 Redis集群数据分布:从Hash到HashSlot算法解析
Redis集群数据分布:从Hash到HashSlot算法解析







 本文介绍了Redis集群中数据分布的三种算法:Hash、一致性Hash和RedisCluster的哈希槽算法。Hash算法简单但扩展性差,一致性Hash解决了部分问题但可能导致热点节点。RedisCluster的哈希槽算法通过16384个槽位实现数据分布,允许节点动态增减而无需大规模数据迁移,同时支持redishashtag实现多key映射同一槽。Redis选择哈希槽而非一致性Hash,是因为槽位可手动分配,利于数据分布控制。
本文介绍了Redis集群中数据分布的三种算法:Hash、一致性Hash和RedisCluster的哈希槽算法。Hash算法简单但扩展性差,一致性Hash解决了部分问题但可能导致热点节点。RedisCluster的哈希槽算法通过16384个槽位实现数据分布,允许节点动态增减而无需大规模数据迁移,同时支持redishashtag实现多key映射同一槽。Redis选择哈希槽而非一致性Hash,是因为槽位可手动分配,利于数据分布控制。
实现redis集群模式下,在存在多个master节点的时候,数据如何分布在这些节点上去;为了解决这个问题,就引入了redis数据分布的算法;数据分布的算法有一个演变过程,即hash算法、一致性hash算法、redis cluster哈希槽算法;本篇介绍这几种Redis集群的数据分片算法;
1. 最简单数据分布算法——hash算法
算法步骤:
- 一个key的请求过来后,计算这个key的hash值(hash函数计算出来的是正整数),然后对节点数3(如图,节点数为3)取模;
- 取模后的值是在0~2之间(就是对3求余数,余数只会是0、1、2),小于节点的数量3;
- 根据取模后的值(0-2)将数据打到对应的master的node(node1-node3)上去;
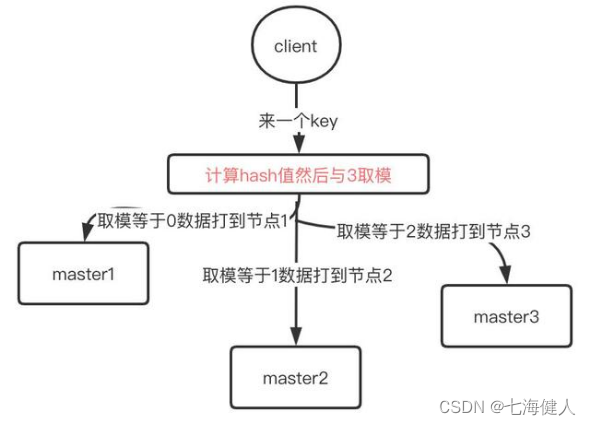
将hash算法设计的离散型很好时,各个key的数据就能均匀散落在各个node上;但是hash算法的弊端也是很明显的,如下:
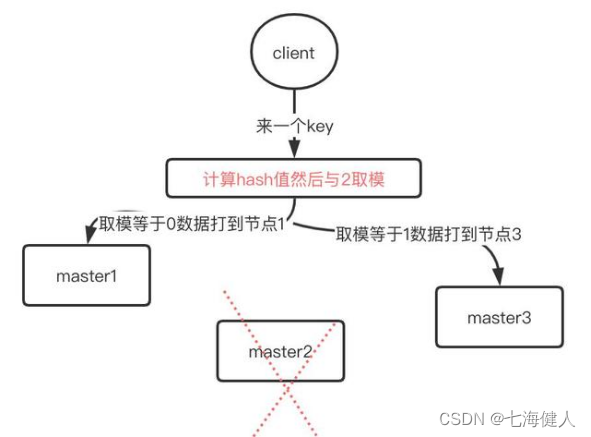
当原本3个master中的第二个节点master2挂掉,此时,如果按照3个master去路由key,当key落在master2时,将无法查询和写入;如果按照2个master去取模然后尝试去获取数据,这会导致大部分请求key几乎无法落到原本有数据的正确的节点上,可能导致大量的流量会涌入到数据库中,在高并发的场景会直接打挂DB;
存在问题:
hash算法最大的问题就是扩展性很差,集群模式下,节点的增减都是可能发生的,当节点数发生变化时,都需要重新计算每个key落在哪个节点,并且做数据移动,这个成本是不可接受的;
2. hash算法的改进版——一致性hash算法
一致性hash算法,维护了一个如下图所示的圆环,其中key和节点node都在圆环上;每一个key都可以通过hash算法转化为一个32位的二进制数,也就对应着环上的某个位置,同样的,每一个缓存节点node也遵循同样的hash算法,比如利用node的IP或者主机名取hash,映射到环形空间当中的某个位置;
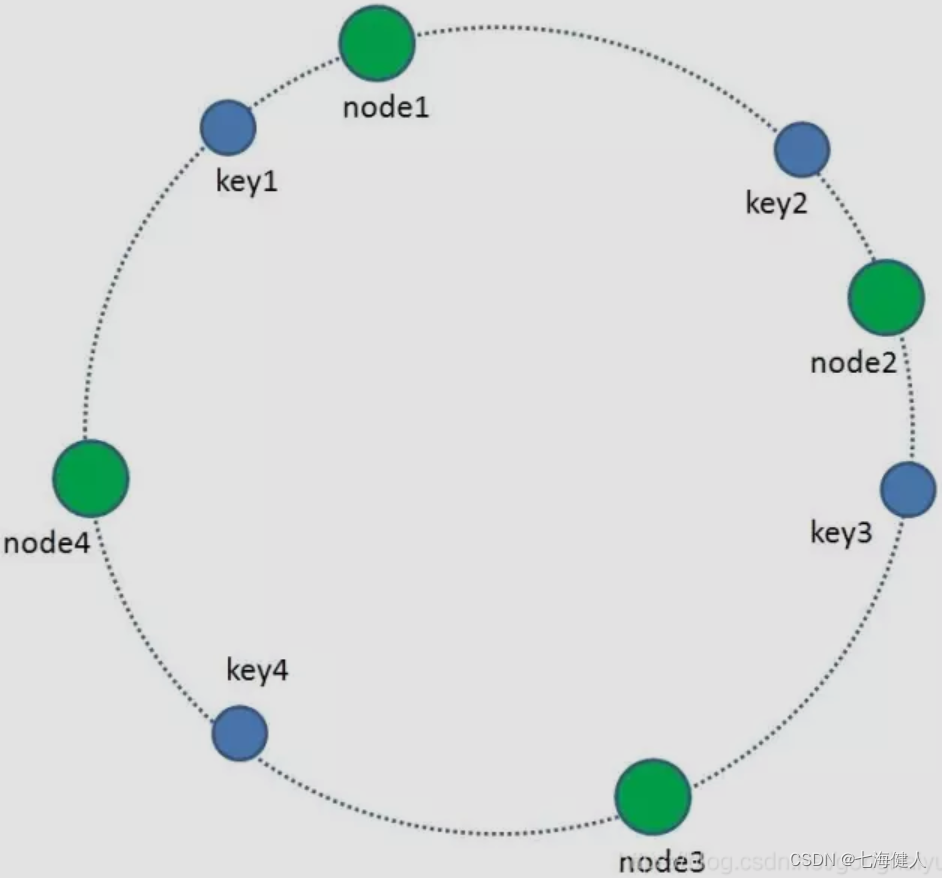
如何让key和缓存节点对应起来呢?——很简单,每一个key的顺时针方向最近节点,就是key所归属的缓存节点node,例如图中key1存储于node1,key2,key3存储于node3,key4存储于node4;
当有节点增加或者移除时,一致性哈希的优势就显现出来了;当缓存集群的节点有所增加,如图所示,有3个node,现在node1和node2之间增加node4,则key2顺时针落到了node4,其他数据均无影响,即只影响新节点和逆时针找到的第一个节点之间的key;删除节点时,同理;这部分受影响的key会被"迁移"到下个节点;
注意,这里的"迁移"并不是指节点数量变化时,数据的自动迁移,而仅仅是更新了从key到node的映射关系而已;也就是新的请求过来时,对于这个被"迁移"的key,它的数据在新的node上肯定是没有的,在缓存未命中时才会刷新缓存到新的节点上;
因此,例如有3个节点,此时一个节点宕机,则会有0-33%的缓存失效(在新节点上找不到),即可能3分之一的流量会直接涌入到MySQL数据库中重新查询一次,再刷新到新的节点上;并且,当新增节点时,也不会立即缓解所有原有节点的压力,而是同样的要走一遍刷缓存的过程;
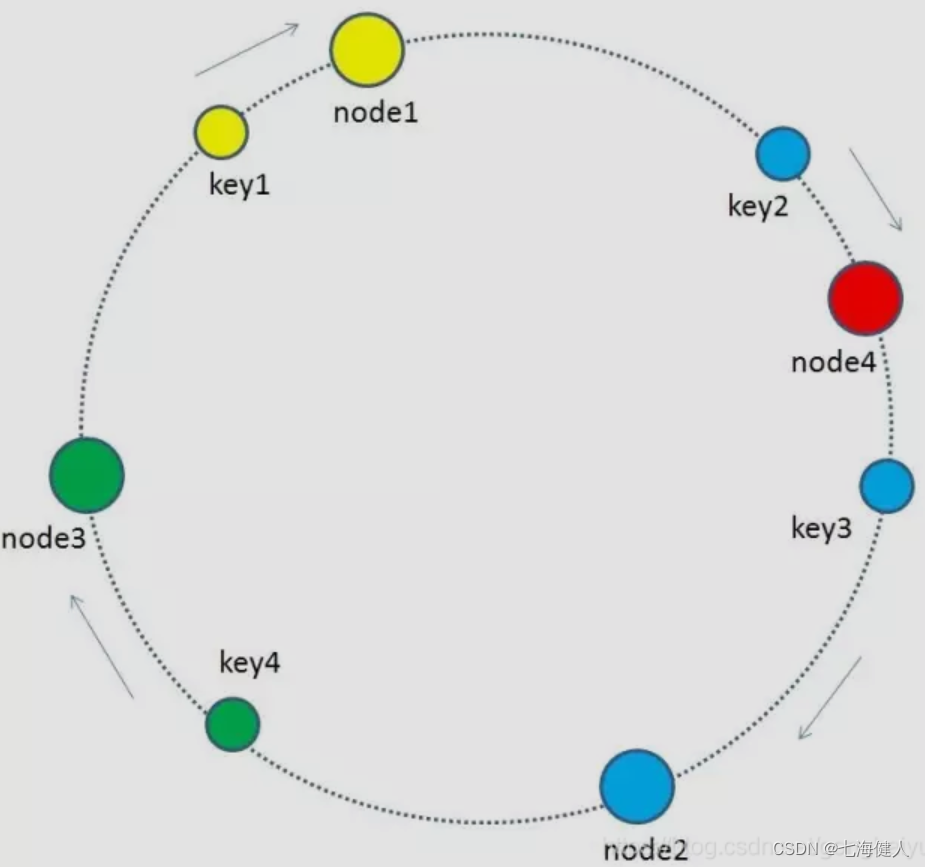
存在问题:
一致性hash算法,可能导致某个hash区间内的key会特别多,也就是不同节点上的key并非均匀分布,可能存在大量的key的请求都落到同一个master内,造成master的热key问题;
解决思路:
给每个master node均匀分布虚拟节点,如node1-1、node1-2,虚拟节点的个数按照节点机器的性能比例划分,性能好的机器虚拟节点更多,从而实现负载均衡;这样的话,在每个hash区间内的数据都会均匀的分布到不同的虚拟节点内;
3. redis cluster的hash slot哈希槽算法
“槽”的英文翻译成slot;在redis集群中,哈希槽是虚拟的很小粒度的存储分区,通过hash算法将数据存放对应的槽里面,而槽又被分配给了每个redis节点;在redis集群中,一共会虚拟出16384个槽位来存储数据集,这个数字是固定的,这16384个槽位分别映射到各个节点上;关于槽的概念,可以类比为我们在windows下对硬盘存储的分区,节点就对应"我的电脑"中的盘符(C/D/E/F/G...);
例如,假设主节点的数量为3,将16384个槽位按照用户自己的规则手动去分配这3个节点,每个节点大约得到5460个槽。(用户自定义分配的原因在于有些机器的配置高,有些机器的配置低,配置高的可以分配多一点槽位,配置低的可以分配少一点槽位)
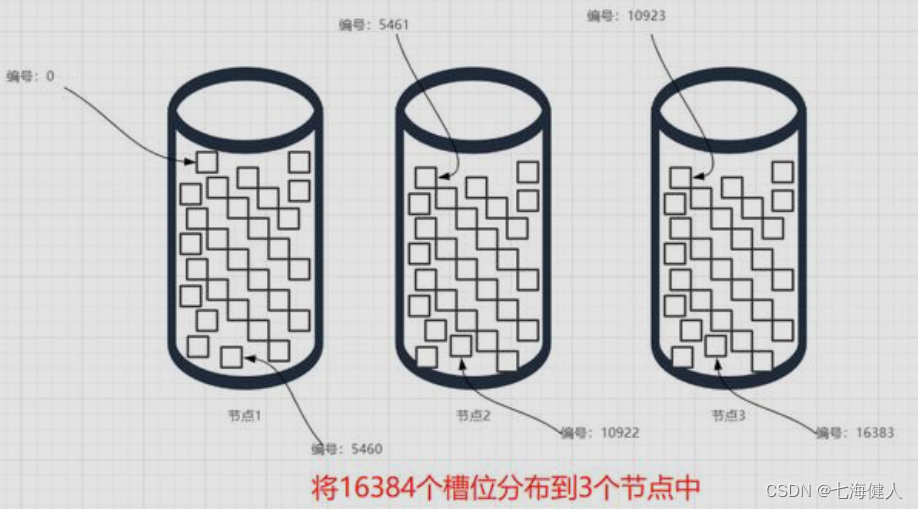
既然每个节点上分配了哪些槽式自定义配置的,那么如何计算某个key的槽标号能?——很简单,对key进行CRC16哈希运算得到一个值,然后对16384取模,假设CRC16("test_key")%16384=3345,因为3345在区间0-5460之间,所以test_key数据写入到节点1里面;
哈希槽算法下,当节点数变更(如新增节点或某节点宕机)时怎么办?
先介绍下redis集群相关的知识,在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379,另外一个就是加10000的端口号,比如16379,16379端口号是用来进行节点间通信的,也就是cluster bus集群总线,用来进行故障检测,配置更新,故障转移授权;
正因为key找的是hash slot标号而不是节点,因此有节点变更时,其他节点不会收到影响,因为节点上分配的哈希槽没有变化;在移动slot的时间内还是会有找不到缓存走数据库的情况,只不过移动hash slot的成本是非常低的,时间比较短;
但一定要注意的是,对于槽位的转移和分派,Redis集群是不会自动进行的,而是需要人工配置的;所以Redis集群的高可用是依赖于节点的主从复制与主从间的自动故障转移;
如有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用;然而如果在集群创建的时候,我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了;不过当B和B1 都失败后,集群是不可用的;
为什么redis集群不采用一致性哈希算法而是使用哈希槽算法呢?
一致性哈希的节点分布基于圆环,无法很好的很直观的手动控制数据分布;而redis集群的槽位空间是可以用户手动自定义分配的,类似于windows磁盘分区的概念,每个盘符可以手动控制存储空间的大小,很直观和方便;
4. 为什么Redis集群设计为16384个槽?
理论上CRC16算法可以得到2^16个数值,其数值范围在0-65535之间,也就是最多可以有65535个虚拟槽,取模运算key的时候,应该是CRC(key)%65535;但是却设计为crc16(key)%16384,原因是作者在设计的时候做了空间上的权衡,觉得节点最多不可能超过1000个,节点数量越多,节点间通信的成本越大(节点间通信的消息体内容越大,具体是消息头中携带的其他节点信息越大),为了保证节点之间通信效率,权衡之下所以采用了2^14个哈希槽;
5. 将多个key映射到同一个slot——Redis hash tag
默认下,redis在计算key的槽时,会对整个key做CRC16哈希取值,但是其API也开放了功能——redis hashtag,即通过tag,对key中指定的一段做CRC16哈希取值,这样可以让不同的key落到相同的哈希槽上;
通过redis hashtag源码解析可知,仅对key中{...}里的部分参与hash,如果有多个花括号,从左向右,取第一个花括号中的内容进行hash;若第一个花括号中内容为空如:a{}c{d},则整个key参与hash;达到的效果就是,相同的hashtag被分配到相同的槽,即相同的redis节点;不过滥用hash tag可能导致节点上的key数量分布不均匀;
参考:


















 5330
5330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









