







排序算法是工程中最常见的算法之一,这里我通过个人理解讲述常见的排序算法。常见的排序算法有:冒泡排序,选择排序,快速排序等,这里仅对这三种方法进行解释并实现。
冒泡排序
定义
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序(如从大到小、首字母从A到Z)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素列已经排序完成。这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),故名“冒泡排序”。
算法原理
冒泡排序算法的原理如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
冒泡排序算法的的最大次数为: ( n − 1 ) + ( n − 2 ) + . . . + 2 + 1 = ( n − 1 ) n 2 = 1 2 ( n 2 − n ) (n-1)+(n-2)+...+2+1=\frac{(n-1)n}{2}=\frac{1}{2}(n^2-n) (n−1)+(n−2)+...+2+1=2(n−1)n=21(n2−n),所以时间复杂度为: O ( n 2 ) O(n^2) O(n2)
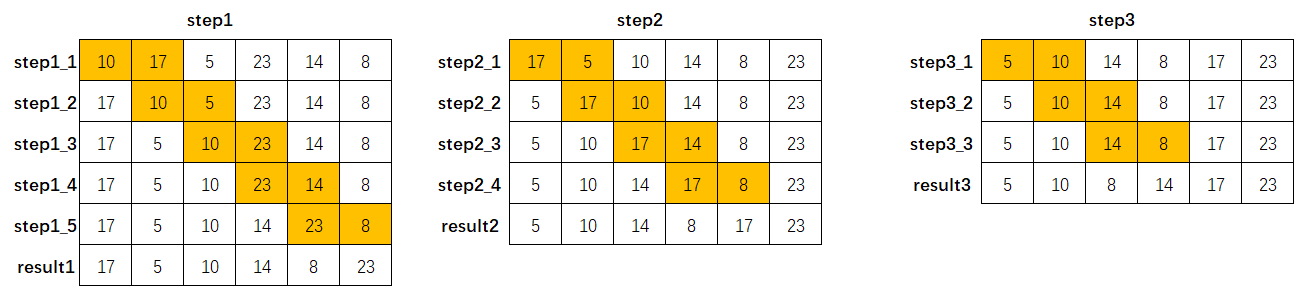
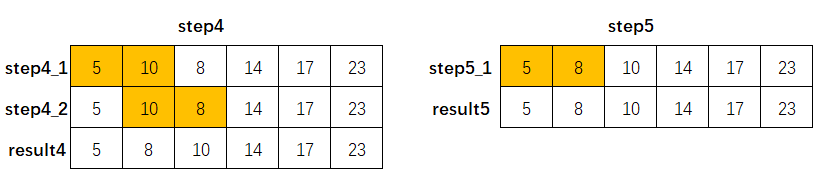
图解示例
这里以序列[10, 3, 5, 23, 14, 8]为例,排序过程下图所示:
代码实现
# 冒泡排序
def bubble_sort(pre_list):
for i in range(len(pre_list)-1):
flag = True # 如果flag为True,说明序列内部已经排序完毕
for j in range(len(pre_list)-i-1):
if pre_list[j] > pre_list[j+1]:
temp = pre_list[j+1]
pre_list[j+1] = pre_list[j]
pre_list[j] = temp
flag = False
if flag:
break
return pre_list
选择排序
定义
选择排序(Selection sort)是一种简单直观的排序算法,简而言之就是从每一次都选出最小的。 选择排序是不稳定的排序方法,多个相同的值的相对位置也许会在算法结束时产生变动。
算法原理
它的工作原理是:
- 每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置;
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾;
- 以此类推,直到全部待排序的数据元素排完。
选择排序算法的操作次数恒定为: ( n − 1 ) + ( n − 2 ) + . . . + 2 + 1 = ( n − 1 ) n 2 = 1 2 ( n 2 − n ) (n-1)+(n-2)+...+2+1=\frac{(n-1)n}{2}=\frac{1}{2}(n^2-n) (n−1)+(n−2)+...+2+1=2(n−1)n=21(n2−n),选择排序的时间复杂度为: O ( n 2 ) O(n^2) O(n2)。但是相比较冒泡排序来说,这里的次数是比较次数,比较操作比交换操作的时间更短,所以选择排序比冒泡排序更好。
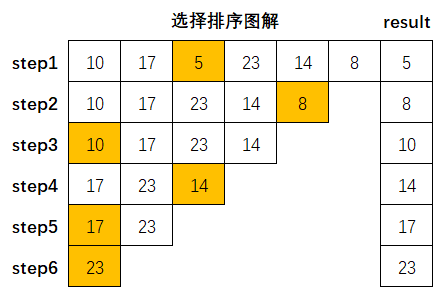
图解示例
代码实现
# 从序列中获取最小值,并返回最小值对应的索引
def find_smallest(pre_list):
smallest = pre_list[0]
smallest_index = 0
for i in range(1, len(pre_list)):
if smallest > pre_list[i]:
smallest = pre_list[i]
smallest_index = i
return smallest_index
def selection_sort(pre_list):
new_list = []
for i in range(len(pre_list)):
# 从新的序列中选择最小的索引
smallest_index = find_smallest(pre_list)
# 从当前序列中删除最小索引对应的值,pop函数返回被删除的值
smallest = pre_list.pop(smallest_index)
new_list.append(smallest)
return new_list
快速排序
定义
快速排序(Quicksort)是对冒泡排序的一种改进。通过一次排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。,快速排序不是一种稳定的排序算法,多个相同的值的相对位置也许会在算法结束时产生变动。
算法原理
假设需要排序的序列是A[0]……A[N-1]
- 任意选取一个数据(通常选用数组的第一个数)作为关键数据;
- 将所有比它小的数都放到它左边,所有比它大的数都放到它右边,这个过程称为一趟快速排序。
- 将 2 中的左右两个序列重复 1, 2 的步骤,知道序列中数量为1为止。
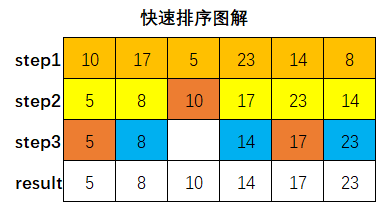
图解示例
代码实现
# 快速排序
def quick_sort(pre_list):
if len(pre_list) < 2:
return pre_list
pivot = pre_list[0]
less = [i for i in pre_list[1:] if i <= pivot]
greater = [i for i in pre_list[1:] if i > pivot]
return quick_sort(less) + [pivot] + quick_sort(geater)















 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









