.把reduce的输出到文件中。
四. mapper跟reduce键值对格式

仔细分析mapper跟reduce他们对应的接口函数,就会发现其实他们的
输入键值对的格式是不一样的,reduce()的value值是一个数组来的,这个需要注意的地方的。















 1897
1897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









