







什么是Sunday算法
- Sunday算法是是 Daniel M.Sunday 于 1990 年提出的一个字符串匹配算法,是由BM算法演变而来,有兴趣的盆友可以了解一下BM算法,但是不了解也不影响我们今天对Sunday算法的学习
- 说到字符串匹配算法,老规矩我们必须分清楚主串和模式串的概念,比如要在a=‘abbcf’,b=‘sjldfsdabbcfdsfs’,要在b中找a的,则a为模式串,b为主串
- Sunday 算法 与 KMP 算法 一样是从前往后匹配,在匹配失败时关注的是主串中参加匹配的最末位字符的下一位字符。
如果该字符没有在模式串中出现则直接跳过,即移动位数 = 模式串长度 + 1。
否则,其移动位数 = 模式串长度 - 该字符最右出现的位置(以0开始) = 模式串中该字符最右出现的位置到尾部的距离 + 1。
举个例子来理解一下它的操作过程。
假定现在要在主串substring searching xiaowu 中查找模式串 search 。
- 刚开始时,把模式串与文本串左边对齐:


- 结果发现在第 2 个字符处发现不匹配,不匹配时关注文本串中参加匹配的最末位字符的下一位字符,即绿色的字符 i,因为模式串 search 中并不存在 i,所以模式串直接跳过一大片,向右移动位数 = 匹配串长度 + 1 = 6 + 1 = 7,从 i 之后的那个字符(即字符 n)开始下一步的匹配,如下图:

- 结果第一个字符就不匹配,再看文本串中参加匹配的最末位字符的下一位字符,是 ‘r’ ,它出现在模式串中的倒数第 3 位,于是把模式串向右移动 3 位( r 到模式串末尾的距离 + 1 = 2 + 1 =3),使两个 ‘r’ 对齐,如下:

- 匹配成功
基于python的Sunday算法的实现
- 只找出第一次匹配到的字符串的第一个下标
def sunday_match_str(main_str, find_str):
"""
:param main_str: 主串
:param find_str: 模式串
:return: 返回第一个匹配到模式串中第一个字符在主串中的下标
"""
m, f = 0, 0
m_len, f_len = len(main_str), len(find_str)
while m < m_len:
if main_str[m] == find_str[f]:
m, f = m + 1, f + 1
if f == f_len:
return m - f_len # 此时找到了第一个匹配到的下标
continue
else:
flag = m - f + f_len
if flag > m_len - 1: # main_str下标越界,没有找到匹配的串
return -1
check_exits = find_str.rfind(main_str[flag])
if check_exits != -1: # 在find_str中有匹配
jump = f_len - check_exits # 移动的步长
m, f = m - f + jump, 0
else: # 在find_str中无匹配
jump = f_len + 1 # 移动的步长
m, f = m - f + jump, 0
else:
return -1
main_st = 'substring searching xiaowu'
find_st = 'searching'
print(sunday_match_str('baa', 'aa'))
- 找出所有匹配到的字符串的第一个下标:
比如:
- main_st=‘aaabaaabaaaabaaaaab’,find_st=‘aa’
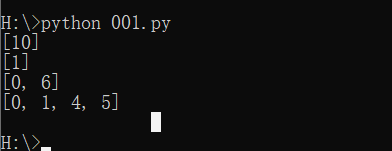
对应的结果为:[0, 1, 4, 5, 8, 9, 10, 13, 14, 15, 16] - main_st=‘foobarfoobar’,find_st=‘foobar’
对应的结果为:[0, 6]
def m_f_change(f_len, m, f, check_exits):
if check_exits != -1:
jump = f_len - check_exits
m, f = m - f + jump, 0
else:
jump = f_len + 1
m, f = m - f + jump, 0
return m, f
def find_str_begin(main_str, find_str):
m, f = 0, 0
m_len, f_len, result = len(main_str), len(find_str), list()
while m < m_len:
if main_str[m] == find_str[f]:
m, f = m + 1, f + 1
if f == f_len:
result.append(m - f_len)
flag = m - f + f_len
if flag > m_len - 1:
return result
check_exits = find_str.rfind(main_str[flag])
m, f = m_f_change(f_len,m,f,check_exits)
continue
else:
flag = m - f + f_len
if flag > m_len - 1:
return result
check_exits = find_str.rfind(main_str[flag])
m,f=m_f_change(f_len,m,f,check_exits)
else:
return result
print(find_str_begin('substring searching xiaowu','searching'))
print(find_str_begin('baa','aa'))
print(find_str_begin('foobarfoobar', 'foobar'))
print(find_str_begin('aaabaaabb','aa'))















 1180
1180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









