







文章目录
1.简介
Mapreduce 是hadoop项目中的分布式运算程序的编程框架,是用户开发"基于hadoop的数据分析应用"的核心框架,Mapreduce 程序本质上是并行运行的。分布式程序运行在大规模计算机集群上,可以并行执行大规模数据处理任务,从而获得巨大的计算能力。谷歌公司最先提出了分布式并行编程模型MapReduce,Hadoop MapReduce是它的开源实现,主要应用于离线计算的场景。
2.MapReduce优缺点
优点:
- 易于编程:它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的机器上运行。
- 良好扩展性:可以动态增加服务器,解决计算资源不够问题。
- 高容错性:任何一台机器挂掉,可以将任务转移到其他节点。
- 适合海量数据计算(TB、PB)几千台服务器共同计算。
缺点:
- 不擅长实时计算:MR擅长处理分钟、小时级别任务
- 不擅长流式计算:Sparkstreaming、flink(擅长流式计算)
- 不擅长DAG(有向无环图)计算
3.MapReduce执行原理
3.1.MapReduce组成概念
- Map阶段是一个独立的程序可以在多个节点运行,每个节点处理一部分数据。
- Reduce阶段也是一个独立程序,可以在一个或多个节点同时运行,每个节点处理一部分数据;如果是全局聚合需求,则Reduce阶段只会在一个节点运行。
Map阶段是对海量数据的局部汇总,Reduce阶段是对局部汇总的数据进行全局汇总。
举个简单的例子,学生在期末考试完需要老师批改考卷并且计算平均分,如果老师一个人批改试卷花费的时间比较长,这个时候可以考虑使用MapReduce计算思想.
- 第一步: 把试卷平均分配给班上成绩好的组长去批改。
- 第二步: 每个组长批改完试卷打分。
- 第三步: 老师把每个组长改完的试卷汇总并计算平均分。
由上可以看到MapReduce用的是分治算法。
分治是一种处理问题的思想,递归是一种编程技巧。实际上,分治算法一般都比较适合用递归来实现,其实现的每一层递归都会涉及这样的三个操作:
- 分解:将原问题分解成一系列子问题;
- 解决:递归地求解各个子问题,若子问题足够小,则直接求解;
- 合并:将子问题的结果合并成原问题
3.2.移动计算:
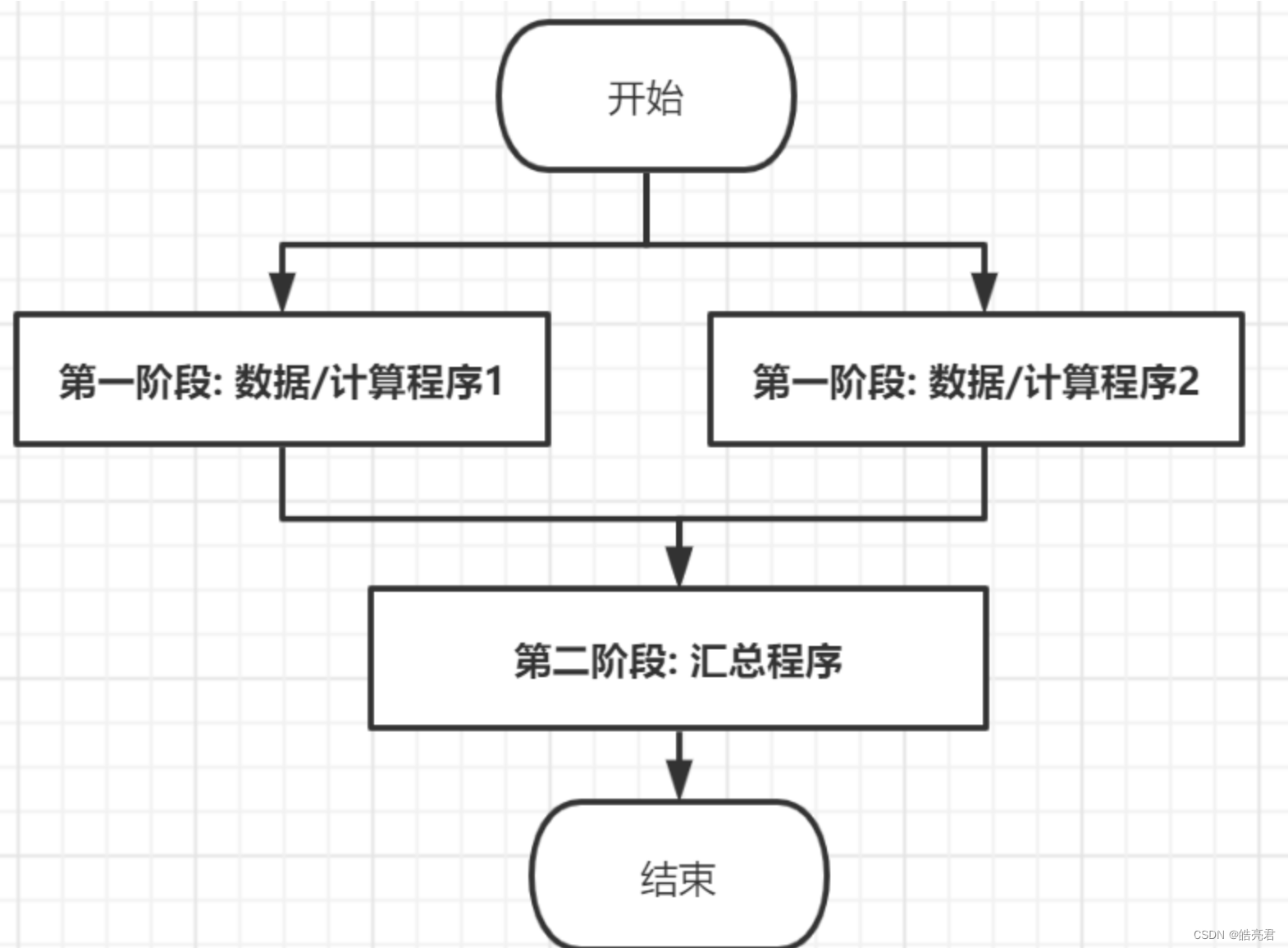
MapReduce在计算海量数据时还用到一个比较重要的思想:移动计算。
-
传统的计算方式是把需要计算的数据通过网络传递到计算程序的节点上,如果需要计算的数据量比较大,受磁盘I/O和网络I/O影响这种效率就比较低,这种计算方式称为移动数据。
-
如果把计算程序移动到数据所在的节点,即计算程序和数据在同一个节点上,则可以节省网络I/O,这种方式被称为移动计算,但是这种计算当前节点上的数据,无法汇总全局数据,所以还需要一个汇总程序,这样每个数据节点上计算的临时结果就可以通过汇总程序得到最终结果。
3.3.执行流程

Map阶段:
- 1.对文件进行逻辑切片split,默认大小等于hdfs中block块的大小,特殊情况split大小会比block大,(当文件剩余大小/128MB)<=1.1时,会将剩余的内容划分到一个Split中。在任务执行时针对每个Split都会产生一个Map Task。
- 2.对切片中的数据按行读取,解析返回<K,V>形式,key为每一行的偏移量,value为每一行的数据。
- 3.调用map方法处理数据,读取一行调用一次。
- 4.对map方法计算的数据进行分区partition,排序sort
默认不分区,因为只有一个reduceTask处理数据,分区数=reduceTask数,计算规则:key的hash值对reduce取模,保证相同key一定在同一分区 - 5.map输出数据一同写入到数据缓冲区,达到一定的条件溢写到磁盘
- 6.spill溢出的文件进行combiner规约,combiner为map阶段的reduce,并不是每个mapTask都有该流程,对于combine需要慎用,例如:求平均数,如果提前combine则会导致最终的计算结果不一致
- 7.对所有溢出的文件(分区且有序)进行最终merge合并,成为一个大文件
Reduce阶段:
- 1.从MapTask复制拉取其对应的分区文件
- 2.将copy的数据进行merge合并,再对合并后的数据排序,默认按照key字典序排序
- 3.对排序后的数据调用reduce方法
4.MapReduce架构分析
在Hadoop3.x中,MapReduce是在YARN中执行的,下面分析一下MapReduce在YARN上运行架构。
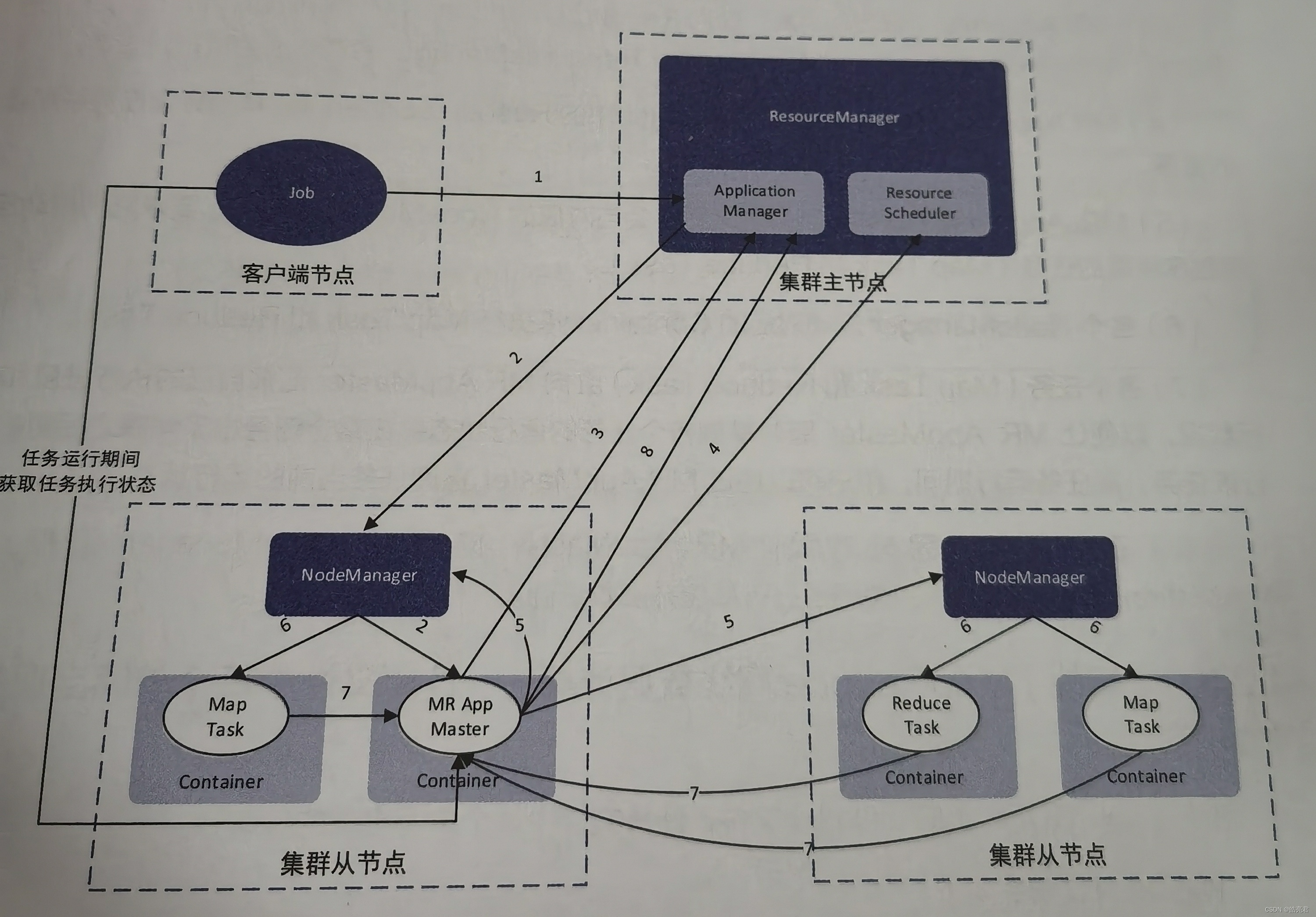
Yarn资源调度框架由以下几个组件组成:
- ResourceManager:全局的资源管理器,负责整个系统的资源管理。
- ResourceScheduler:资源调度器,负责应用程序的作业调度。
- ApplicationManager:每个应用程序的管理器,管理由ResourceManager分配的NodeManager节点
- NodeManager:每个计算节点上的资源和任务管理器。
- Container:NodeManager节点中内存、CPU等资源的容器。
MapReduce在YARN上的运行大致可以分为两个阶段。
第一阶段: ResourceManager中的ApplicationManager启动MR AppMaster进程,MR AppMaster是MapReduce ApplicationMaster的简写,主要负责管理MapReduce任务的生命周期,对于每一个MapReduce任务都会启动一个AppMaster进程。
第二阶段: MR AppMaster创建应用程序,申请资源并且监控应用的运行状态。
详细执行流程如下:
- 1.用户通过Job(客户端)节点向集群提交任务,该任务首先会找到ResourceManager中的ApplicationManager。
- 2.ApplicationManager在接受任务后,会在集群中找一个NodeManager,并在该NodeManager所在的节点上分配一个Container,在这个Container中启动任务对应的MR AppMaster进程,改进程用于进行任务的划分和任务的监控。
- 3.MR AppMaster在启动之后,会向ResourceManager中ApplicationManager注册其信息,目的是与之通信。这样用户就可以通过ResourceManager查询作业的运行状态。
- 4.MR AppMaster向ResourceManager中的ResourceScheduler申请计算任务所需要的资源。
- 5.MR AppMaster在申请到资源之后,会与对应的NodeManager通信,要求它们启动应用程序所需的任务(Map Task和Reduce Task)。
- 6.各个NodeManager启动对应的Container来执行Map Task和Reduce Task。
- 7.各个任务会向MR AppMaster汇报自己的执行进度和执行状态,以便让MR AppMaster随时掌握各个任务的运行状态,在某个任务出了问题之后重启珍惜改任务。
- 8.在任务执行完成之后,MR AppMaster向ApplicationManager汇报,让ApplicationManager注销并关闭自己,释放资源。
5.Java创建MapReduce任务
需求: 读取HDFS上的hello.txt,计算文件中每个单词出现的总次数并输出到output文件中,hello.txt内容格式如下
hello word
在Java中MapReduce开发流程如下:
- 1.开发Map阶段代码。
- 2.开发Reduce阶段代码
- 3.组装MapReduce任务
- 4.打包上传到服务器上,通过hadoop命令启动任务。
5.1.引入Hadoop相关依赖并配置打包插件
- 需要修改mainClass标签内容指定启动类的路径
- hadoop集群中包含了hadoop-client.jar依赖,所以此处设置scope作用域为编译时使用该依赖。
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.4</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<finalName>mapreduce</finalName>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!--配置jar的启动类-->
<mainClass>job.WordCountJob</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
5.2.开发Map阶段代码
public class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//key:每一行数据的行首偏移量 value:每一行数据
//在这里对获取到的每一行数据进行拆分,把单词拆分出来
String[] words = value.toString().split(" ");
Text key2;
LongWritable value2;
//跌打拆分出来的数据
for (String word : words) {
//把迭代后的单词封装成<key2,value2>形式
key2 = new Text(word);
value2 = new LongWritable(1L);
//写出数据
context.write(key2, value2);
}
}
}
5.3.开发Reduce阶段代码
public class MyReduce extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//求和
long sum = 0L;
for (LongWritable value : values) {
sum += value.get();
}
//组装数据输出
LongWritable value = new LongWritable(sum);
context.write(key, value);
}
}
5.4.组装MapReduce任务
public class WordCountJob {
public static void main(String[] args) throws Exception {
//Job需要配置的参数
Configuration configuration = new Configuration();
//创建一个任务
Job job = Job.getInstance(configuration);
//这一行必须设置
job.setJarByClass(WordCountJob.class);
//指定输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定Map使用的类
job.setMapperClass(MyMapper.class);
//指定key的类型
job.setMapOutputKeyClass(Text.class);
//指定value的类型
job.setMapOutputValueClass(LongWritable.class);
//指定Reduce相关的代码
job.setReducerClass(MyReduce.class);
//指定key类型
job.setOutputKeyClass(Text.class);
//指定value的类型
job.setOutputValueClass(LongWritable.class);
//提交任务
job.waitForCompletion(true);
}
}
5.5.测试
在idea里执行以下命令打包
mvn clean package
上传mapreduce-jar-with-dependencies.jar到hadoop集群服务器上面
创建任务测试用的文件hello.txt,添加几行数据。
vi hello.txt
hello word
hello dominick_Li
hello lijunming
:wq保存文件然后执行下面命令上传文件到hdfs中
hdfs dfs -put hello.txt /
启动MapReduce任务
- 启动任务前需要先启动hadoop服务
- 指定任务输入文件为hdfs根目录下的hello.txt文件
- 指定任务输出结果目录为/output目录
hadoop jar mapreduce-jar-with-dependencies.jar /hello.txt /output

注意: /output必须是一个不存在的目录,要不然会报错FileAlreadyExistsException: Output directory hdfs://master:9000/output already exists
通过YARN提供的页面查看任务执行情况
使用浏览器访问: http://集群主节点ip:8088/cluster
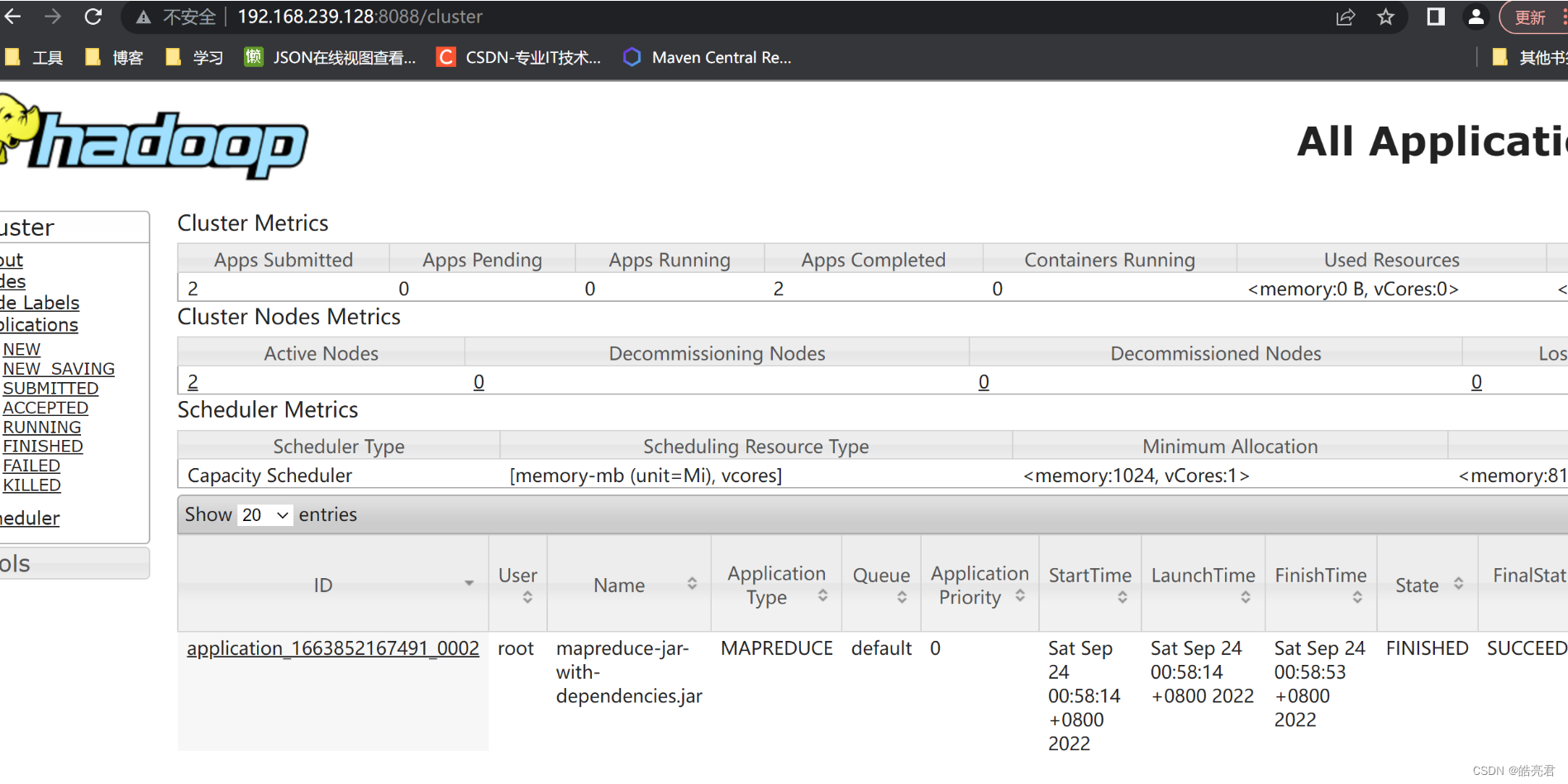
查看任务结果
查看任务结果保存目录的文件信息
[root@master soft]# hdfs dfs -ls /output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2022-09-24 00:58 /output/_SUCCESS
-rw-r--r-- 2 root supergroup 41 2022-09-24 00:58 /output/part-r-00000
output目录下的文件说明如下:
_SUCCESS: 标识文件,存在这个文件表示这个任务执行成功了。
part-r-00000: 是执行结果文件,如果有多个Reduce Task则会产生多个结果文件,命名规则按照 part-r-00001, part-r-00002, part-r-0000N,…等。
查看结果文件内容:
[root@master soft]# hdfs dfs -cat /output/part-r-00000
dominick_Li 1
hello 3
lijunming 1
word 1
【Hadoop生态圈】其它文章如下,后续会继续更新。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











