










Redis的缓存击穿、穿透、雪崩,这几个概念是设计大流量接口时所需要考虑的问题,也是面试常问的Redis相关的基础知识,本篇捋一下这几个概念,做一个小结;
大家都知道,计算机的瓶颈之一就是IO,为了解决内存与磁盘速度不匹配的问题,产生了缓存;将一些热点数据(访问频繁、不会经常更新的数据)放在内存中(如Redis、本地缓存),随用随取,从而减少与磁盘的交互,如减少对DB频繁的查询压力,避免数据库在大量请求下挂掉;
需要注意的是,无论是缓存击穿还是穿透与雪崩,这里的条件都是指在高并发前提下,因为并发不高也没有必要去设计缓存了;
1. 缓存穿透
缓存穿透是指查询一个根本不存在的数据,缓存层和持久层都不会命中;导致用户每次请求该数据,都要去数据库中查询一遍,然后返回空;例如:
1. 正常用户请求,由于业务逻辑异常或脏数据,导致需要查询一个缓存中不存在的id,如已失效的活动id、已下架的商品id;
2. 恶意用户请求,伪造不存在的id发起请求,无论数据库和缓存都是不存在的;
缓存穿透将导致不存在的数据每次请求都要到持久层去查询,失去了使用缓存保护持久层DB的意义;如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至击垮数据库系统;
缓存穿透示意图:
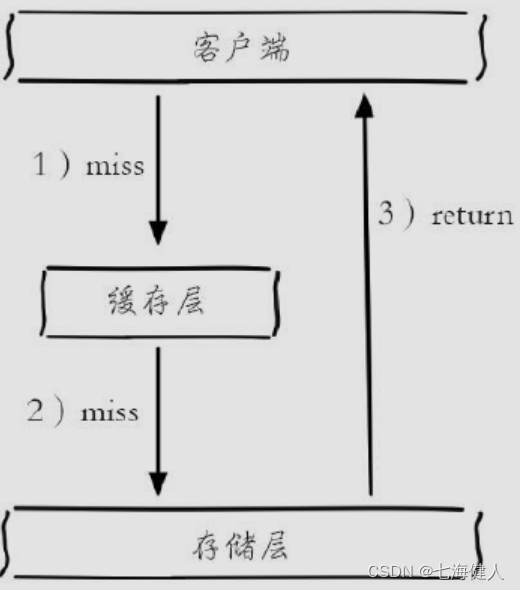
在日常工作中出于容错的考虑,如果从持久层查不到数据则不写入缓存层(优化方案是写入一个空值到缓存或使用布隆过滤器来过滤非法请求参数);
解决方案:
1.1 布隆过滤器拦截
在访问缓存之前,将有效的keys提前放入布隆过滤器中,当收到一个请求时先用布隆过滤器判断当前key否存在(一定概率误判),如果判断存在集合中(有效的请求,如商品id>0)再去请求缓存和DB;布隆过滤器可以用于检索一个元素是否在一个集合中,它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难;
关于布隆过滤器,可以参考我的文章《Redis——布隆过滤器》;
注意:实际情况下,我们很少用布隆过滤器解决缓存穿透问题!为什么呢?
除了误判率和删除困难问题,布隆过滤器最致命的问题是:如果数据库中的数据更新了,我们期望是同步更新布隆过滤器,但业务上我们不能做成事务,布隆过滤器的更新不能影响到正常业务流程,因此是异步更新布隆过滤器集合;而它跟数据库是两个数据源,那么就可能存在数据不一致的情况;对于某些业务来说,这个"不一致"的情况是无法接受的!
例如:用户购买B站大会员场景,支付成功后数据库中新增了1个会员用户,此时系统开启异步线程将用户同步到布隆过滤;但由于网络异常,同步失败了;而用户支付成功后立即回跳会员页,这时用户的"查询会员权益"的请求就过来了,由于布隆过滤器没有该key的数据,所以直接拒绝了该请求,提示用户"未开通会员",但这个用户明明已经成为了B站大会员,他的会员权益请求被拦截了;——于是,客诉来了,SQA找上了你,拉会复盘...
很显然,如果出现了这种正常用户被拦截了情况,有些业务是无法容忍的;所以,布隆过滤器要看实际业务场景再决定是否使用,它帮我们解决了缓存穿透问题,但同时引入了新的问题;
1.2 缓存空对象
上面使用布隆过滤器,虽说可以过滤掉很多不存在的用户id请求,但它除了增加系统的复杂度之外,会带来两个问题:
1. 布隆过滤器的误判率,导致不在集合中的元素被放行;
2. 如果新增用户信息,需要保证能实时同步到布隆过滤器,不然会有业务问题;
所以,通常情况下,我们很少用布隆过滤器解决缓存穿透问题;其实,还有另外一种更简单的方案,即缓存空值。
当缓存未命中,查询持久层也为空,可以将返回的空对象写到缓存中,这样下次请求该key时直接从缓存中查询返回空对象,请求不会落到持久层数据库;为了避免存储过多空对象,通常会给空对象设置一个过期时间;
缓存空对象的方案会有2个问题:
(1)value为null/空串不代表不占用内存空间,空值做了缓存,意味着缓存层中存了更多的keys,需要更多的内存空间,因此通常会给空对象设置一个较短的过期时间,让其自动剔除;尽管如此,在短时间内,有大量请求依然会产生较多的存放空值的keys,在过期时间内将占用一定空间;
(2)缓存层和存储层的数据会有一段时间窗口的不一致,例如过期时间设置为5分钟,如果此时DB新增/更新了这个数据,那此段时间就会出现缓存为NULL而DB层有值的情况;一般会在DB更新时通过异步线程更新缓存,如果是本地缓存则可以通过消息广播如Redis的发布订阅模式;
2. 缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞——用来扛高并发的缓存被"打穿"了;
系统中存在以下两个问题时需要引起注意:
- 当前key是一个热点key(例如一个秒杀活动信息),并发量非常大;
- 重建缓存不能在短时间完成,可能是一个长事务,例如复杂的SQL、多次IO、多个RPC等。
在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,DB被打挂了;并且,此时请求的响应往往会变慢(因为没走缓存),请求线程池也可能被占满;可见,危害还是很大的;
解决方案:
2.1 重建缓存时加分布式锁
实际上,缓存失效时,有一个线程去执行查询DB,并将数据刷到缓存即可;其他线程等待重建缓存的线程执行完,再重新从缓存中获取数据;由于是单个线程访问DB,DB的压力也不大,一般完成查询和刷入缓存的操作也是很快的;示意图如下:

微服务下,一般都是多节点应用,使用分布式锁保证重建缓存是单线程执行;
2.2 让缓存永不过期
这种方案的思想是让缓存永远的存在,因此理论上不存在缓存未命中导致DB层被击穿的问题;这里的"永不过期"有几种实现思路:
(1)从物理层面上(缓存存储),不设置过期时间,这种方式简单粗暴,但是当该缓存不再使用时,需要主动的删除;否则Redis中可能逐渐的堆积了一些这种"无效的"但永不过期的缓存,浪费空间;
(2)从功能层面上,可以将"到期时间"写在value中,当取出key对应的value时,如果发现即将到达过期时间,则可以立即去刷新这个缓存,像是"续期";当然,这种方式对于经常被访问的缓存key来说是较为有效的,因为缓存被频繁访问,因此取值value时,这个缓存往往是还未失效的,但如果这个缓存在在失效前,未被请求到,就会出现下次请求时未命中缓存的情况了;这种情况下,依然需要去查询DB重构缓存到Redis;
实际使用中,我的建议是,我们可以使用定时任务给指定key自动续期,比如说,当日top50的商品信息,设置的缓存过期时间是30分钟(可能更新,所以不需要太长),但有个定时任务每隔20分钟执行1次,自动更新缓存,重新设置过期时间为30分钟;
实际上,开发规范告诉我们使用Redis时,必须指定过期时间,防止在一些缓存在不被使用时,忘记删除从而占用Redis空间;
3. 缓存雪崩
由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因失效不可用,如Redis宕机、或者大量缓存由于超时时间相同在同一时间段失效(大批key失效/热点数据失效),大量请求直接到达DB存储层,DB压力过大导致系统雪崩。
雪崩,和击穿类似,不同的是击穿是某一个热点key某时刻失效,而雪崩是大量的热点key在一瞬间失效;
从批量缓存不可用的原因上分析,我们可以有以下解决思路:
3.1 保证缓存服务的可靠性
实际上,在经历过一些线上问题后,可以发现Redis并不像我们预期的那样可靠,向redis节点请求数据,至少有一层网络请求,因此可以采用多级缓存,本地JVM作为一级缓存,redis作为二级缓存,不同级别的缓存设置的超时时间不同,即使某级缓存过期了,也有其他级别缓存兜底;
使用本地缓存如GuavaCache、Caffeine,可以防止在redis集群异常时,也能防止大量请求打到DB,保证了缓存服务的可靠性;但是,如果要求本地缓存在不同服务节点是一致的,则需要分布式缓存同步机制来保障,如利用消息、ZK、Redis发布订阅等,会增加系统的复杂性;
3.2 适当选择服务降级
如果做了高可用架构,redis服务还是挂了,该怎么办呢?这时候,就需要做服务降级了,否则大量请求会打挂DB,导致整个服务都不可用,即对于自己做好高可用,对于整个服务做好业务隔离;
做服务降级还是要根据实际的业务场景来,如信息流场景,可以返回用户非实时的数据,保证用户至少能看到部分数据,避免"数据白页";而对于对数据准确性要求高的场景,那就只能返回"系统繁忙,请稍后重试"这种降级提示了;
例如,我们提前配置一些默认的兜底数据,可以是30min之前或1天前的数据;在缓存异常时自动切换读取旧数据,同时开启任务尝试查询缓存;当缓存恢复时,可以自动切换为读取缓存;是不是有点类似Hystrix的降级恢复呢?
3.3 防止大量缓存在同一时间点失效
缓存的过期时间用随机值,尽量让不同的key的过期时间不同(例如:定时任务新建大批量key,设置的过期时间相同);但有的时候,缓存的失效时间必须是相同的,如一个0点更新的活动,我们可以使用一个新的缓存,并通过缓存预热的方式提前将其提前刷入;
4. 缓存预热
缓存预热就是新功能上线后,将相关的缓存数据直接加载到缓存系统,这样就可以避免在用户请求的时候,先查询数据库,然后再将数据回写到缓存;这种场景一般是节日氛围素材、零点活动之类;
如果不进行预热, 那么Redis中没数据,到达0点后突然的一波高并发的用户请求,都会访问到数据库中,对数据库造成流量的压力;
缓存预热的操作方法
- 数据量不大的时候,工程启动的时候进行加载缓存动作;
- 数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
- 数据量太大的时候,优先保证热点数据进行提前加载到缓存;
5. 生产环境中我们使用缓存的一般方案
一下方案来自个人的开发经验,不一定完整和严谨,但可以参考;
(1)首先,可以使用定时任务更新每个key的value,如1天1次,而缓存的失效时间一般会大于执行定时任务的时间间隔,来保证刷新缓存任务异常时,我们留有一定时间去处理,防止此时大量的请求进来打挂DB;
(2)同时,当某个key对应的值在DB中发生更新时,我们在业务中会启一个异步线程去尝试把最新的值刷入Redis;
(3)使用二级缓存,优先使用本地缓存,其次使用redis,最后是DB;本地缓存的失效时间较短,小于redis缓存;未命中本地缓存时,尝试从redis获取并刷入本地缓存;当redis也未命中时,尝试从DB中获取返回,同时异步刷新到redis中,如果有并发场景,可以对这一步骤使用分布式锁,即单线程查询DB更新redis;
(4)此外,由于JVM中的内存空间有限,可以通过JVM之外的方式存储大量的缓存数据,如磁盘存储;由于磁盘IO相对缓存更慢,因此该方案中的磁盘缓存不会经常更新,即不去追求准确性,但是要保证可靠性,如APP的首页可以是几小时前的数据,但不能为白页;
(5)最后,如果使用了以上方式,还是担心请求会打挂DB,想要尽可能保护DB,则可以不查询DB, 只从缓存中获取数据,缓存失效或缓存服务异常时,直接返回空值;缓存降级一般是有损的操作,所以尽量减少降级对于业务的影响程度;
参考:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









