







相信大家对如下的类别都很熟悉,很多网站都有类似如下的功能,“商品推荐”,”猜你喜欢“。
在实体店中我们有导购来为我们服务,在网络上我们需要同样的一种替代物,如果简简单单的在数据库里面去捞,去比较,几乎是完成不了的,这时我们就需要一种协同推荐算法,来高效的推荐浏览者喜欢的商品。

一:概念
协同过滤算法(Collaborative Filtering),SlopeOne的思想很简单,就是用均值化的思想来掩盖个体的打分差异,举个例子说明一下:
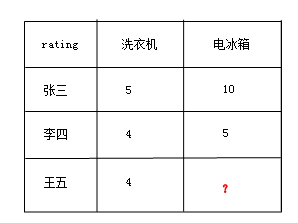
在这个图中,系统该如何计算“王五“对”电冰箱“的打分值呢?刚才我们也说了,slopeone是采用均值化的思想,也就是:R王五 =4-{[(5-10)+(4-5)]/2}=7 。
二:公式
下面我们看看多于两项的商品,如何计算打分值。
rb = (n * (ra - R(A->B)) + m * (rc - R(C->B)))/(m+n)
注意:
a,b,c 代表“商品”。
ra 代表“商品的打分值”。
ra->b 代表“A组到B组的平均差(均值化)”。
m,n 代表人数。三:举例
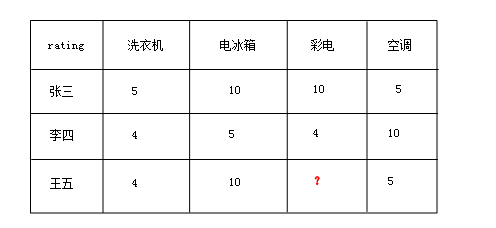
根据公式,我们来算一下。
r王五 = (2 * (4 - R(洗衣机->彩电)) + 2 * (10 - R(电冰箱->彩电))+ 2 * (5 - R(空调->彩电)))/(2+2+2)=6.3是的,slopeOne就是这么简单,实战效果非常不错。
四:编码
核心代码:SlopeOne类
参考了网络上的例子,将二维矩阵做成线性表,有效的降低了空间复杂度。
package com.xm.math.slopeone;
import java.util.*;
/**
* Created by xuming on 2016/6/20.
* Slope One 算法
*/
public class SlopeOne {
/// <summary>
/// 评分系统
/// </summary>
public static Map<Integer, Product> dicRatingSystem = new HashMap<>();
public Map<String, Rating> dic_Martix = new HashMap<>();
public HashSet<Integer> hash_items = new HashSet<Integer>();
/// <summary>
/// 接收一个用户的打分记录
/// </summary>
/// <param name="userRatings"></param>
public void AddUserRatings(HashMap<Integer, List<Product>> userRatings) {
for (Map.Entry<Integer, List<Product>> user1 : userRatings.entrySet()) {
List<Product> value = user1.getValue();
for (Product item1 : value) {
//该产品的编号(具有唯一性)
int item1Id = item1.ProductID;
//该项目的评分
float item1Rating = item1.Score;
//将产品编号字存放在hash表中
hash_items.add(item1.ProductID);
for (Map.Entry<Integer, List<Product>> user2 : userRatings.entrySet()) {
List<Product> value2 = user2.getValue();
for (Product item2 : value2) {
//过滤掉同名的项目
if (item2.ProductID <= item1Id)
continue;
//该产品的名字
int item2Id = item2.ProductID;
//该项目的评分
float item2Rating = item2.Score;
Rating ratingDiff;
//用表的形式构建矩阵
String key = Tools.GetKey(item1Id, item2Id);
//将俩俩 Item 的差值 存放到 Rating 中
if (dic_Martix.keySet().contains(key))
ratingDiff = dic_Martix.get(key);
else {
ratingDiff = new Rating();
dic_Martix.put(key, ratingDiff);
}
//方便以后以后userrating的编辑操作,(add)
if (!ratingDiff.hash_user.contains(user1.getKey())) {
//value保存差值
ratingDiff.Value += item1Rating - item2Rating;
//说明计算过一次
ratingDiff.Freq += 1;
}
//记录操作人的ID,方便以后再次添加评分
ratingDiff.hash_user.add(user1.getKey());
}
}
}
}
}
/// <summary>
/// 根据矩阵的值,预测出该Rating中的值
/// </summary>
/// <param name="userRatings"></param>
/// <returns></returns>
public HashMap<Integer, Float> Predict(List<Product> userRatings) {
HashMap<Integer, Float> predictions = new HashMap<Integer, Float>();
List<Integer> productIDs = new ArrayList<Integer>();
userRatings.forEach(i -> productIDs.add(i.ProductID));//lambda
//循环遍历_Items中所有的Items
for (Integer itemId : this.hash_items) {
//过滤掉不需要计算的产品编号
if (productIDs.contains(itemId))
continue;
Rating itemRating = new Rating();
// 内层遍历userRatings
for (Product userRating : userRatings) {
if (userRating.ProductID == itemId)
continue;
int inputItemId = userRating.ProductID;
//获取该key对应项目的两组AVG的值
String key = Tools.GetKey(itemId, inputItemId);
if (dic_Martix.keySet().contains(key)) {
Rating diff = dic_Martix.get(key);
//关键点:运用公式求解(这边为了节省空间,对角线两侧的值呈现奇函数的特性)
itemRating.Value += diff.Freq * (userRating.Score + diff.AverageValue * ((itemId < inputItemId) ? 1 : -1));
//关键点:运用公式求解 累计每两组的人数
itemRating.Freq += diff.Freq;
}
}
predictions.put(itemId, itemRating.AverageValue=(itemRating.Value/itemRating.Freq));
}
return predictions;
}
}
具体代码见我的github。
五:结果
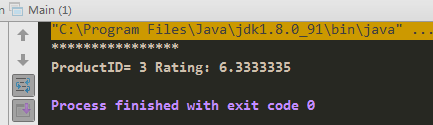
六:扩展
相似性计算
我尽量不使用复杂的数学公式,一是怕大家看不懂,难理解,二是公式不好画,太麻烦了。
所谓计算相似度,有两个比较经典的算法
- Jaccard算法,就是交集除以并集,详细可以看看这篇文章。
- 余弦距离相似性算法,这个算法应用很广,一般用来计算向量间的相似度,具体公式大家google一下吧,或者看看这里
- 各种其他算法,比如欧氏距离算法等等。
不管使用Jaccard还是用余弦算法,本质上需要做的还是求两个向量的相似程度,使用哪种算法完全取决于现实情况。















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









