






近日需要使用python爬虫寻找一些数据,因此总结了近日的学习记录。
1. 爬虫基础流程
# 发送HTTP请求:获取网页内容(HTML/JSON)。
# 解析数据:从HTML中提取目标信息(如链接、文本、图片)。
# 存储数据:保存到文件(CSV、JSON、数据库)。
# 遵守规则:处理反爬机制(如User-Agent、限速、验证码)。
2. 相关库:
import requests as rq
# from bs4 import BeautifulSoup
# from lxml import etree
import re
import pandas as pd
import numpy as np
import timerequests库是用来爬取网站信息的,re是正则表达式库、pandas用来将数据变成cvs文件储存、time库用来延时,防止被网站屏蔽
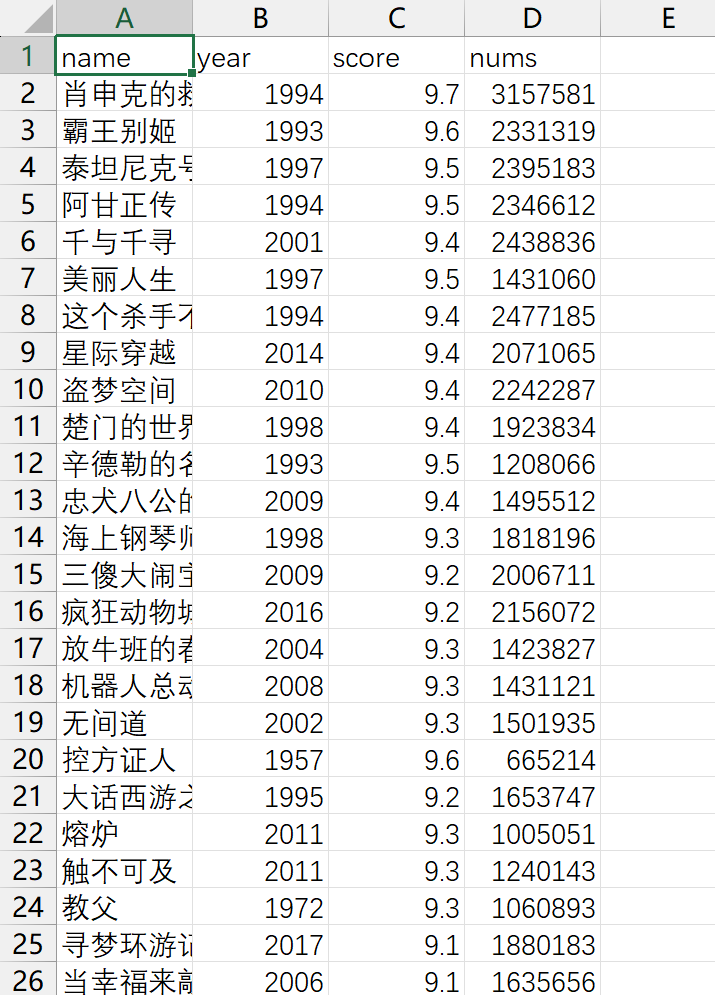
3. 举例:获取豆瓣电影排行榜的名字,年份,评分、评分人数
def func(filename, secquence):
# 1.先获取请求
headers = {"user-agent" :"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36"}
# parma = { "wd" : "python",}
url = "https://movie.douban.com//top250" + "?start=" + str(secquence) + "&filter="
print(url)
r = rq.get(url, headers=headers)
print(r.status_code, "\n")
# 2.解析数据
# html = etree.HTML(r.text)
# print(html, "\n")
# 获取豆瓣电影排行榜的名字,年份,评分、评分人数
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<p>.*?<br>(?P<year>.*?) '
r'.*?property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<nums>.*?)人评价</span>', re.S)
res = obj.finditer(r.text)
# 3.读取数据,保存数据
data = []
for ite in res:
data.append([ite.group("name"),
ite.group("year").strip(),
ite.group("score"),
ite.group("nums")])
# print(ite.group("name"),
# ite.group("year").strip(),
# ite.group("score"),
# ite.group("nums"))
columns = ["name", "year", "score", "nums"]
df = pd.DataFrame(columns=columns, data= data)
df.to_csv(filename, mode='a', header=False, index=False, na_rep='N/A', encoding='utf-8-sig')
if __name__ == "__main__":
# arr = np.linspace
filename = "豆瓣电影排行榜top250.csv"
for seq in [0,25,50,75,100,125,150,175,200,225]:
func(filename, seq)
time.sleep(0.5)爬取结果:截图



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









