









文章目录
准备
版本:
Centos7.6
JDK1.8
Scala2.11
Python2.7
Git1.8.3.1
Apache Maven3.8.1
CDH6.2.1
上述软件需提前安装
一、编译flink
- 下载flink1.14.4源码包
wget https://dlcdn.apache.org/flink/flink-1.14.4/flink-1.14.4-src.tgz
- 修改flink的pom.xml
tar zxf flink-1.14.4-src.tgz
cd flink-1.14.4/
vim pom.xml
# 修改haddop版本
<hadoop.version>3.0.0-cdh6.21</hadoop.version>
# 修改hive版本
<hive.version>2.1.1-cdh6.2.1</hive.version>
<hivemetastore.hadoop.version>3.0.0-cdh6.2.1</hivemetastore.hadoop.version>
# 添加cloudera源
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
- 编译flink(参考即可,可不做)
# 编译后文件在 flink-dist/target/flink-1.14.4-bin/flink-1.14.4
mvn clean install -DskipTests -Dfast -Drat.skip=true -Dhaoop.version=3.0.0-cdh6.2.1 -Dinclude-hadoop -Dscala-2.11 -T4C
注:编译flink过程中可能会提示io.confluent相关的包有问题,查询资料反馈是默认下载的包不完整,需删除已经下载的包,然后从https://packages.confluent.io/maven/io/confluent这个网站上下载对应的包放到maven repository目录
- 修改flink-sql-connector-hive-2.2.0的pom.xml
vim flink-connectors/flink-sql-connector-hive-2.2.0/pom.xml
# 修改hive-exec版本
<artifactId>hive-exec</artifactId>
<version>2.1.1-cdh6.3.2</version>
- 编译flink-sql-connector-hive-2.2.0(sql_on_hive需要做这步)
# 编译后文件在flink-connectors/flink-sql-connector-hive-2.2.0/target/
mvn clean install -DskipTests -Dscala-2.11 -T4C
- 拷贝相关jar包到flink/lib
# 拷贝flink-sql-connector-hive到flink的lib目录下
cp flink-connectors/flink-sql-connector-hive-2.2.0/target/flink-sql-connector-hive-2.2.0_2.11-1.14.4.jar /data/flink-1.14.4/lib/
# 拷贝hive-exec-2.1.1-cdh6.3.2.jar、libfb303-0.9.3.jar
cp /opt/cloudera/parcels/CDH/jars/hive-exec-2.1.1-cdh6.2.1.jar /data/flink-1.14.4/lib/
cp /opt/cloudera/parcels/CDH/jars/libfb303-0.9.3.jar /data/flink-1.14.4/lib/
- 打包已编译的flink源码
tar -czvf flink-1.14.4-scala_2.11.tgz flink-1.14.4
二、制作Flink的parcel包和csd文件
1. 下载制作脚本
# 克隆源码
git clone https://github.com/pkeropen/flink-parcel.git
cd flink-parcel
2 修改参数
vim flink-parcel.properties
#FLINK 下载地址
FLINK_URL= https://downloads.apache.org/flink/flink-1.14.4/flink-1.14.4-bin-scala_2.11.tgz
#flink版本号
FLINK_VERSION=1.14.4
#扩展版本号
EXTENS_VERSION=BIN-SCALA_2.11
#操作系统版本,以centos7为例
OS_VERSION=7
#CDH 小版本
CDH_MIN_FULL=5.15
CDH_MAX_FULL=6.2.1
#CDH大版本
CDH_MIN=5
CDH_MAX=6
3 复制安装包
这里把之前编译打包好的flink的tar包上复制到flink-parcel项目的根目录。flink-parcel在制作parcel时如果根目录没有flink包会从配置文件里的地址下载flink的tar包到项目根目录。如果根目录已存在安装包则会跳过下载,使用已有tar包。
提示:注意:这里一定要用自己编译的包,不要用从链接下载的包!!!
4 编译parcel
# 赋予执行权限
chmod +x ./build.sh
# 执行编译脚本
./build.sh parcel
编译完会在flink-parcel项目根目录下生成FLINK-1.12.0-BIN-SCALA_2.11_build文件夹
5 编译csd
# 编译flink on yarn版本
./build.sh csd_on_yarn
csd文件是组件的导航文件
编译完成后在flink-parcel项目根目录下会生成1个jar包 FLINK_ON_YARN-1.14.4.jar
6 上传文件
将编译parcel后生成的FLINK-1.14.0-BIN-SCALA_2.11_build文件夹内的3个文件复制到CDH Server所在节点的/opt/cloudera/parcel-repo目录。将编译csd生成后的FLINK_ON_YARN-1.14.4.jar复制到CDH Server所在节点的/opt/cloudera/csd目录
# 复制parcel,这里就是在主节点编译的,如果非主节点,可以scp过去
cp FLINK-1.14.4-BIN-SCALA_2.11_build/* /opt/cloudera/parcel-repo
# 复制scd,这里就是在主节点编译的,如果非主节点,可以scp过去
cp FLINK_ON_YARN-1.14.4.jar /opt/cloudera/csd/
7 重启CDH server
# 重启server(仅server节点执行)
systemctl restart cloudera-scm-server
三、CDH集成
操作步骤

1.打开CDH登录界面
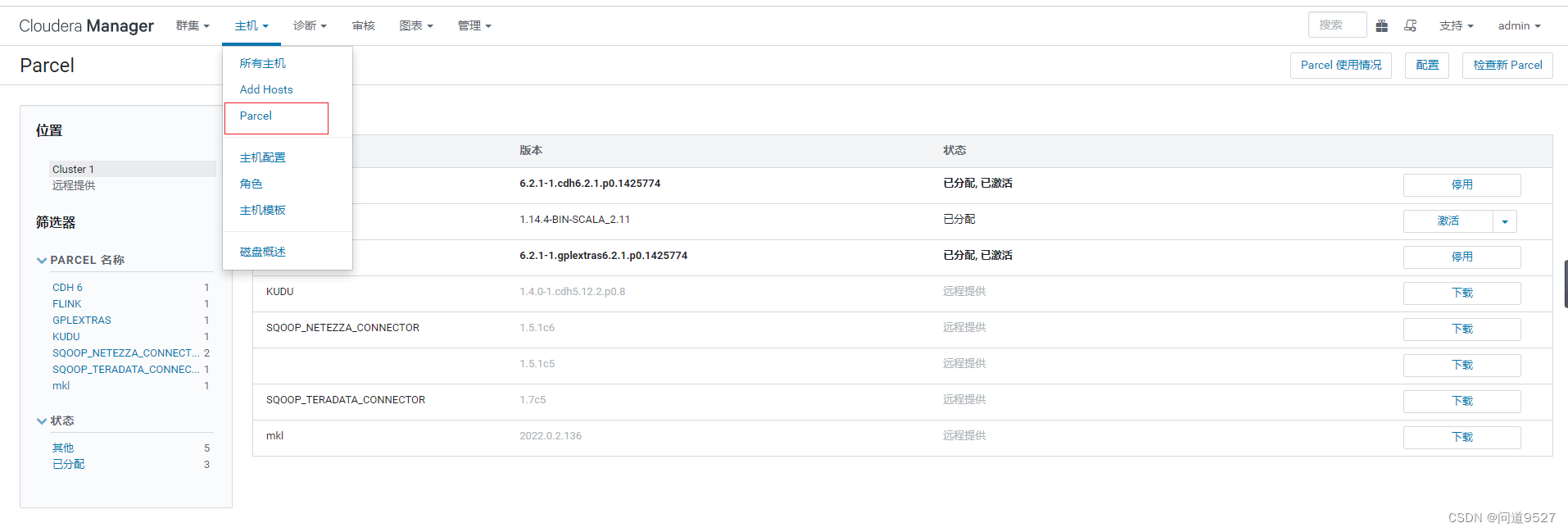
2 进入Parcel操作界面
点击 主机->Parcel
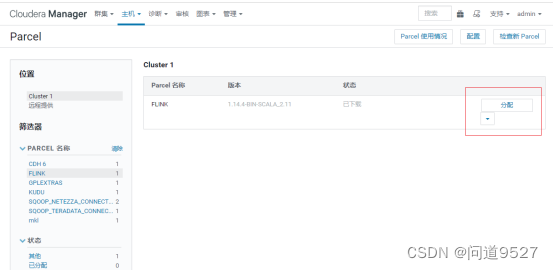
3 分配Parcel
点击分配,等待分配完毕
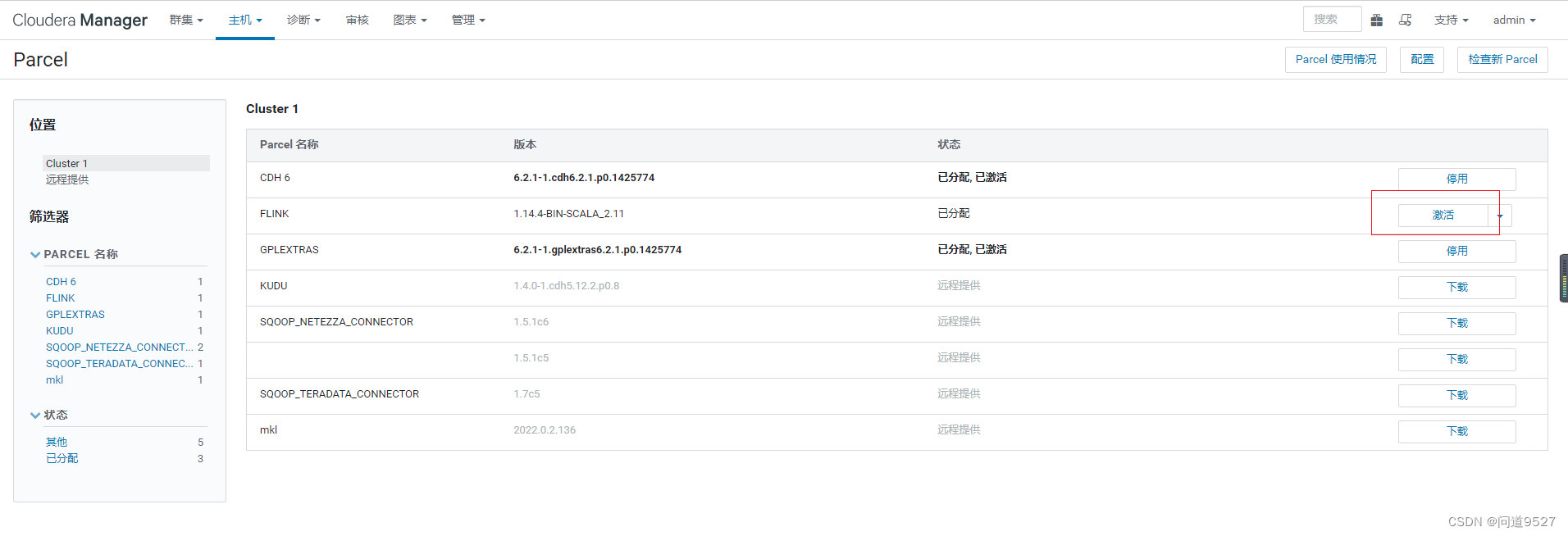
4 激活Parcel
点击激活 点击确定,等待激活完毕
5 回主界面
点击点击Cloudera Manager
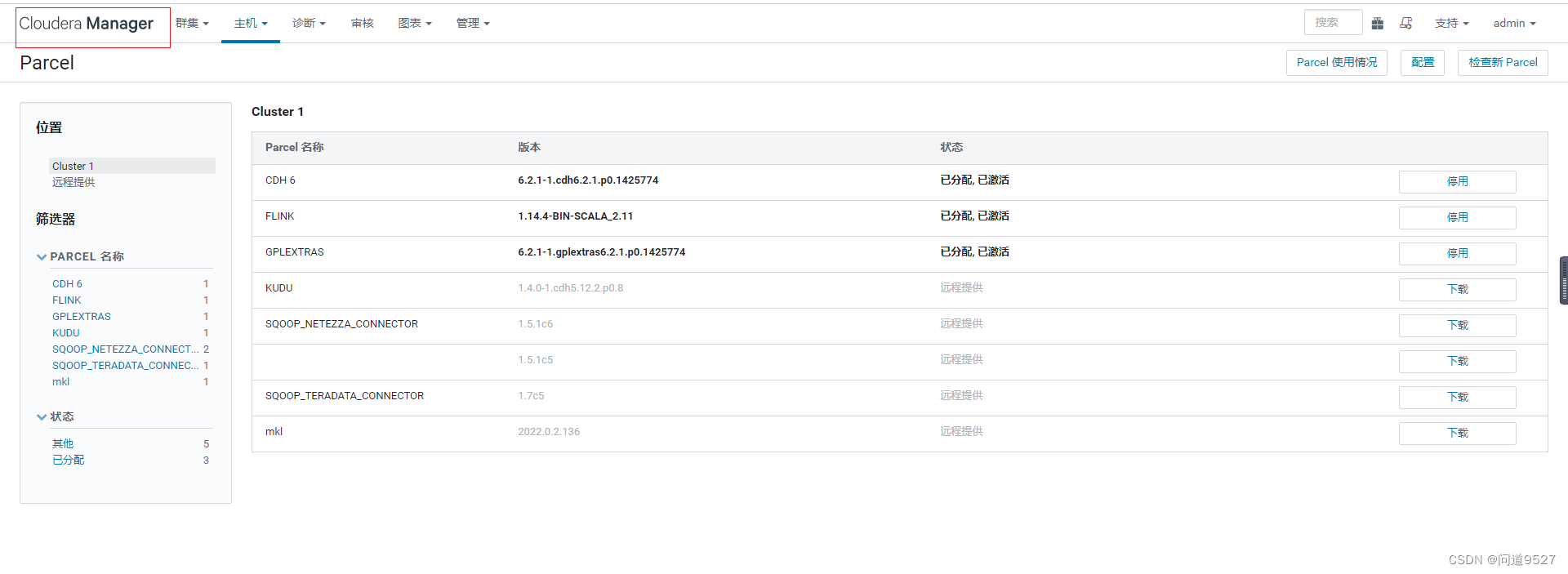
6.添加flink服务
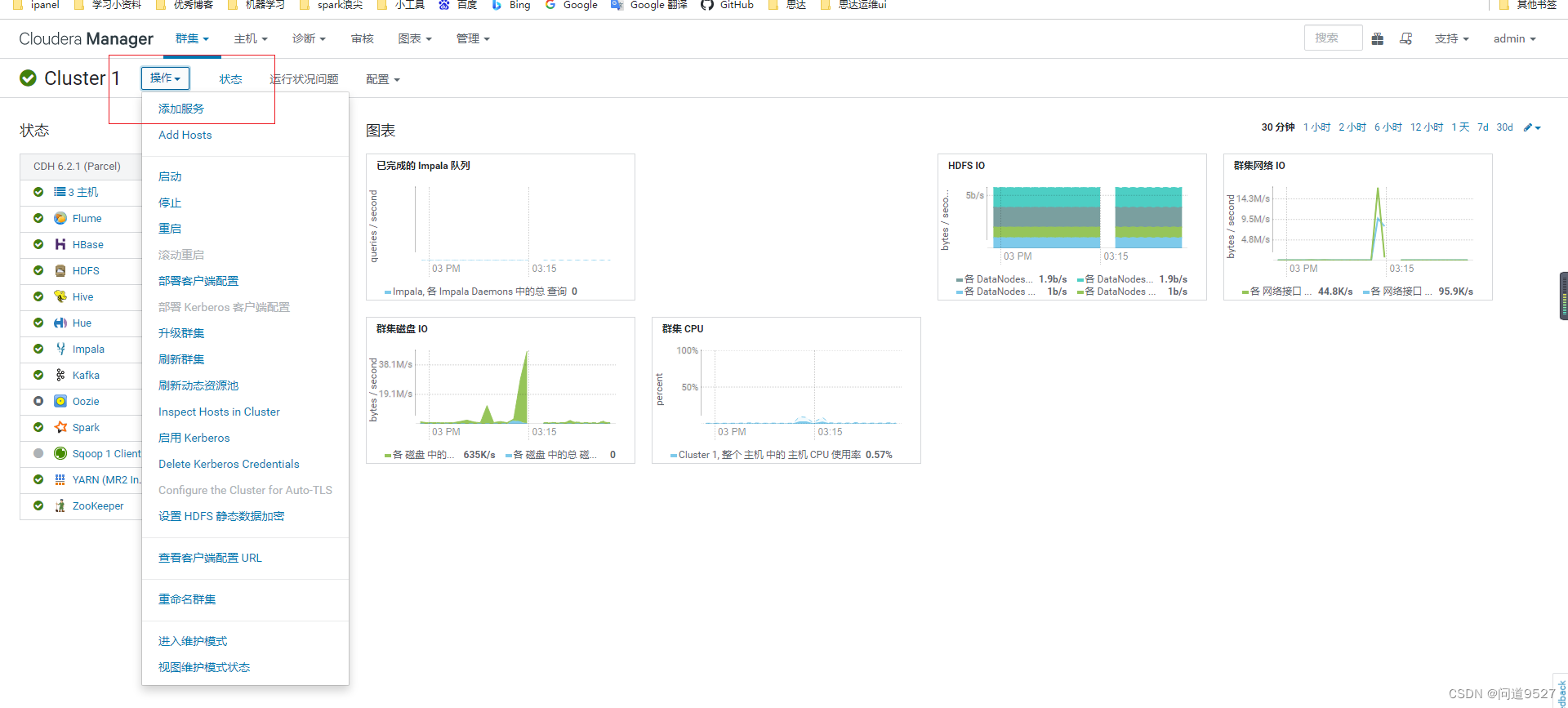
点击倒三角,点击添加服务
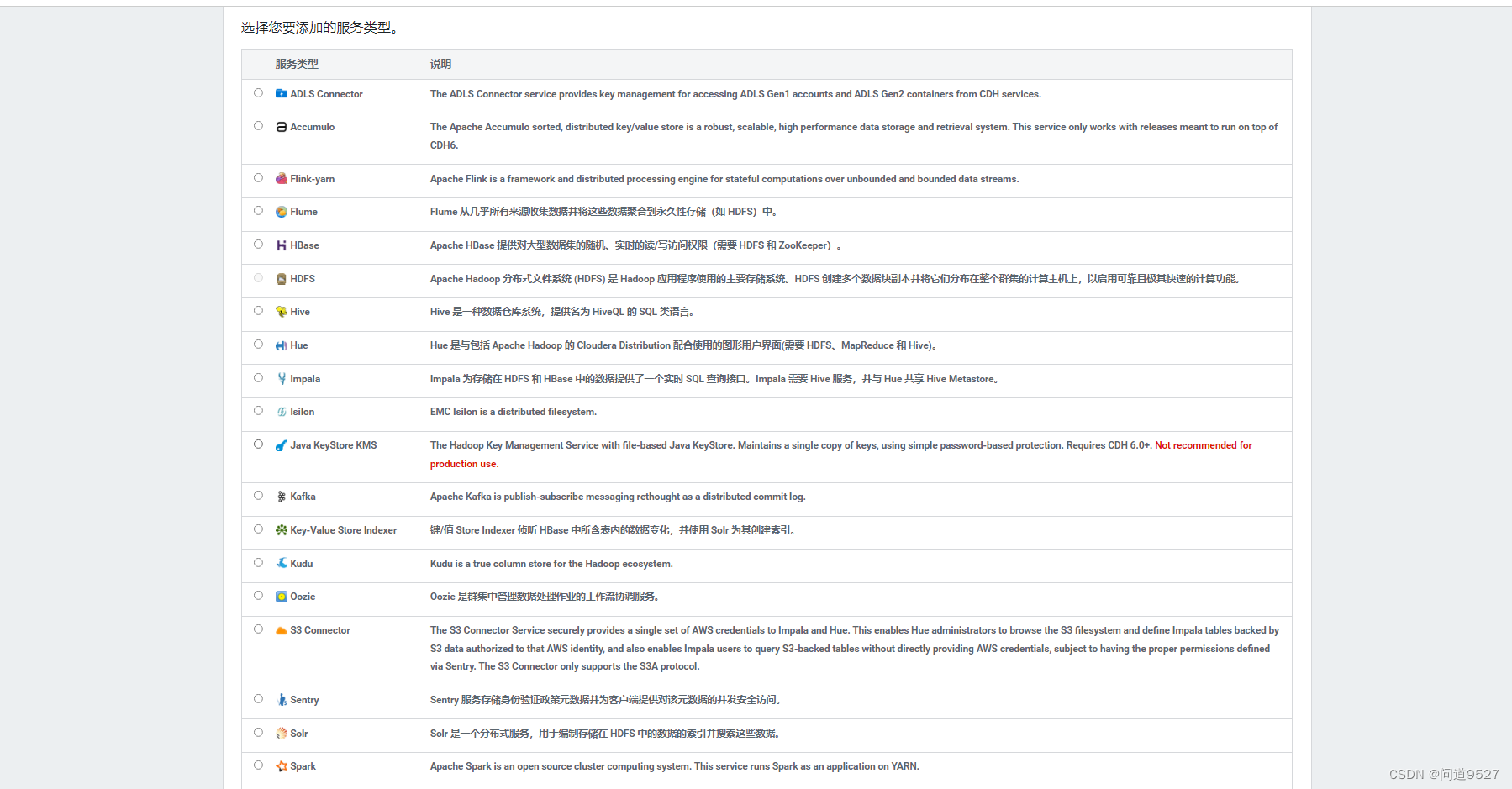
- 点击Flink-yarn,点击继续

- 点击选择主机,选择在哪些节点部署flink服务,根据自己情况自己选择
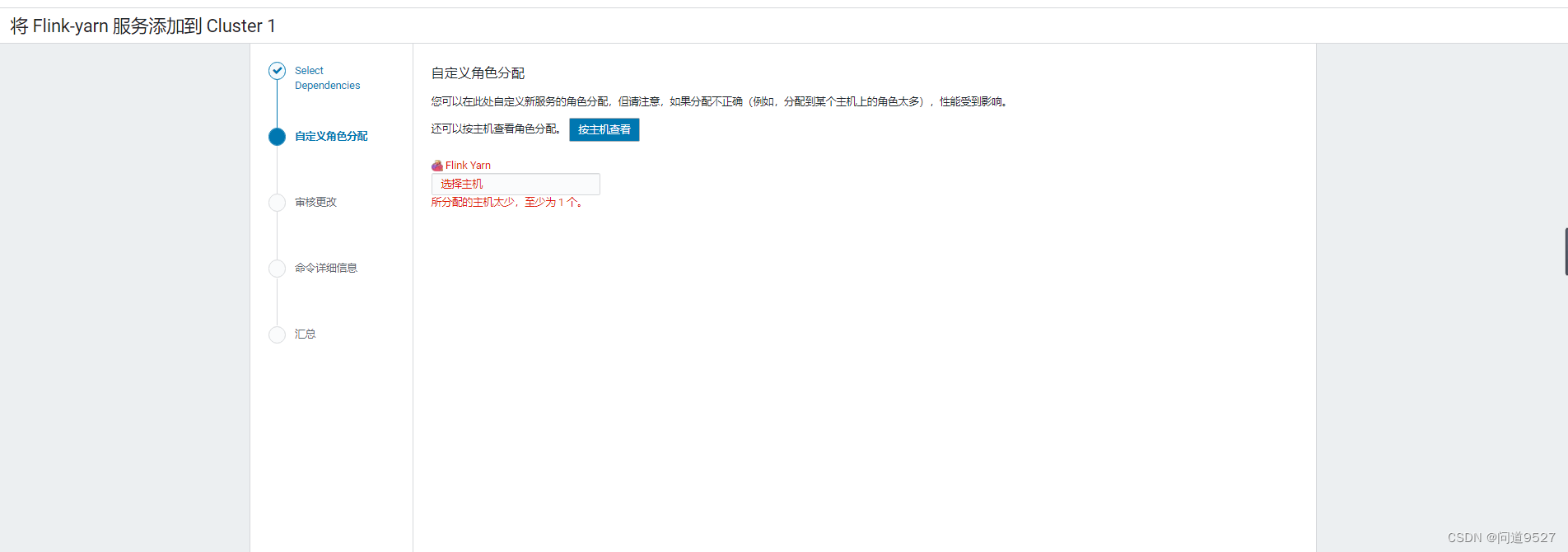
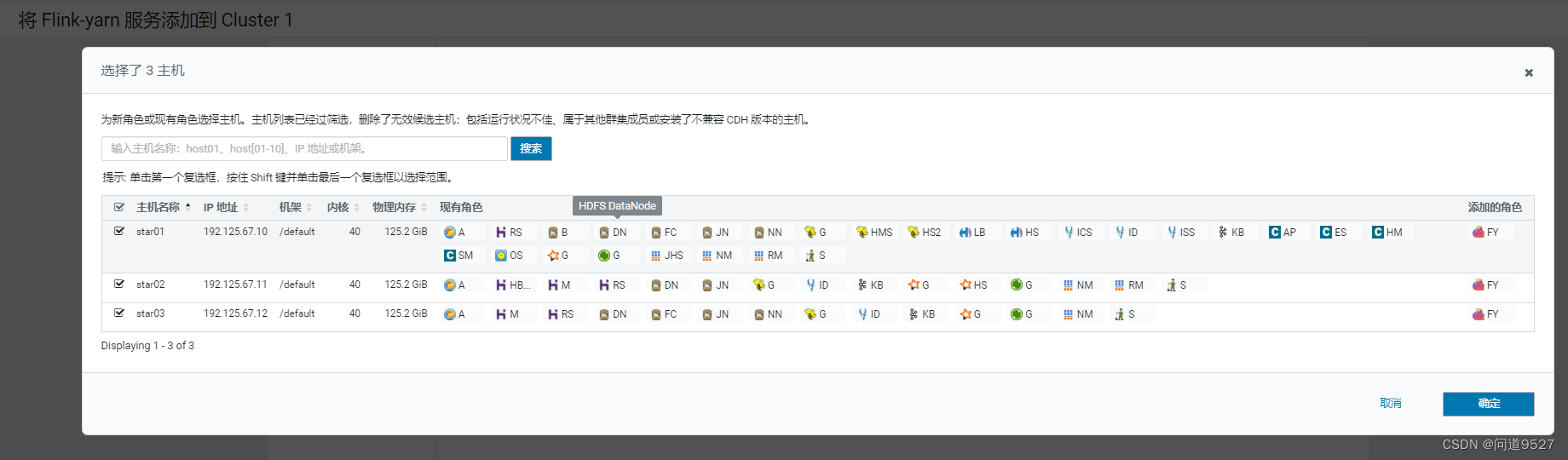
-
选择主机,点击继续
-
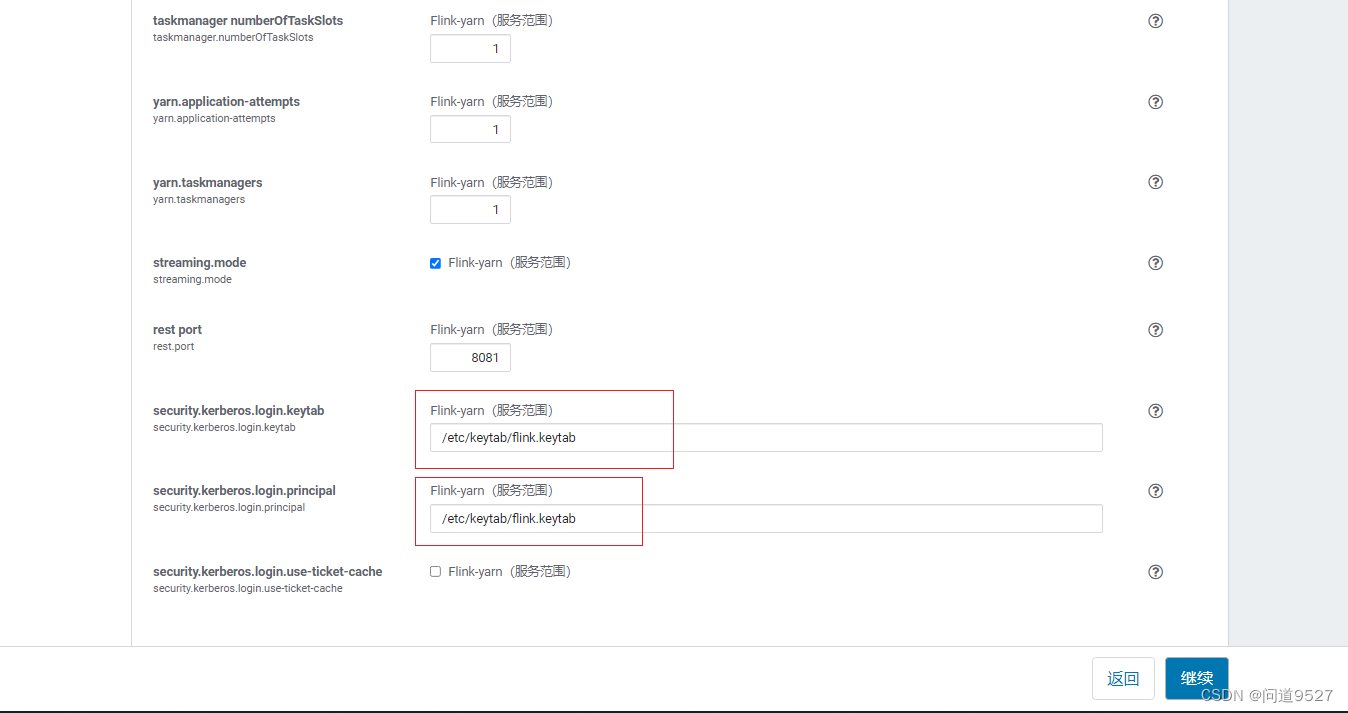
审核更改
将这两项配置security.kerberos.login.keytab、security.kerberos.login.principal设置为空字符串,点击继续
这里就开始运行了,这一步运行失败了
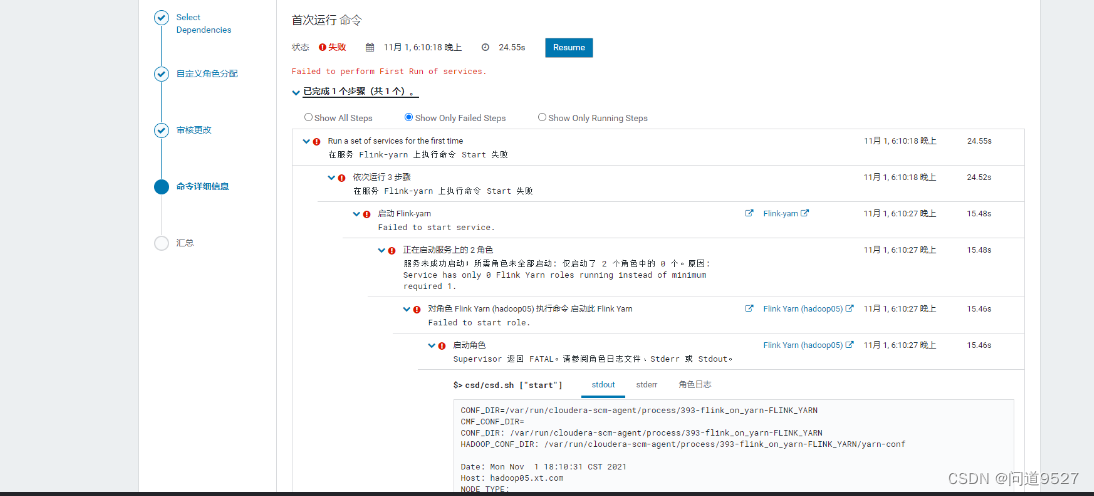
错误1
/opt/cloudera/parcels/FLINK/lib/flink/bin/flink-yarn.sh: line 17: rotateLogFilesWithPrefix: command not found
完整日志
+ sed -i 's#=#: #g' /var/run/cloudera-scm-agent/process/2468-flink_on_yarn-FLINK_YARN/flink-conf.properties
++ cat /var/run/cloudera-scm-agent/process/2468-flink_on_yarn-FLINK_YARN/flink-conf.properties
++ grep high-availability:
+ HIGH_MODE='high-availability: zookeeper'
+ '[' 'high-availability: zookeeper' = '' ']'
++ cat /var/run/cloudera-scm-agent/process/2468-flink_on_yarn-FLINK_YARN/flink-conf.properties
++ grep high-availability.zookeeper.quorum:
+ HIGH_ZK_QUORUM='high-availability.zookeeper.quorum: star01:2181,star02:2181,star03:2181'
+ '[' 'high-availability.zookeeper.quorum: star01:2181,star02:2181,star03:2181' = '' ']'
+ cp /var/run/cloudera-scm-agent/process/2468-flink_on_yarn-FLINK_YARN/flink-conf.properties /var/run/cloudera-scm-agent/process/2468-flink_on_yarn-FLINK_YARN/flink-conf/flink-conf.yaml
+ HADOOP_CONF_DIR=/var/run/cloudera-scm-agent/process/2468-flink_on_yarn-FLINK_YARN/yarn-conf
+ export FLINK_HOME FLINK_CONF_DIR HADOOP_CONF_DIR
+ echo CONF_DIR: /var/run/cloudera-scm-agent/process/2468-flink_on_yarn-FLINK_YARN
+ echo HADOOP_CONF_DIR: /var/run/cloudera-scm-agent/process/2468-flink_on_yarn-FLINK_YARN/yarn-conf
+ echo ''
++ date
+ echo 'Date: Thu May 5 15:33:04 CST 2022'
+ echo 'Host: star03'
+ echo 'NODE_TYPE: '
+ echo 'ZK_QUORUM: star01:2181,star02:2181,star03:2181'
+ echo 'FLINK_HOME: /opt/cloudera/parcels/FLINK/lib/flink'
+ echo 'FLINK_CONF_DIR: /var/run/cloudera-scm-agent/process/2468-flink_on_yarn-FLINK_YARN/flink-conf'
+ echo ''
+ '[' true = true ']'
+ exec /opt/cloudera/parcels/FLINK/lib/flink/bin/flink-yarn.sh --container 1 --streaming
/opt/cloudera/parcels/FLINK/lib/flink/bin/flink-yarn.sh: line 17: rotateLogFilesWithPrefix: command not found
解决:
参考链接 rotateLogFilesWithPrefix: command not found
vim /opt/cloudera/parcels/FLINK/lib/flink/bin/config.sh:391 加入
rotateLogFilesWithPrefix() {
dir=$1
prefix=$2
while read -r log ; do
rotateLogFile "$log"
# find distinct set of log file names, ignoring the rotation number (trailing dot and digit)
done < <(find "$dir" ! -type d -path "${prefix}*" | sed s/\.[0-9][0-9]*$// | sort | uniq)
}
# 旋转日志文件
rotateLogFile() {
log=$1;
num=$MAX_LOG_FILE_NUMBER
if [ -f "$log" -a "$num" -gt 0 ]; then
while [ $num -gt 1 ]; do
prev=`expr $num - 1`
[ -f "$log.$prev" ] && mv "$log.$prev" "$log.$num"
num=$prev
done
mv "$log" "$log.$num";
fi
}
错误2
错误1已经处理完毕,重启后依旧报错,但没有具体的错误输出,但是通过日志,可以看到提示HBASE环境变量未设置
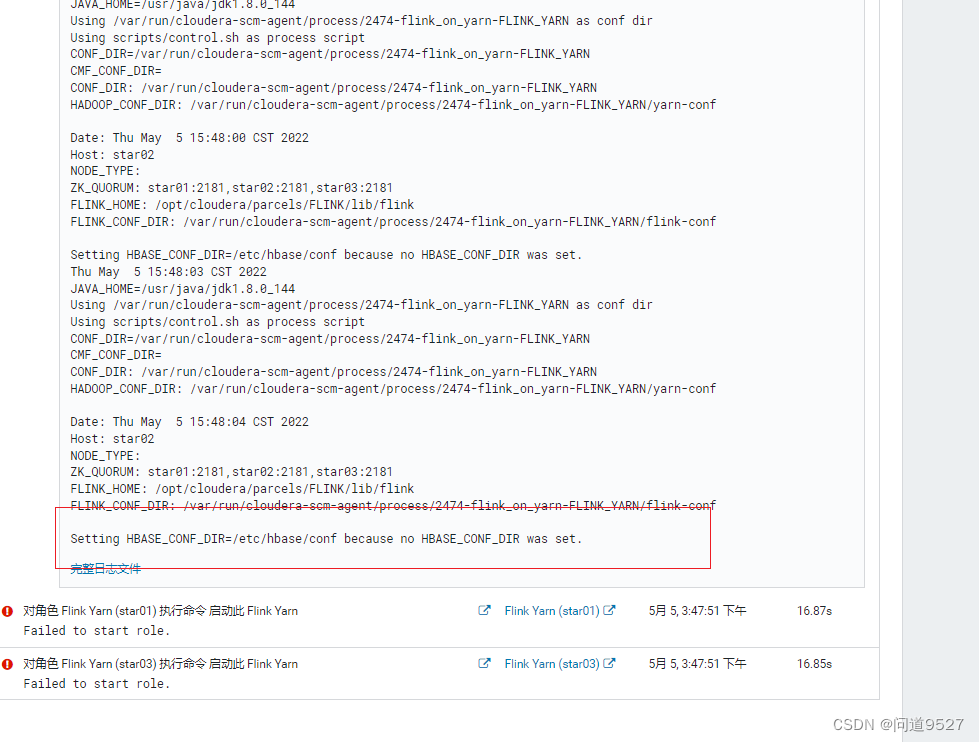
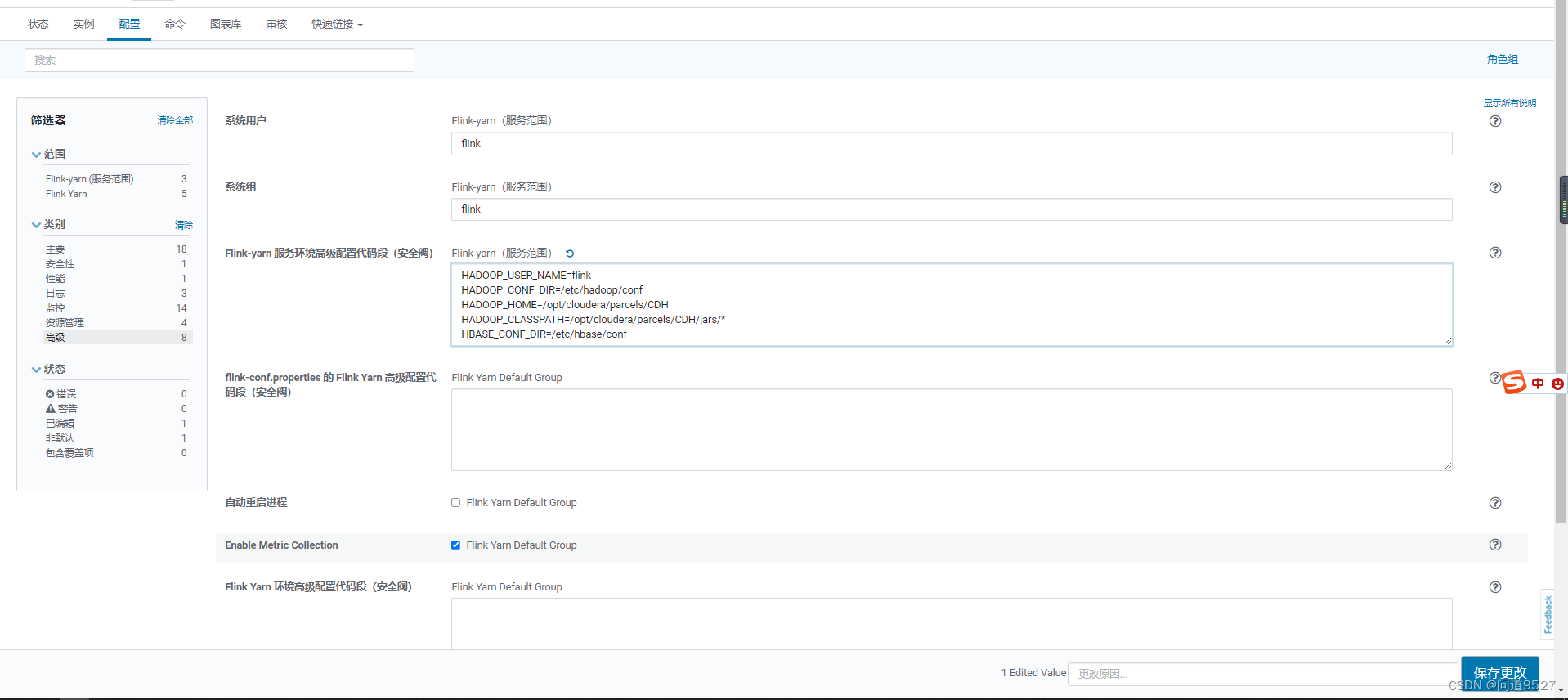
解决:
Flink-yarn -> 配置 -> 高级 -> Flink-yarn 服务环境高级配置代码段(安全阀)Flink-yarn(服务范围)加入以下内容即可:
HADOOP_USER_NAME=flink
HADOOP_CONF_DIR=/etc/hadoop/conf
HADOOP_HOME=/opt/cloudera/parcels/CDH
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/jars/*
HBASE_CONF_DIR=/etc/hbase/conf
四、验证Flink服务
1、运行一个WordCount测试
./flink run -t yarn-per-job /opt/cloudera/parcels/FLINK/lib/flink/examples/batch/WordCount.jar
错误3
-----------------------------------------------------------
The program finished with the following exception:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment" section of the official Apache Flink documentation.
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:372)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:812)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:246)
at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1054)
at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1132)
at org.apache.flink.runtime.security.contexts.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:28)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1132)
Caused by: java.lang.IllegalStateException: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment" section of the official Apache Flink documentation.
at org.apache.flink.yarn.executors.YarnJobClusterExecutorFactory.getExecutor(YarnJobClusterExecutorFactory.java:50)
at org.apache.flink.api.java.ExecutionEnvironment.executeAsync(ExecutionEnvironment.java:1052)
at org.apache.flink.client.program.ContextEnvironment.executeAsync(ContextEnvironment.java:131)
at org.apache.flink.client.program.ContextEnvironment.execute(ContextEnvironment.java:70)
at org.apache.flink.api.java.ExecutionEnvironment.execute(ExecutionEnvironment.java:942)
at org.apache.flink.api.java.DataSet.collect(DataSet.java:417)
at org.apache.flink.api.java.DataSet.print(DataSet.java:1748)
at org.apache.flink.examples.java.wordcount.WordCount.main(WordCount.java:96)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:355)
... 8 more
原因:
解决:
# 在环境变量中加入
export HADOOP_CLASSPATH=`hadoop classpath`
错误4
Caused by: org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:256)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1855)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1839)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1798)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:61)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3101)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1123)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:696)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:870)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:816)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2680)
解决:
groupadd supergroup
usermod -a -G supergroup root
hdfs dfsadmin -refreshUserToGroupsMappings
# su - hdfs -s /bin/bash -c "hdfs dfsadmin -refreshUserToGroupsMappings"















 2897
2897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









